 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbocharging Gaussian Process Inference with Approximate Sketch-and-Project
May 19, 2025Gaussian processes (GPs) play an essential role in biostatistics, scientific machine learning, and Bayesian optimization for their ability to provide probabilistic predictions and model uncertainty. However, GP inference struggles to scale to large datasets (which are common in modern applications), since it requires the solution of a linear system whose size scales quadratically with the number of samples in the dataset. We propose an approximate, distributed, accelerated sketch-and-project algorithm ($\texttt{ADASAP}$) for solving these linear systems, which improves scalability. We use the theory of determinantal point processes to show that the posterior mean induced by sketch-and-project rapidly converges to the true posterior mean. In particular, this yields the first efficient, condition number-free algorithm for estimating the posterior mean along the top spectral basis functions, showing that our approach is principled for GP inference. $\texttt{ADASAP}$ outperforms state-of-the-art solvers based on conjugate gradient and coordinate descent across several benchmark datasets and a large-scale Bayesian optimization task. Moreover, $\texttt{ADASAP}$ scales to a dataset with $> 3 \cdot 10^8$ samples, a feat which has not been accomplished in the literature.
Distributed Least Squares in Small Space via Sketching and Bias Reduction
May 08, 2024

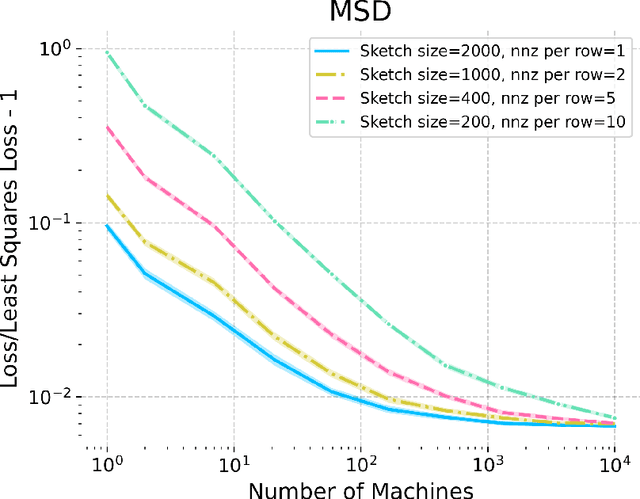

Matrix sketching is a powerful tool for reducing the size of large data matrices. Yet there are fundamental limitations to this size reduction when we want to recover an accurate estimator for a task such as least square regression. We show that these limitations can be circumvented in the distributed setting by designing sketching methods that minimize the bias of the estimator, rather than its error. In particular, we give a sparse sketching method running in optimal space and current matrix multiplication time, which recovers a nearly-unbiased least squares estimator using two passes over the data. This leads to new communication-efficient distributed averaging algorithms for least squares and related tasks, which directly improve on several prior approaches. Our key novelty is a new bias analysis for sketched least squares, giving a sharp characterization of its dependence on the sketch sparsity. The techniques include new higher-moment restricted Bai-Silverstein inequalities, which are of independent interest to the non-asymptotic analysis of deterministic equivalents for random matrices that arise from sketching.
Second-order Information Promotes Mini-Batch Robustness in Variance-Reduced Gradients
Apr 23, 2024We show that, for finite-sum minimization problems, incorporating partial second-order information of the objective function can dramatically improve the robustness to mini-batch size of variance-reduced stochastic gradient methods, making them more scalable while retaining their benefits over traditional Newton-type approaches. We demonstrate this phenomenon on a prototypical stochastic second-order algorithm, called Mini-Batch Stochastic Variance-Reduced Newton ($\texttt{Mb-SVRN}$), which combines variance-reduced gradient estimates with access to an approximate Hessian oracle. In particular, we show that when the data size $n$ is sufficiently large, i.e., $n\gg \alpha^2\kappa$, where $\kappa$ is the condition number and $\alpha$ is the Hessian approximation factor, then $\texttt{Mb-SVRN}$ achieves a fast linear convergence rate that is independent of the gradient mini-batch size $b$, as long $b$ is in the range between $1$ and $b_{\max}=O(n/(\alpha \log n))$. Only after increasing the mini-batch size past this critical point $b_{\max}$, the method begins to transition into a standard Newton-type algorithm which is much more sensitive to the Hessian approximation quality. We demonstrate this phenomenon empirically on benchmark optimization tasks showing that, after tuning the step size, the convergence rate of $\texttt{Mb-SVRN}$ remains fast for a wide range of mini-batch sizes, and the dependence of the phase transition point $b_{\max}$ on the Hessian approximation factor $\alpha$ aligns with our theoretical predictions.