 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Transformers Through Attention Head Intervention
Jan 07, 2026Neural networks are growing more capable on their own, but we do not understand their neural mechanisms. Understanding these mechanisms' decision-making processes, or mechanistic interpretability, enables (1) accountability and control in high-stakes domains, (2) the study of digital brains and the emergence of cognition, and (3) discovery of new knowledge when AI systems outperform humans.
RealPDEBench: A Benchmark for Complex Physical Systems with Real-World Data
Jan 05, 2026Predicting the evolution of complex physical systems remains a central problem in science and engineering. Despite rapid progress in scientific Machine Learning (ML) models, a critical bottleneck is the lack of expensive real-world data, resulting in most current models being trained and validated on simulated data. Beyond limiting the development and evaluation of scientific ML, this gap also hinders research into essential tasks such as sim-to-real transfer. We introduce RealPDEBench, the first benchmark for scientific ML that integrates real-world measurements with paired numerical simulations. RealPDEBench consists of five datasets, three tasks, eight metrics, and ten baselines. We first present five real-world measured datasets with paired simulated datasets across different complex physical systems. We further define three tasks, which allow comparisons between real-world and simulated data, and facilitate the development of methods to bridge the two. Moreover, we design eight evaluation metrics, spanning data-oriented and physics-oriented metrics, and finally benchmark ten representative baselines, including state-of-the-art models, pretrained PDE foundation models, and a traditional method. Experiments reveal significant discrepancies between simulated and real-world data, while showing that pretraining with simulated data consistently improves both accuracy and convergence. In this work, we hope to provide insights from real-world data, advancing scientific ML toward bridging the sim-to-real gap and real-world deployment. Our benchmark, datasets, and instructions are available at https://realpdebench.github.io/.
Understanding the Representation of Older Adults in Motion Capture Locomotion Datasets
Nov 12, 2025The Internet of Things (IoT) sensors have been widely employed to capture human locomotions to enable applications such as activity recognition, human pose estimation, and fall detection. Motion capture (MoCap) systems are frequently used to generate ground truth annotations for human poses when training models with data from wearable or ambient sensors, and have been shown to be effective to synthesize data in these modalities. However, the representation of older adults, an increasingly important demographic in healthcare, in existing MoCap locomotion datasets has not been thoroughly examined. This work surveyed 41 publicly available datasets, identifying eight that include older adult motions and four that contain motions performed by younger actors annotated as old style. Older adults represent a small portion of participants overall, and few datasets provide full-body motion data for this group. To assess the fidelity of old-style walking motions, quantitative metrics are introduced, defining high fidelity as the ability to capture age-related differences relative to normative walking. Using gait parameters that are age-sensitive, robust to noise, and resilient to data scarcity, we found that old-style walking motions often exhibit overly controlled patterns and fail to faithfully characterize aging. These findings highlight the need for improved representation of older adults in motion datasets and establish a method to quantitatively evaluate the quality of old-style walking motions.
Personality-Enhanced Multimodal Depression Detection in the Elderly
Oct 09, 2025This paper presents our solution to the Multimodal Personality-aware Depression Detection (MPDD) challenge at ACM MM 2025. We propose a multimodal depression detection model in the Elderly that incorporates personality characteristics. We introduce a multi-feature fusion approach based on a co-attention mechanism to effectively integrate LLDs, MFCCs, and Wav2Vec features in the audio modality. For the video modality, we combine representations extracted from OpenFace, ResNet, and DenseNet to construct a comprehensive visual feature set. Recognizing the critical role of personality in depression detection, we design an interaction module that captures the relationships between personality traits and multimodal features. Experimental results from the MPDD Elderly Depression Detection track demonstrate that our method significantly enhances performance, providing valuable insights for future research in multimodal depression detection among elderly populations.
Overlap-Adaptive Hybrid Speaker Diarization and ASR-Aware Observation Addition for MISP 2025 Challenge
May 28, 2025This paper presents the system developed to address the MISP 2025 Challenge. For the diarization system, we proposed a hybrid approach combining a WavLM end-to-end segmentation method with a traditional multi-module clustering technique to adaptively select the appropriate model for handling varying degrees of overlapping speech. For the automatic speech recognition (ASR) system, we proposed an ASR-aware observation addition method that compensates for the performance limitations of Guided Source Separation (GSS) under low signal-to-noise ratio conditions. Finally, we integrated the speaker diarization and ASR systems in a cascaded architecture to address Track 3. Our system achieved character error rates (CER) of 9.48% on Track 2 and concatenated minimum permutation character error rate (cpCER) of 11.56% on Track 3, ultimately securing first place in both tracks and thereby demonstrating the effectiveness of the proposed methods in real-world meeting scenarios.
Leveraging LLM for Stuttering Speech: A Unified Architecture Bridging Recognition and Event Detection
May 28, 2025The performance bottleneck of Automatic Speech Recognition (ASR) in stuttering speech scenarios has limited its applicability in domains such as speech rehabilitation. This paper proposed an LLM-driven ASR-SED multi-task learning framework that jointly optimized the ASR and Stuttering Event Detection (SED) tasks. We proposed a dynamic interaction mechanism where the ASR branch leveraged CTC-generated soft prompts to assist LLM context modeling, while the SED branch output stutter embeddings to enhance LLM comprehension of stuttered speech. We incorporated contrastive learning to strengthen the discriminative power of stuttering acoustic features and applied Focal Loss to mitigate the long-tailed distribution in stuttering event categories. Evaluations on the AS-70 Mandarin stuttering dataset demonstrated that our framework reduced the ASR character error rate (CER) to 5.45% (-37.71% relative reduction) and achieved an average SED F1-score of 73.63% (+46.58% relative improvement).
ActionPose: Pretraining 3D Human Pose Estimation with the Dark Knowledge of Action
Aug 31, 2024



2D-to-3D human pose lifting is an ill-posed problem due to depth ambiguity and occlusion. Existing methods relying on spatial and temporal consistency alone are insufficient to resolve these problems because they lack semantic information of the motions. To overcome this, we propose ActionPose, a framework that leverages action knowledge by aligning motion embeddings with text embeddings of fine-grained action labels. ActionPose operates in two stages: pretraining and fine-tuning. In the pretraining stage, the model learns to recognize actions and reconstruct 3D poses from masked and noisy 2D poses. During the fine-tuning stage, the model is further refined using real-world 3D human pose estimation datasets without action labels. Additionally, our framework incorporates masked body parts and masked time windows in motion modeling to mitigate the effects of ambiguous boundaries between actions in both temporal and spatial domains. Experiments demonstrate the effectiveness of ActionPose, achieving state-of-the-art performance in 3D pose estimation on public datasets, including Human3.6M and MPI-INF-3DHP. Specifically, ActionPose achieves an MPJPE of 36.7mm on Human3.6M with detected 2D poses as input and 15.5mm on MPI-INF-3DHP with ground-truth 2D poses as input.
SUPER: Seated Upper Body Pose Estimation using mmWave Radars
Jul 02, 2024In industrial countries, adults spend a considerable amount of time sedentary each day at work, driving and during activities of daily living. Characterizing the seated upper body human poses using mmWave radars is an important, yet under-studied topic with many applications in human-machine interaction, transportation and road safety. In this work, we devise SUPER, a framework for seated upper body human pose estimation that utilizes dual-mmWave radars in close proximity. A novel masking algorithm is proposed to coherently fuse data from the radars to generate intensity and Doppler point clouds with complementary information for high-motion but small radar cross section areas (e.g., upper extremities) and low-motion but large RCS areas (e.g. torso). A lightweight neural network extracts both global and local features of upper body and output pose parameters for the Skinned Multi-Person Linear (SMPL) model. Extensive leave-one-subject-out experiments on various motion sequences from multiple subjects show that SUPER outperforms a state-of-the-art baseline method by 30 -- 184%. We also demonstrate its utility in a simple downstream task for hand-object interaction.
Learning Online Policies for Person Tracking in Multi-View Environments
Dec 26, 2023

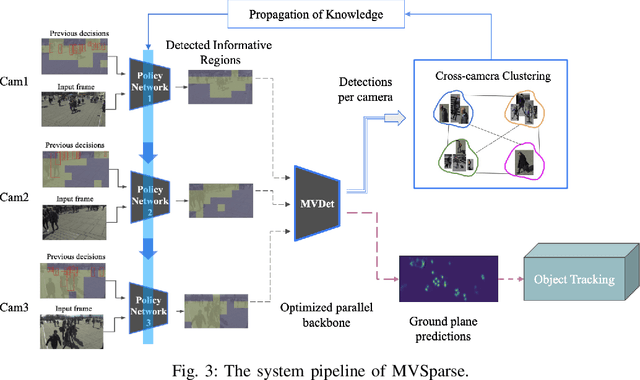

In this paper, we introduce MVSparse, a novel and efficient framework for cooperative multi-person tracking across multiple synchronized cameras. The MVSparse system is comprised of a carefully orchestrated pipeline, combining edge server-based models with distributed lightweight Reinforcement Learning (RL) agents operating on individual cameras. These RL agents intelligently select informative blocks within each frame based on historical camera data and detection outcomes from neighboring cameras, significantly reducing computational load and communication overhead. The edge server aggregates multiple camera views to perform detection tasks and provides feedback to the individual agents. By projecting inputs from various perspectives onto a common ground plane and applying deep detection models, MVSparse optimally leverages temporal and spatial redundancy in multi-view videos. Notably, our contributions include an empirical analysis of multi-camera pedestrian tracking datasets, the development of a multi-camera, multi-person detection pipeline, and the implementation of MVSparse, yielding impressive results on both open datasets and real-world scenarios. Experimentally, MVSparse accelerates overall inference time by 1.88X and 1.60X compared to a baseline approach while only marginally compromising tracking accuracy by 2.27% and 3.17%, respectively, showcasing its promising potential for efficient multi-camera tracking applications.
MirrorCalib: Utilizing Human Pose Information for Mirror-based Virtual Camera Calibration
Nov 05, 2023



In this paper, we present the novel task of estimating the extrinsic parameters of a virtual camera with respect to a real camera with one single fixed planar mirror. This task poses a significant challenge in cases where objects captured lack overlapping views from both real and mirrored cameras. To address this issue, prior knowledge of a human body and 2D joint locations are utilized to estimate the camera extrinsic parameters when a person is in front of a mirror. We devise a modified eight-point algorithm to obtain an initial estimation from 2D joint locations. The 2D joint locations are then refined subject to human body constraints. Finally, a RANSAC algorithm is employed to remove outliers by comparing their epipolar distances to a predetermined threshold. MirrorCalib is evaluated on both synthetic and real datasets and achieves a rotation error of 0.62{\deg}/1.82{\deg} and a translation error of 37.33/69.51 mm on the synthetic/real dataset, which outperforms the state-of-art method.