 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverlap-Adaptive Hybrid Speaker Diarization and ASR-Aware Observation Addition for MISP 2025 Challenge
May 28, 2025This paper presents the system developed to address the MISP 2025 Challenge. For the diarization system, we proposed a hybrid approach combining a WavLM end-to-end segmentation method with a traditional multi-module clustering technique to adaptively select the appropriate model for handling varying degrees of overlapping speech. For the automatic speech recognition (ASR) system, we proposed an ASR-aware observation addition method that compensates for the performance limitations of Guided Source Separation (GSS) under low signal-to-noise ratio conditions. Finally, we integrated the speaker diarization and ASR systems in a cascaded architecture to address Track 3. Our system achieved character error rates (CER) of 9.48% on Track 2 and concatenated minimum permutation character error rate (cpCER) of 11.56% on Track 3, ultimately securing first place in both tracks and thereby demonstrating the effectiveness of the proposed methods in real-world meeting scenarios.
An Intra-BRNN and GB-RVQ Based END-TO-END Neural Audio Codec
Feb 02, 2024



Recently, neural networks have proven to be effective in performing speech coding task at low bitrates. However, under-utilization of intra-frame correlations and the error of quantizer specifically degrade the reconstructed audio quality. To improve the coding quality, we present an end-to-end neural speech codec, namely CBRC (Convolutional and Bidirectional Recurrent neural Codec). An interleaved structure using 1D-CNN and Intra-BRNN is designed to exploit the intra-frame correlations more efficiently. Furthermore, Group-wise and Beam-search Residual Vector Quantizer (GB-RVQ) is used to reduce the quantization noise. CBRC encodes audio every 20ms with no additional latency, which is suitable for real-time communication. Experimental results demonstrate the superiority of the proposed codec when comparing CBRC at 3kbps with Opus at 12kbps.
Three-Module Modeling For End-to-End Spoken Language Understanding Using Pre-trained DNN-HMM-Based Acoustic-Phonetic Model
Apr 07, 2022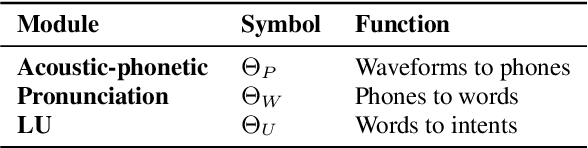
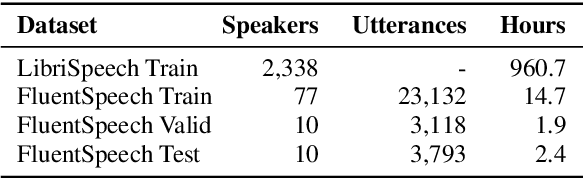
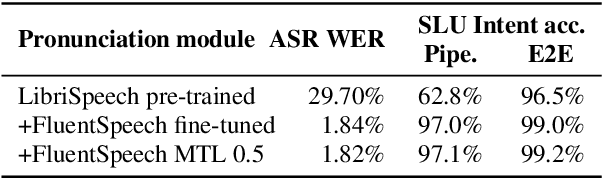

In spoken language understanding (SLU), what the user says is converted to his/her intent. Recent work on end-to-end SLU has shown that accuracy can be improved via pre-training approaches. We revisit ideas presented by Lugosch et al. using speech pre-training and three-module modeling; however, to ease construction of the end-to-end SLU model, we use as our phoneme module an open-source acoustic-phonetic model from a DNN-HMM hybrid automatic speech recognition (ASR) system instead of training one from scratch. Hence we fine-tune on speech only for the word module, and we apply multi-target learning (MTL) on the word and intent modules to jointly optimize SLU performance. MTL yields a relative reduction of 40% in intent-classification error rates (from 1.0% to 0.6%). Note that our three-module model is a streaming method. The final outcome of the proposed three-module modeling approach yields an intent accuracy of 99.4% on FluentSpeech, an intent error rate reduction of 50% compared to that of Lugosch et al. Although we focus on real-time streaming methods, we also list non-streaming methods for comparison.
PointShuffleNet: Learning Non-Euclidean Features with Homotopy Equivalence and Mutual Information
Mar 31, 2021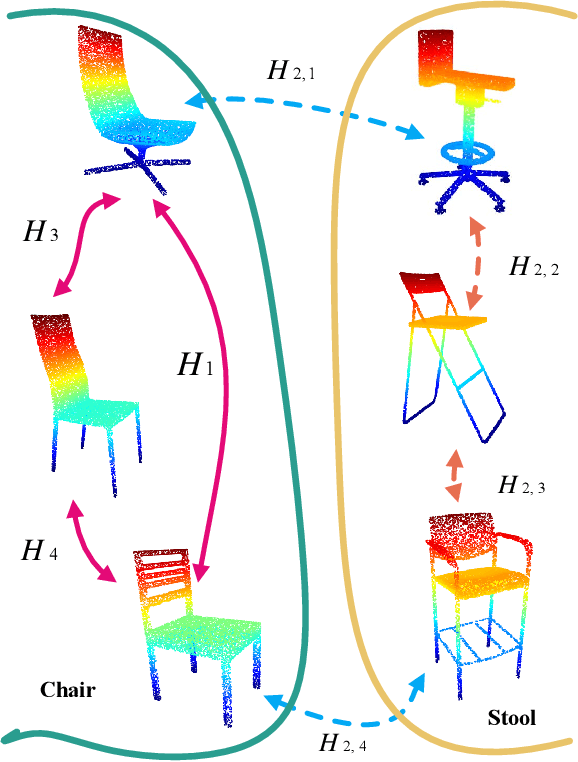
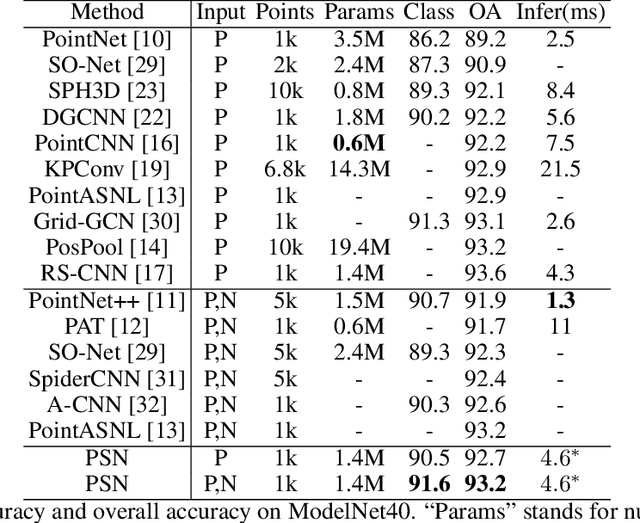
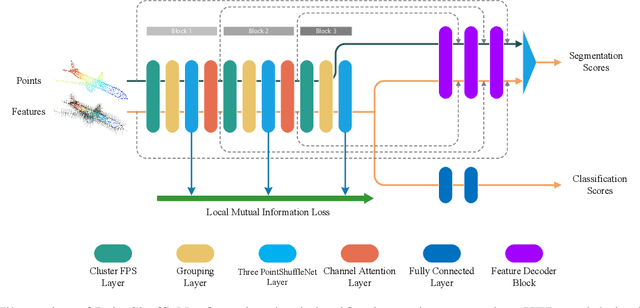
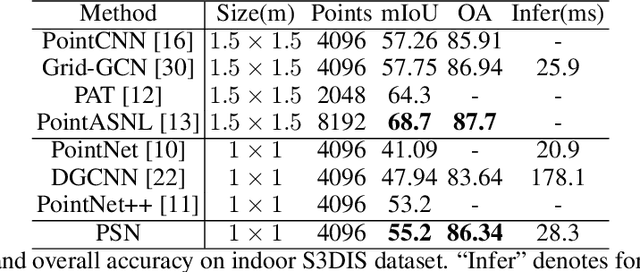
Point cloud analysis is still a challenging task due to the disorder and sparsity of samplings of their geometric structures from 3D sensors. In this paper, we introduce the homotopy equivalence relation (HER) to make the neural networks learn the data distribution from a high-dimension manifold. A shuffle operation is adopted to construct HER for its randomness and zero-parameter. In addition, inspired by prior works, we propose a local mutual information regularizer (LMIR) to cut off the trivial path that leads to a classification error from HER. LMIR utilizes mutual information to measure the distance between the original feature and HER transformed feature and learns common features in a contrastive learning scheme. Thus, we combine HER and LMIR to give our model the ability to learn non-Euclidean features from a high-dimension manifold. This is named the non-Euclidean feature learner. Furthermore, we propose a new heuristics and efficiency point sampling algorithm named ClusterFPS to obtain approximate uniform sampling but at faster speed. ClusterFPS uses a cluster algorithm to divide a point cloud into several clusters and deploy the farthest point sampling algorithm on each cluster in parallel. By combining the above methods, we propose a novel point cloud analysis neural network called PointShuffleNet (PSN), which shows great promise in point cloud classification and segmentation. Extensive experiments show that our PSN achieves state-of-the-art results on ModelNet40, ShapeNet and S3DIS with high efficiency. Theoretically, we provide mathematical analysis toward understanding of what the data distribution HER has developed and why LMIR can drop the trivial path by maximizing mutual information implicitly.