 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Limits of Compressive Memory: A Study of Infini-Attention in Small-Scale Pretraining
Dec 29, 2025This study investigates small-scale pretraining for Small Language Models (SLMs) to enable efficient use of limited data and compute, improve accessibility in low-resource settings and reduce costs. To enhance long-context extrapolation in compact models, we focus on Infini-attention, which builds a compressed memory from past segments while preserving local attention. In our work, we conduct an empirical study using 300M-parameter LLaMA models pretrained with Infini-attention. The model demonstrates training stability and outperforms the baseline in long-context retrieval. We identify the balance factor as a key part of the model performance, and we found that retrieval accuracy drops with repeated memory compressions over long sequences. Even so, Infini-attention still effectively compensates for the SLM's limited parameters. Particularly, despite performance degradation at a 16,384-token context, the Infini-attention model achieves up to 31% higher accuracy than the baseline. Our findings suggest that achieving robust long-context capability in SLMs benefits from architectural memory like Infini-attention.
HGOT: Hierarchical Graph of Thoughts for Retrieval-Augmented In-Context Learning in Factuality Evaluation
Feb 14, 2024With the widespread adoption of large language models (LLMs) in numerous applications, the challenge of factuality and the propensity for hallucinations raises significant concerns. To address this issue, particularly in retrieval-augmented in-context learning, we introduce the hierarchical graph of thoughts (HGOT), a structured, multi-layered graph approach designed to enhance the retrieval of pertinent passages during in-context learning. The framework utilizes the emergent planning capabilities of LLMs, employing the divide-and-conquer strategy to break down complex queries into manageable sub-queries. It refines self-consistency majority voting for answer selection, which incorporates the recently proposed citation recall and precision metrics to assess the quality of thoughts, linking an answer's credibility intrinsically to the thought's quality. This methodology introduces a weighted system in majority voting, prioritizing answers based on the citation quality of their thoughts. Additionally, we propose a scoring mechanism for evaluating retrieved passages, considering factors such as citation frequency and quality, self-consistency confidence, and the retrieval module's ranking. Experiments reveal that HGOT outperforms other retrieval-augmented in-context learning methods, including Demonstrate-Search-Predict (DSP), ReAct, Self-Ask, and Retrieve-then-Read on different datasets by as much as $7\%$, demonstrating its efficacy in enhancing the factuality of LLMs.
ChatGPT as Data Augmentation for Compositional Generalization: A Case Study in Open Intent Detection
Aug 25, 2023Open intent detection, a crucial aspect of natural language understanding, involves the identification of previously unseen intents in user-generated text. Despite the progress made in this field, challenges persist in handling new combinations of language components, which is essential for compositional generalization. In this paper, we present a case study exploring the use of ChatGPT as a data augmentation technique to enhance compositional generalization in open intent detection tasks. We begin by discussing the limitations of existing benchmarks in evaluating this problem, highlighting the need for constructing datasets for addressing compositional generalization in open intent detection tasks. By incorporating synthetic data generated by ChatGPT into the training process, we demonstrate that our approach can effectively improve model performance. Rigorous evaluation of multiple benchmarks reveals that our method outperforms existing techniques and significantly enhances open intent detection capabilities. Our findings underscore the potential of large language models like ChatGPT for data augmentation in natural language understanding tasks.
Intrinsic and extrinsic deep learning on manifolds
Feb 16, 2023We propose extrinsic and intrinsic deep neural network architectures as general frameworks for deep learning on manifolds. Specifically, extrinsic deep neural networks (eDNNs) preserve geometric features on manifolds by utilizing an equivariant embedding from the manifold to its image in the Euclidean space. Moreover, intrinsic deep neural networks (iDNNs) incorporate the underlying intrinsic geometry of manifolds via exponential and log maps with respect to a Riemannian structure. Consequently, we prove that the empirical risk of the empirical risk minimizers (ERM) of eDNNs and iDNNs converge in optimal rates. Overall, The eDNNs framework is simple and easy to compute, while the iDNNs framework is accurate and fast converging. To demonstrate the utilities of our framework, various simulation studies, and real data analyses are presented with eDNNs and iDNNs.
Extrinsic Bayesian Optimizations on Manifolds
Dec 29, 2022We propose an extrinsic Bayesian optimization (eBO) framework for general optimization problems on manifolds. Bayesian optimization algorithms build a surrogate of the objective function by employing Gaussian processes and quantify the uncertainty in that surrogate by deriving an acquisition function. This acquisition function represents the probability of improvement based on the kernel of the Gaussian process, which guides the search in the optimization process. The critical challenge for designing Bayesian optimization algorithms on manifolds lies in the difficulty of constructing valid covariance kernels for Gaussian processes on general manifolds. Our approach is to employ extrinsic Gaussian processes by first embedding the manifold onto some higher dimensional Euclidean space via equivariant embeddings and then constructing a valid covariance kernel on the image manifold after the embedding. This leads to efficient and scalable algorithms for optimization over complex manifolds. Simulation study and real data analysis are carried out to demonstrate the utilities of our eBO framework by applying the eBO to various optimization problems over manifolds such as the sphere, the Grassmannian, and the manifold of positive definite matrices.
Training Graph Neural Networks by Graphon Estimation
Sep 04, 2021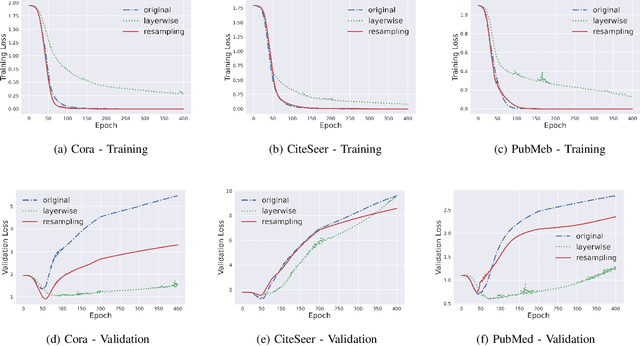
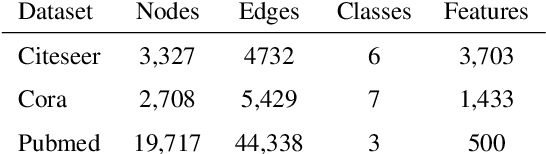
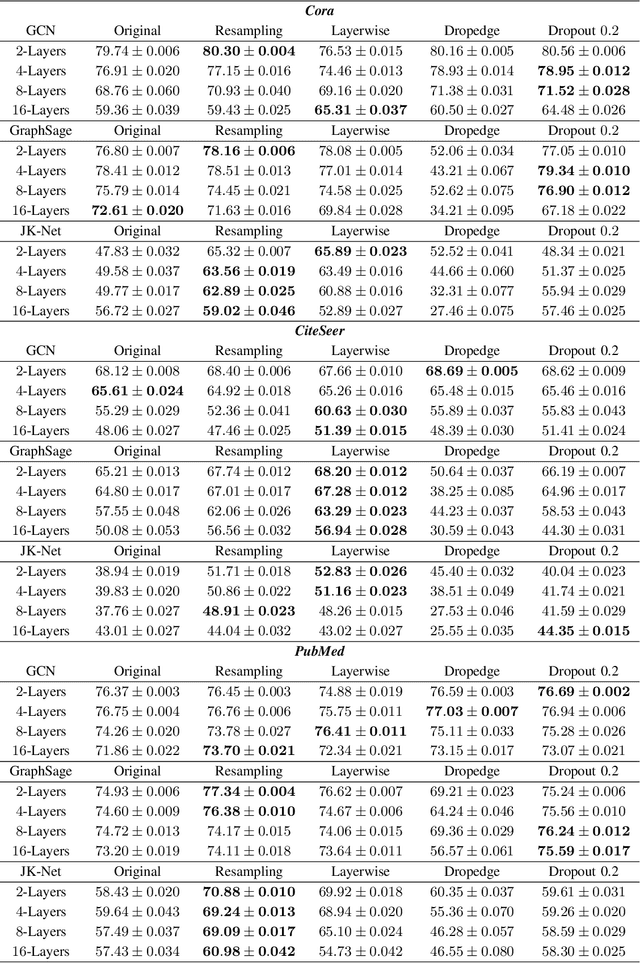
In this work, we propose to train a graph neural network via resampling from a graphon estimate obtained from the underlying network data. More specifically, the graphon or the link probability matrix of the underlying network is first obtained from which a new network will be resampled and used during the training process at each layer. Due to the uncertainty induced from the resampling, it helps mitigate the well-known issue of over-smoothing in a graph neural network (GNN) model. Our framework is general, computationally efficient, and conceptually simple. Another appealing feature of our method is that it requires minimal additional tuning during the training process. Extensive numerical results show that our approach is competitive with and in many cases outperform the other over-smoothing reducing GNN training methods.
Optimization of Graph Neural Networks with Natural Gradient Descent
Aug 21, 2020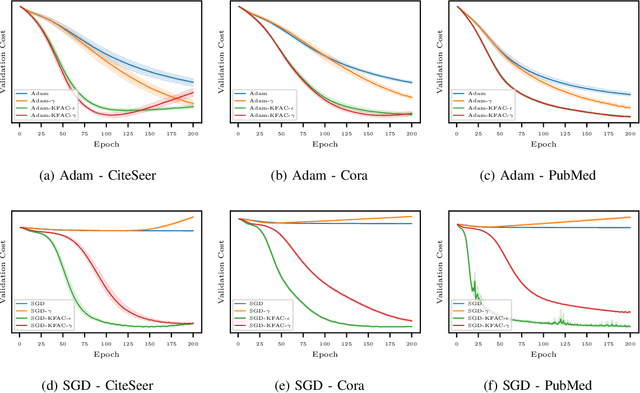
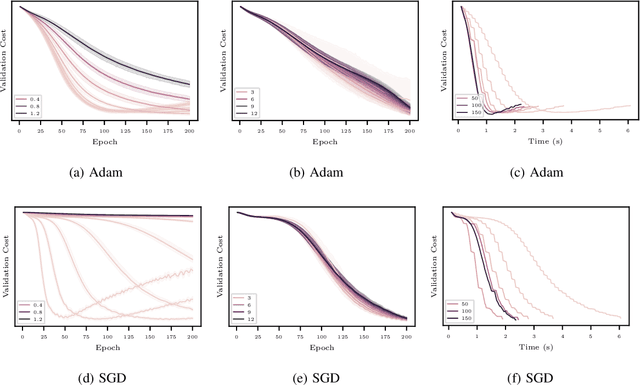
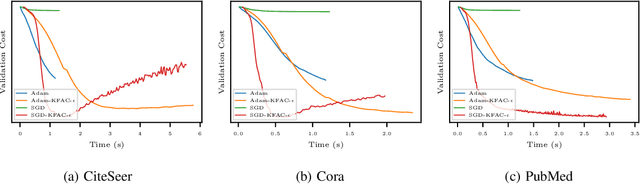

In this work, we propose to employ information-geometric tools to optimize a graph neural network architecture such as the graph convolutional networks. More specifically, we develop optimization algorithms for the graph-based semi-supervised learning by employing the natural gradient information in the optimization process. This allows us to efficiently exploit the geometry of the underlying statistical model or parameter space for optimization and inference. To the best of our knowledge, this is the first work that has utilized the natural gradient for the optimization of graph neural networks that can be extended to other semi-supervised problems. Efficient computations algorithms are developed and extensive numerical studies are conducted to demonstrate the superior performance of our algorithms over existing algorithms such as ADAM and SGD.
CacheNet: A Model Caching Framework for Deep Learning Inference on the Edge
Jul 03, 2020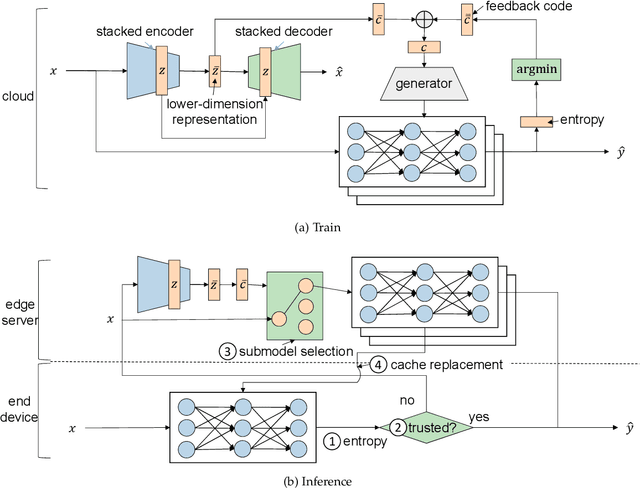
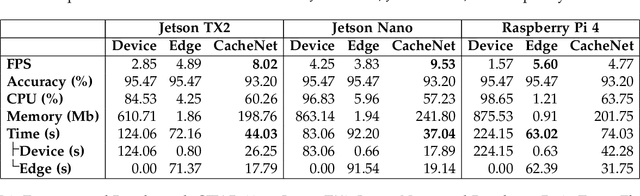
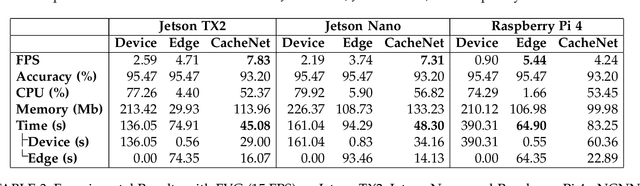
The success of deep neural networks (DNN) in machine perception applications such as image classification and speech recognition comes at the cost of high computation and storage complexity. Inference of uncompressed large scale DNN models can only run in the cloud with extra communication latency back and forth between cloud and end devices, while compressed DNN models achieve real-time inference on end devices at the price of lower predictive accuracy. In order to have the best of both worlds (latency and accuracy), we propose CacheNet, a model caching framework. CacheNet caches low-complexity models on end devices and high-complexity (or full) models on edge or cloud servers. By exploiting temporal locality in streaming data, high cache hit and consequently shorter latency can be achieved with no or only marginal decrease in prediction accuracy. Experiments on CIFAR-10 and FVG have shown CacheNet is 58-217% faster than baseline approaches that run inference tasks on end devices or edge servers alone.
Logographic Subword Model for Neural Machine Translation
Sep 07, 2018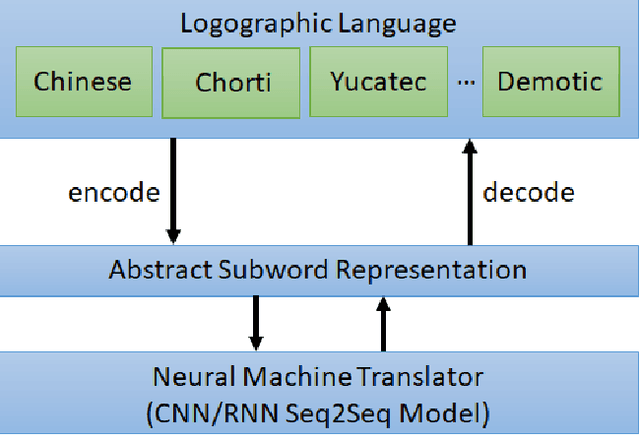

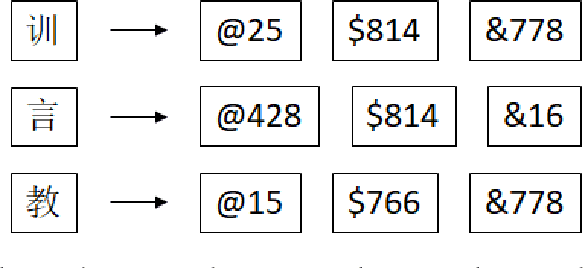
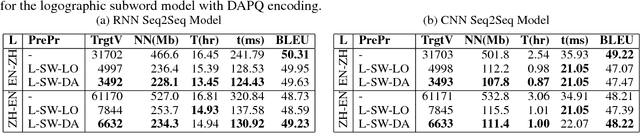
A novel logographic subword model is proposed to reinterpret logograms as abstract subwords for neural machine translation. Our approach drastically reduces the size of an artificial neural network, while maintaining comparable BLEU scores as those attained with the baseline RNN and CNN seq2seq models. The smaller model size also leads to shorter training and inference time. Experiments demonstrate that in the tasks of English-Chinese/Chinese-English translation, the reduction of those aspects can be from $11\%$ to as high as $77\%$. Compared to previous subword models, abstract subwords can be applied to various logographic languages. Considering most of the logographic languages are ancient and very low resource languages, these advantages are very desirable for archaeological computational linguistic applications such as a resource-limited offline hand-held Demotic-English translator.