 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Subspace Embeddings: Resolving Nelson-Nguyen Conjecture Up to Sub-Polylogarithmic Factors
Aug 19, 2025We give a proof of the conjecture of Nelson and Nguyen [FOCS 2013] on the optimal dimension and sparsity of oblivious subspace embeddings, up to sub-polylogarithmic factors: For any $n\geq d$ and $\epsilon\geq d^{-O(1)}$, there is a random $\tilde O(d/\epsilon^2)\times n$ matrix $\Pi$ with $\tilde O(\log(d)/\epsilon)$ non-zeros per column such that for any $A\in\mathbb{R}^{n\times d}$, with high probability, $(1-\epsilon)\|Ax\|\leq\|\Pi Ax\|\leq(1+\epsilon)\|Ax\|$ for all $x\in\mathbb{R}^d$, where $\tilde O(\cdot)$ hides only sub-polylogarithmic factors in $d$. Our result in particular implies a new fastest sub-current matrix multiplication time reduction of size $\tilde O(d/\epsilon^2)$ for a broad class of $n\times d$ linear regression tasks. A key novelty in our analysis is a matrix concentration technique we call iterative decoupling, which we use to fine-tune the higher-order trace moment bounds attainable via existing random matrix universality tools [Brailovskaya and van Handel, GAFA 2024].
Optimal Oblivious Subspace Embeddings with Near-optimal Sparsity
Nov 13, 2024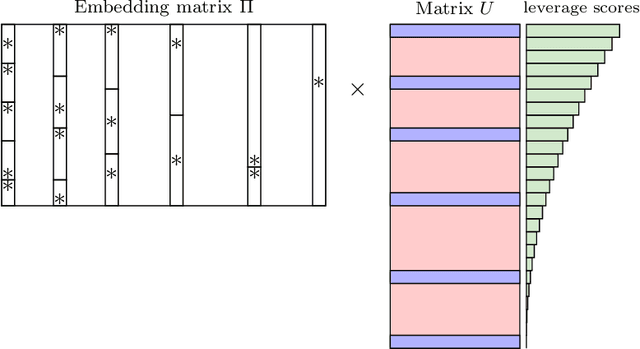
An oblivious subspace embedding is a random $m\times n$ matrix $\Pi$ such that, for any $d$-dimensional subspace, with high probability $\Pi$ preserves the norms of all vectors in that subspace within a $1\pm\epsilon$ factor. In this work, we give an oblivious subspace embedding with the optimal dimension $m=\Theta(d/\epsilon^2)$ that has a near-optimal sparsity of $\tilde O(1/\epsilon)$ non-zero entries per column of $\Pi$. This is the first result to nearly match the conjecture of Nelson and Nguyen [FOCS 2013] in terms of the best sparsity attainable by an optimal oblivious subspace embedding, improving on a prior bound of $\tilde O(1/\epsilon^6)$ non-zeros per column [Chenakkod et al., STOC 2024]. We further extend our approach to the non-oblivious setting, proposing a new family of Leverage Score Sparsified embeddings with Independent Columns, which yield faster runtimes for matrix approximation and regression tasks. In our analysis, we develop a new method which uses a decoupling argument together with the cumulant method for bounding the edge universality error of isotropic random matrices. To achieve near-optimal sparsity, we combine this general-purpose approach with new traces inequalities that leverage the specific structure of our subspace embedding construction.
Optimal Embedding Dimension for Sparse Subspace Embeddings
Nov 17, 2023


A random $m\times n$ matrix $S$ is an oblivious subspace embedding (OSE) with parameters $\epsilon>0$, $\delta\in(0,1/3)$ and $d\leq m\leq n$, if for any $d$-dimensional subspace $W\subseteq R^n$, $P\big(\,\forall_{x\in W}\ (1+\epsilon)^{-1}\|x\|\leq\|Sx\|\leq (1+\epsilon)\|x\|\,\big)\geq 1-\delta.$ It is known that the embedding dimension of an OSE must satisfy $m\geq d$, and for any $\theta > 0$, a Gaussian embedding matrix with $m\geq (1+\theta) d$ is an OSE with $\epsilon = O_\theta(1)$. However, such optimal embedding dimension is not known for other embeddings. Of particular interest are sparse OSEs, having $s\ll m$ non-zeros per column, with applications to problems such as least squares regression and low-rank approximation. We show that, given any $\theta > 0$, an $m\times n$ random matrix $S$ with $m\geq (1+\theta)d$ consisting of randomly sparsified $\pm1/\sqrt s$ entries and having $s= O(\log^4(d))$ non-zeros per column, is an oblivious subspace embedding with $\epsilon = O_{\theta}(1)$. Our result addresses the main open question posed by Nelson and Nguyen (FOCS 2013), who conjectured that sparse OSEs can achieve $m=O(d)$ embedding dimension, and it improves on $m=O(d\log(d))$ shown by Cohen (SODA 2016). We use this to construct the first oblivious subspace embedding with $O(d)$ embedding dimension that can be applied faster than current matrix multiplication time, and to obtain an optimal single-pass algorithm for least squares regression. We further extend our results to construct even sparser non-oblivious embeddings, leading to the first subspace embedding with low distortion $\epsilon=o(1)$ and optimal embedding dimension $m=O(d/\epsilon^2)$ that can be applied in current matrix multiplication time.