 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCacheNet: A Model Caching Framework for Deep Learning Inference on the Edge
Paper and Code
Jul 03, 2020
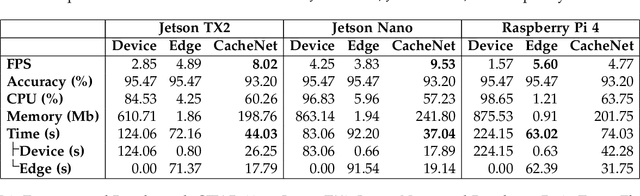
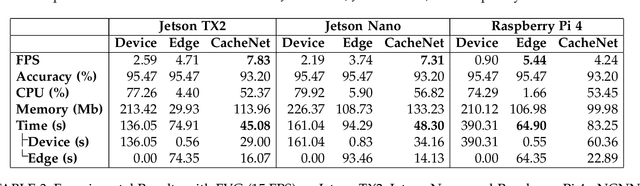
The success of deep neural networks (DNN) in machine perception applications such as image classification and speech recognition comes at the cost of high computation and storage complexity. Inference of uncompressed large scale DNN models can only run in the cloud with extra communication latency back and forth between cloud and end devices, while compressed DNN models achieve real-time inference on end devices at the price of lower predictive accuracy. In order to have the best of both worlds (latency and accuracy), we propose CacheNet, a model caching framework. CacheNet caches low-complexity models on end devices and high-complexity (or full) models on edge or cloud servers. By exploiting temporal locality in streaming data, high cache hit and consequently shorter latency can be achieved with no or only marginal decrease in prediction accuracy. Experiments on CIFAR-10 and FVG have shown CacheNet is 58-217% faster than baseline approaches that run inference tasks on end devices or edge servers alone.