 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
Mar 01, 2024Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
Data Augmentation for Supervised Graph Outlier Detection with Latent Diffusion Models
Dec 29, 2023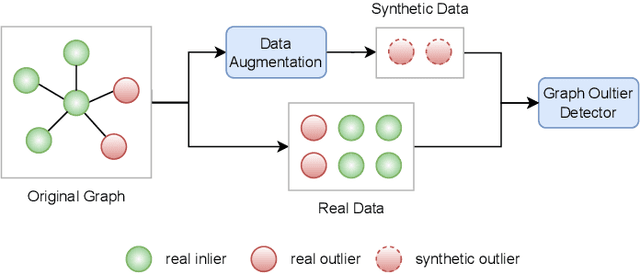
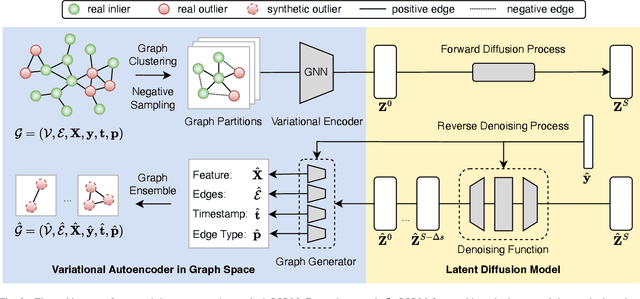
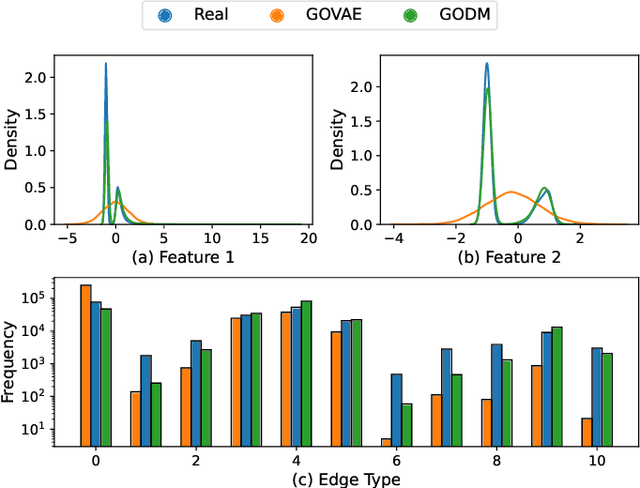
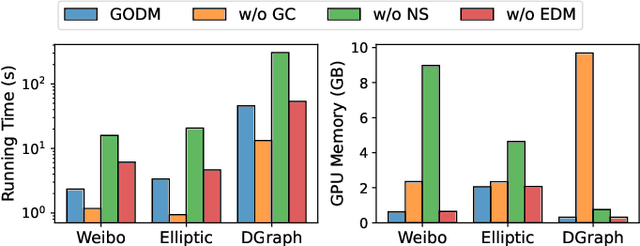
Graph outlier detection is a prominent task of research and application in the realm of graph neural networks. It identifies the outlier nodes that exhibit deviation from the majority in the graph. One of the fundamental challenges confronting supervised graph outlier detection algorithms is the prevalent issue of class imbalance, where the scarcity of outlier instances compared to normal instances often results in suboptimal performance. Conventional methods mitigate the imbalance by reweighting instances in the estimation of the loss function, assigning higher weights to outliers and lower weights to inliers. Nonetheless, these strategies are prone to overfitting and underfitting, respectively. Recently, generative models, especially diffusion models, have demonstrated their efficacy in synthesizing high-fidelity images. Despite their extraordinary generation quality, their potential in data augmentation for supervised graph outlier detection remains largely underexplored. To bridge this gap, we introduce GODM, a novel data augmentation for mitigating class imbalance in supervised Graph Outlier detection with latent Diffusion Models. Specifically, our proposed method consists of three key components: (1) Variantioanl Encoder maps the heterogeneous information inherent within the graph data into a unified latent space. (2) Graph Generator synthesizes graph data that are statistically similar to real outliers from latent space, and (3) Latent Diffusion Model learns the latent space distribution of real organic data by iterative denoising. Extensive experiments conducted on multiple datasets substantiate the effectiveness and efficiency of GODM. The case study further demonstrated the generation quality of our synthetic data. To foster accessibility and reproducibility, we encapsulate GODM into a plug-and-play package and release it at the Python Package Index (PyPI).
Graph Neural Prompting with Large Language Models
Sep 27, 2023
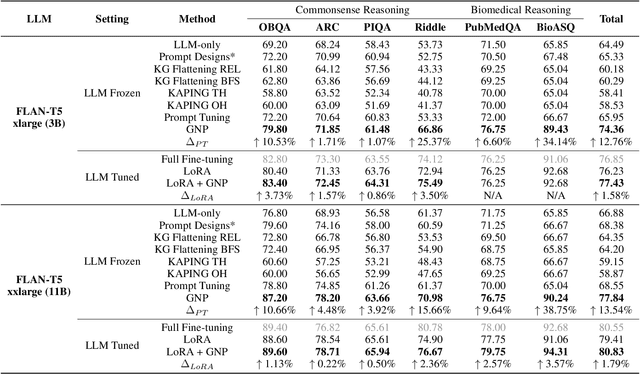
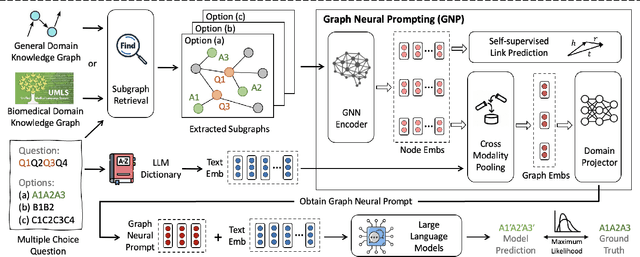
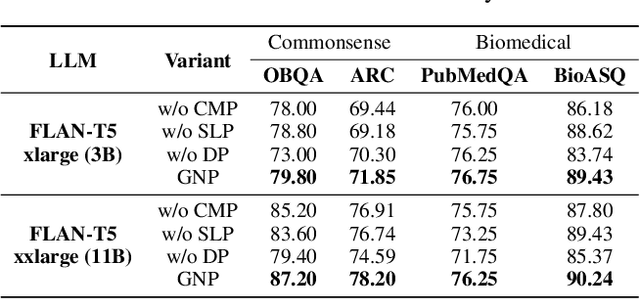
Large Language Models (LLMs) have shown remarkable generalization capability with exceptional performance in various language modeling tasks. However, they still exhibit inherent limitations in precisely capturing and returning grounded knowledge. While existing work has explored utilizing knowledge graphs to enhance language modeling via joint training and customized model architectures, applying this to LLMs is problematic owing to their large number of parameters and high computational cost. In addition, how to leverage the pre-trained LLMs and avoid training a customized model from scratch remains an open question. In this work, we propose Graph Neural Prompting (GNP), a novel plug-and-play method to assist pre-trained LLMs in learning beneficial knowledge from KGs. GNP encompasses various designs, including a standard graph neural network encoder, a cross-modality pooling module, a domain projector, and a self-supervised link prediction objective. Extensive experiments on multiple datasets demonstrate the superiority of GNP on both commonsense and biomedical reasoning tasks across different LLM sizes and settings.
Training Graph Neural Networks by Graphon Estimation
Sep 04, 2021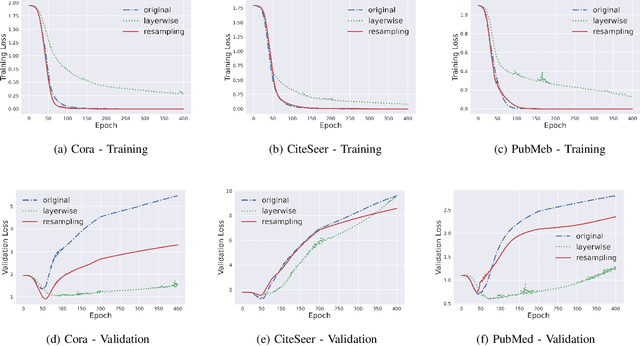
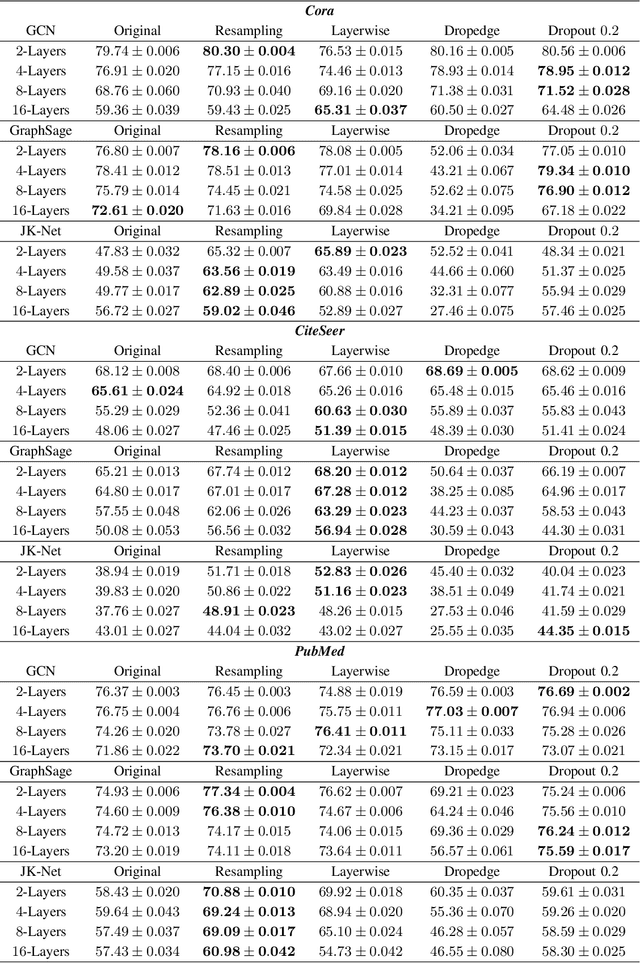
In this work, we propose to train a graph neural network via resampling from a graphon estimate obtained from the underlying network data. More specifically, the graphon or the link probability matrix of the underlying network is first obtained from which a new network will be resampled and used during the training process at each layer. Due to the uncertainty induced from the resampling, it helps mitigate the well-known issue of over-smoothing in a graph neural network (GNN) model. Our framework is general, computationally efficient, and conceptually simple. Another appealing feature of our method is that it requires minimal additional tuning during the training process. Extensive numerical results show that our approach is competitive with and in many cases outperform the other over-smoothing reducing GNN training methods.