 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Random Oblique Projections for Subsampled OLS and Fast CUR in High Dimensions
May 24, 2026Random sampling is a fundamental tool in modern machine learning and numerical linear algebra for reducing the computational cost of large-scale matrix problems. Existing analyses, however, rely primarily on subspace embedding guarantees, which do not precisely characterize the statistical bias of nonlinear random oblique projections induced by sampling, which arises ubiquitously in subsampled least squares and fast low-rank approximation methods. Because (pseudo)inversion is nonlinear, these random oblique projections can be systematically biased even when the underlying sketch is unbiased, thereby introducing hidden bias into downstream least squares and low-rank approximation solutions. In this work, we develop a unified non-asymptotic theory for random oblique projections in high dimensions. We show that standard random sampling schemes generally induce a systematic statistical bias overlooked by classical subspace embedding-style analyses, and we propose a principled debiasing framework to correct it. We illustrate the power of the theory through two canonical applications. For subsampled least squares, we obtain sharp bias--variance characterizations, reveal previously unrecognized statistical suboptimality in widely used sampling schemes, and identify when debiasing yields provable improvements. For fast CUR decomposition, we develop a debiased approach with improved approximation accuracy. Numerical experiments further validate our theoretical findings.
Perfect Parallelization in Mini-Batch SGD with Classical Momentum Acceleration
May 18, 2026Accelerating stochastic gradient methods with classical momentum schemes, such as Polyak's heavy ball, has proven highly successful in training large-scale machine learning models, particularly when combined with the hardware acceleration of large mini-batch computations. Yet, the effect of classical momentum on stochastic mini-batch optimization has been poorly understood theoretically, with prior works requiring strong noise assumptions and extremely large mini-batches. In this work, we develop a general theory of stochastic momentum acceleration for optimizing over quadratics in the interpolation regime, a popular abstraction for studying deep learning dynamics which also includes classical methods such as randomized Kaczmarz and coordinate descent. Our framework encompasses both heavy ball and Nesterov-style momentum, allows for arbitrary mini-batch sizes, and makes minimal assumptions on the stochastic noise. In particular, we show that acceleration from classical momentum is directly proportional to the gradient mini-batch size (up to a natural saturation point), thereby enabling perfect parallelization of mini-batch computations. Our theory also provides a simple choice for the momentum parameter, which is shown to be effective empirically.
Accelerating Power Method with Fast Sketching for Stronger Low-Rank Approximation
May 10, 2026The power method is one of the most fundamental tools for extracting top principal components from data through low-rank matrix approximation. Yet, when the target rank is large, the cost of matrix multiplication associated with this procedure becomes a major bottleneck. We develop an algorithmic and theoretical framework for accelerating the power method using fast sketching, which is a popular paradigm in randomized linear algebra. Our framework leads to simple and provably efficient methods for singular value decomposition, low-rank factorization, and Nyström approximation, which attain strong numerical performance on benchmark problems. The key novelty in our analysis is the use of regularized spectral approximation, a property of fast sketching methods which proves more flexible in generalizing power method guarantees than traditional arguments.
Well-Conditioned Oblivious Perturbations in Linear Space
Apr 25, 2026Perturbing a deterministic $n$-dimensional matrix with small Gaussian noise is a cornerstone of smoothed analysis of algorithms [Spielman and Teng, JACM 2004], as it reduces the condition number of the input to $O(n)$, and with it the complexity of many matrix algorithms. However, when deployed algorithmically, these perturbations are expensive due to the cost of generating and storing $n^2$ Gaussian random variables. We propose a perturbation that requires generating and storing $O(n)$ random numbers in $O(\log n)$ bits of precision, and reduces the condition number of any deterministic matrix to $O(n)$, matching Gaussian perturbations. Our result in particular implies a better complexity for the perturbed conjugate gradient algorithm, showing that we can solve an $n\times n$ linear system in linear space to within an arbitrarily small constant backward error using $O(n)$ matrix-vector products. In our construction, we introduce the concept of a pattern matrix, which is a dense deterministic matrix that maps all sparse vectors into dense vectors, and we combine it with a sparse perturbation whose entries are dependent and located in a non-uniform fashion. In order to analyze this construction, we develop new techniques for lower bounding the smallest singular value of a random matrix with dependent entries.
Last-Iterate Convergence of Randomized Kaczmarz and SGD with Greedy Step Size
Apr 10, 2026We study last-iterate convergence of SGD with greedy step size over smooth quadratics in the interpolation regime, a setting which captures the classical Randomized Kaczmarz algorithm as well as other popular iterative linear system solvers. For these methods, we show that the $t$-th iterate attains an $O(1/t^{3/4})$ convergence rate, addressing a question posed by Attia, Schliserman, Sherman, and Koren, who gave an $O(1/t^{1/2})$ guarantee for this setting. In the proof, we introduce the family of stochastic contraction processes, whose behavior can be described by the evolution of a certain deterministic eigenvalue equation, which we analyze via a careful discrete-to-continuous reduction.
Optimal Subspace Embeddings: Resolving Nelson-Nguyen Conjecture Up to Sub-Polylogarithmic Factors
Aug 19, 2025We give a proof of the conjecture of Nelson and Nguyen [FOCS 2013] on the optimal dimension and sparsity of oblivious subspace embeddings, up to sub-polylogarithmic factors: For any $n\geq d$ and $\epsilon\geq d^{-O(1)}$, there is a random $\tilde O(d/\epsilon^2)\times n$ matrix $\Pi$ with $\tilde O(\log(d)/\epsilon)$ non-zeros per column such that for any $A\in\mathbb{R}^{n\times d}$, with high probability, $(1-\epsilon)\|Ax\|\leq\|\Pi Ax\|\leq(1+\epsilon)\|Ax\|$ for all $x\in\mathbb{R}^d$, where $\tilde O(\cdot)$ hides only sub-polylogarithmic factors in $d$. Our result in particular implies a new fastest sub-current matrix multiplication time reduction of size $\tilde O(d/\epsilon^2)$ for a broad class of $n\times d$ linear regression tasks. A key novelty in our analysis is a matrix concentration technique we call iterative decoupling, which we use to fine-tune the higher-order trace moment bounds attainable via existing random matrix universality tools [Brailovskaya and van Handel, GAFA 2024].
Approaching Optimality for Solving Dense Linear Systems with Low-Rank Structure
Jul 15, 2025We provide new high-accuracy randomized algorithms for solving linear systems and regression problems that are well-conditioned except for $k$ large singular values. For solving such $d \times d$ positive definite system our algorithms succeed whp. and run in time $\tilde O(d^2 + k^\omega)$. For solving such regression problems in a matrix $\mathbf{A} \in \mathbb{R}^{n \times d}$ our methods succeed whp. and run in time $\tilde O(\mathrm{nnz}(\mathbf{A}) + d^2 + k^\omega)$ where $\omega$ is the matrix multiplication exponent and $\mathrm{nnz}(\mathbf{A})$ is the number of non-zeros in $\mathbf{A}$. Our methods nearly-match a natural complexity limit under dense inputs for these problems and improve upon a trade-off in prior approaches that obtain running times of either $\tilde O(d^{2.065}+k^\omega)$ or $\tilde O(d^2 + dk^{\omega-1})$ for $d\times d$ systems. Moreover, we show how to obtain these running times even under the weaker assumption that all but $k$ of the singular values have a suitably bounded generalized mean. Consequently, we give the first nearly-linear time algorithm for computing a multiplicative approximation to the nuclear norm of an arbitrary dense matrix. Our algorithms are built on three general recursive preconditioning frameworks, where matrix sketching and low-rank update formulas are carefully tailored to the problems' structure.
Turbocharging Gaussian Process Inference with Approximate Sketch-and-Project
May 19, 2025Gaussian processes (GPs) play an essential role in biostatistics, scientific machine learning, and Bayesian optimization for their ability to provide probabilistic predictions and model uncertainty. However, GP inference struggles to scale to large datasets (which are common in modern applications), since it requires the solution of a linear system whose size scales quadratically with the number of samples in the dataset. We propose an approximate, distributed, accelerated sketch-and-project algorithm ($\texttt{ADASAP}$) for solving these linear systems, which improves scalability. We use the theory of determinantal point processes to show that the posterior mean induced by sketch-and-project rapidly converges to the true posterior mean. In particular, this yields the first efficient, condition number-free algorithm for estimating the posterior mean along the top spectral basis functions, showing that our approach is principled for GP inference. $\texttt{ADASAP}$ outperforms state-of-the-art solvers based on conjugate gradient and coordinate descent across several benchmark datasets and a large-scale Bayesian optimization task. Moreover, $\texttt{ADASAP}$ scales to a dataset with $> 3 \cdot 10^8$ samples, a feat which has not been accomplished in the literature.
Randomized Kaczmarz Methods with Beyond-Krylov Convergence
Jan 20, 2025Randomized Kaczmarz methods form a family of linear system solvers which converge by repeatedly projecting their iterates onto randomly sampled equations. While effective in some contexts, such as highly over-determined least squares, Kaczmarz methods are traditionally deemed secondary to Krylov subspace methods, since this latter family of solvers can exploit outliers in the input's singular value distribution to attain fast convergence on ill-conditioned systems. In this paper, we introduce Kaczmarz++, an accelerated randomized block Kaczmarz algorithm that exploits outlying singular values in the input to attain a fast Krylov-style convergence. Moreover, we show that Kaczmarz++ captures large outlying singular values provably faster than popular Krylov methods, for both over- and under-determined systems. We also develop an optimized variant for positive semidefinite systems, called CD++, demonstrating empirically that it is competitive in arithmetic operations with both CG and GMRES on a collection of benchmark problems. To attain these results, we introduce several novel algorithmic improvements to the Kaczmarz framework, including adaptive momentum acceleration, Tikhonov-regularized projections, and a memoization scheme for reusing information from previously sampled equation~blocks.
Optimal Oblivious Subspace Embeddings with Near-optimal Sparsity
Nov 13, 2024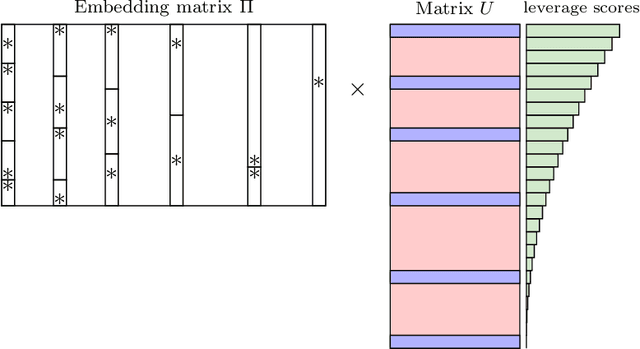
An oblivious subspace embedding is a random $m\times n$ matrix $\Pi$ such that, for any $d$-dimensional subspace, with high probability $\Pi$ preserves the norms of all vectors in that subspace within a $1\pm\epsilon$ factor. In this work, we give an oblivious subspace embedding with the optimal dimension $m=\Theta(d/\epsilon^2)$ that has a near-optimal sparsity of $\tilde O(1/\epsilon)$ non-zero entries per column of $\Pi$. This is the first result to nearly match the conjecture of Nelson and Nguyen [FOCS 2013] in terms of the best sparsity attainable by an optimal oblivious subspace embedding, improving on a prior bound of $\tilde O(1/\epsilon^6)$ non-zeros per column [Chenakkod et al., STOC 2024]. We further extend our approach to the non-oblivious setting, proposing a new family of Leverage Score Sparsified embeddings with Independent Columns, which yield faster runtimes for matrix approximation and regression tasks. In our analysis, we develop a new method which uses a decoupling argument together with the cumulant method for bounding the edge universality error of isotropic random matrices. To achieve near-optimal sparsity, we combine this general-purpose approach with new traces inequalities that leverage the specific structure of our subspace embedding construction.