 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Offline Data in Linear Latent Bandits
May 27, 2024Sequential decision-making domains such as recommender systems, healthcare and education often have unobserved heterogeneity in the population that can be modeled using latent bandits $-$ a framework where an unobserved latent state determines the model for a trajectory. While the latent bandit framework is compelling, the extent of its generality is unclear. We first address this by establishing a de Finetti theorem for decision processes, and show that $\textit{every}$ exchangeable and coherent stateless decision process is a latent bandit. The latent bandit framework lends itself particularly well to online learning with offline datasets, a problem of growing interest in sequential decision-making. One can leverage offline latent bandit data to learn a complex model for each latent state, so that an agent can simply learn the latent state online to act optimally. We focus on a linear model for a latent bandit with $d_A$-dimensional actions, where the latent states lie in an unknown $d_K$-dimensional subspace for $d_K \ll d_A$. We present SOLD, a novel principled method to learn this subspace from short offline trajectories with guarantees. We then provide two methods to leverage this subspace online: LOCAL-UCB and ProBALL-UCB. We demonstrate that LOCAL-UCB enjoys $\tilde O(\min(d_A\sqrt{T}, d_K\sqrt{T}(1+\sqrt{d_AT/d_KN})))$ regret guarantees, where the effective dimension is lower when the size $N$ of the offline dataset is larger. ProBALL-UCB enjoys a slightly weaker guarantee, but is more practical and computationally efficient. Finally, we establish the efficacy of our methods using experiments on both synthetic data and real-life movie recommendation data from MovieLens.
A Framework for Partially Observed Reward-States in RLHF
Feb 05, 2024The study of reinforcement learning from human feedback (RLHF) has gained prominence in recent years due to its role in the development of LLMs. Neuroscience research shows that human responses to stimuli are known to depend on partially-observed "internal states." Unfortunately current models of RLHF do not take take this into consideration. Moreover most RLHF models do not account for intermediate feedback, which is gaining importance in empirical work and can help improve both sample complexity and alignment. To address these limitations, we model RLHF as reinforcement learning with partially observed reward-states (PORRL). We show reductions from the the two dominant forms of human feedback in RLHF - cardinal and dueling feedback to PORRL. For cardinal feedback, we develop generic statistically efficient algorithms and instantiate them to present POR-UCRL and POR-UCBVI. For dueling feedback, we show that a naive reduction to cardinal feedback fails to achieve sublinear dueling regret. We then present the first explicit reduction that converts guarantees for cardinal regret to dueling regret. We show that our models and guarantees in both settings generalize and extend existing ones. Finally, we identify a recursive structure on our model that could improve the statistical and computational tractability of PORRL, giving examples from past work on RLHF as well as learning perfect reward machines, which PORRL subsumes.
Generalization Error without Independence: Denoising, Linear Regression, and Transfer Learning
May 26, 2023Studying the generalization abilities of linear models with real data is a central question in statistical learning. While there exist a limited number of prior important works (Loureiro et al. (2021A, 2021B), Wei et al. 2022) that do validate theoretical work with real data, these works have limitations due to technical assumptions. These assumptions include having a well-conditioned covariance matrix and having independent and identically distributed data. These assumptions are not necessarily valid for real data. Additionally, prior works that do address distributional shifts usually make technical assumptions on the joint distribution of the train and test data (Tripuraneni et al. 2021, Wu and Xu 2020), and do not test on real data. In an attempt to address these issues and better model real data, we look at data that is not I.I.D. but has a low-rank structure. Further, we address distributional shift by decoupling assumptions on the training and test distribution. We provide analytical formulas for the generalization error of the denoising problem that are asymptotically exact. These are used to derive theoretical results for linear regression, data augmentation, principal component regression, and transfer learning. We validate all of our theoretical results on real data and have a low relative mean squared error of around 1% between the empirical risk and our estimated risk.
Offline Policy Evaluation and Optimization under Confounding
Dec 01, 2022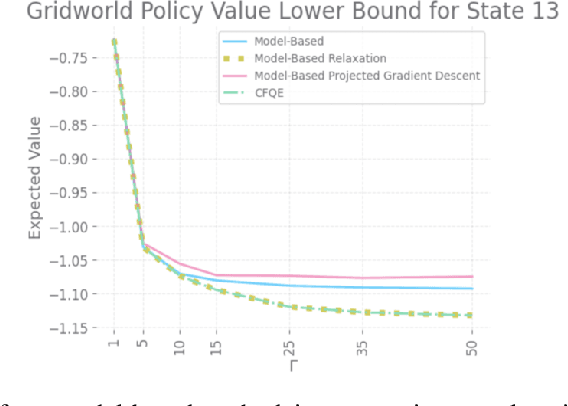
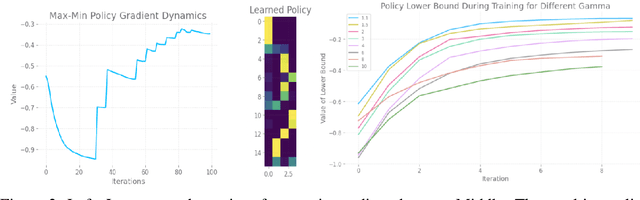
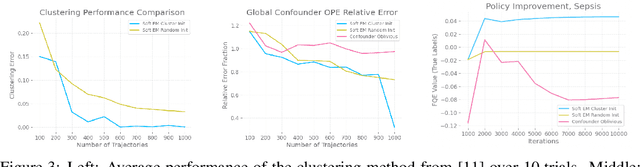
With a few exceptions, work in offline reinforcement learning (RL) has so far assumed that there is no confounding. In a classical regression setting, confounders introduce omitted variable bias and inhibit the identification of causal effects. In offline RL, they prevent the identification of a policy's value, and therefore make it impossible to perform policy improvement. Using conventional methods in offline RL in the presence of confounding can therefore not only lead to poor decisions and poor policies, but can also have disastrous effects in applications such as healthcare and education. We provide approaches for both off-policy evaluation (OPE) and local policy optimization in the settings of i.i.d. and global confounders. Theoretical and empirical results confirm the validity and viability of these methods.
Learning Mixtures of Markov Chains and MDPs
Nov 17, 2022



We present an algorithm for use in learning mixtures of both Markov chains (MCs) and Markov decision processes (offline latent MDPs) from trajectories, with roots dating back to the work of Vempala and Wang. This amounts to handling Markov chains with optional control input. The method is modular in nature and amounts to (1) a subspace estimation step, (2) spectral clustering of trajectories, and (3) a few iterations of the EM algorithm. We provide end-to-end performance guarantees where we only explicitly require the number of trajectories to be linear in states and the trajectory length to be linear in mixing time. Experimental results suggest it outperforms both EM (95.4% on average) and a previous method by Gupta et al. (54.1%), obtaining 100% permuted accuracy on an 8x8 gridworld.