 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding Connectionist Temporal Summarization into Conformer to Improve Its Decoder Efficiency For Speech Recognition
Apr 08, 2022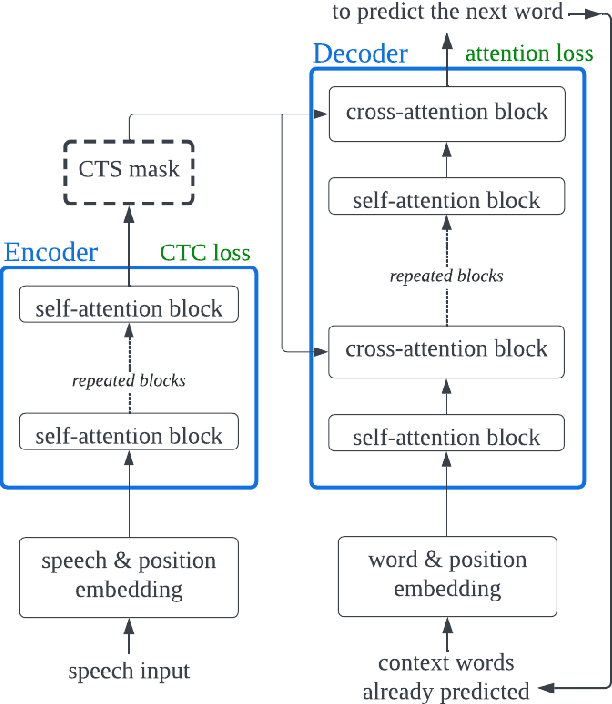
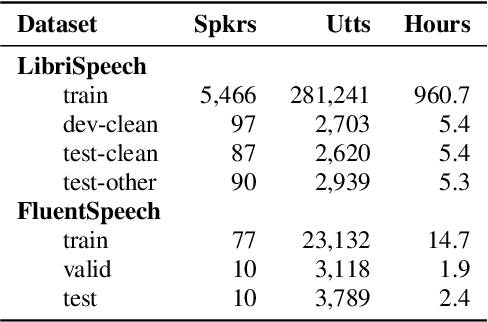
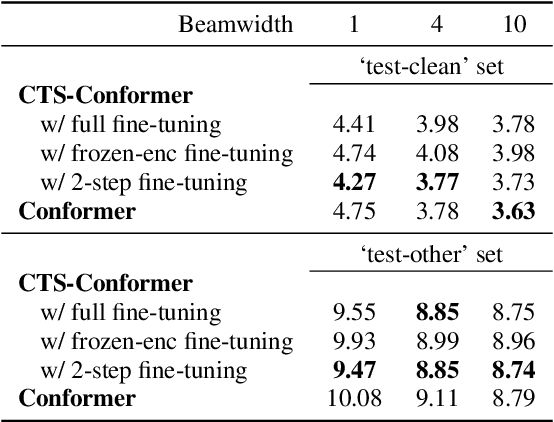

The Conformer model is an excellent architecture for speech recognition modeling that effectively utilizes the hybrid losses of connectionist temporal classification (CTC) and attention to train model parameters. To improve the decoding efficiency of Conformer, we propose a novel connectionist temporal summarization (CTS) method that reduces the number of frames required for the attention decoder fed from the acoustic sequences generated by the encoder, thus reducing operations. However, to achieve such decoding improvements, we must fine-tune model parameters, as cross-attention observations are changed and thus require corresponding refinements. Our final experiments show that, with a beamwidth of 4, the LibriSpeech's decoding budget can be reduced by up to 20% and for FluentSpeech data it can be reduced by 11%, without losing ASR accuracy. An improvement in accuracy is even found for the LibriSpeech "test-other" set. The word error rate (WER) is reduced by 6\% relative at the beam width of 1 and by 3% relative at the beam width of 4.
A Study of Different Ways to Use The Conformer Model For Spoken Language Understanding
Apr 08, 2022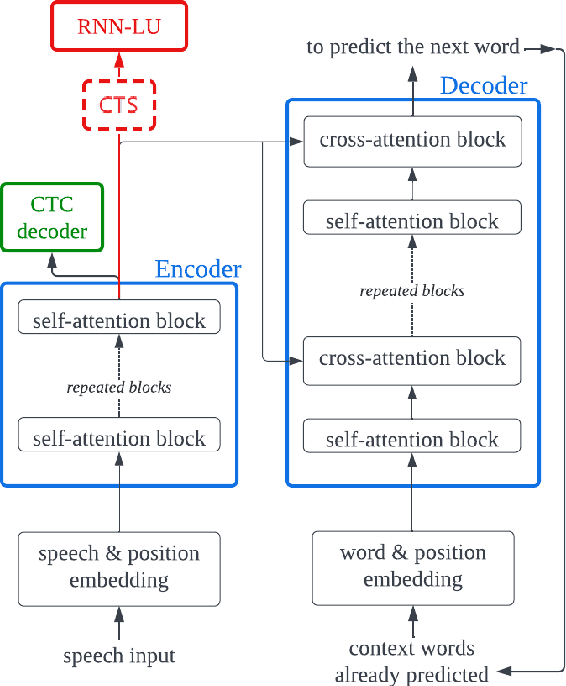
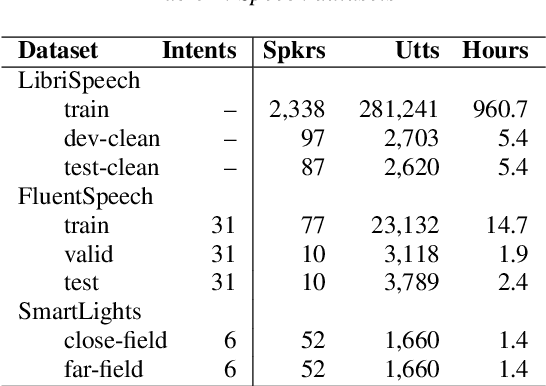
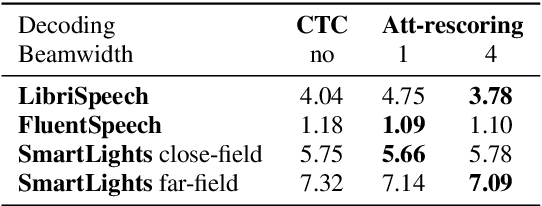
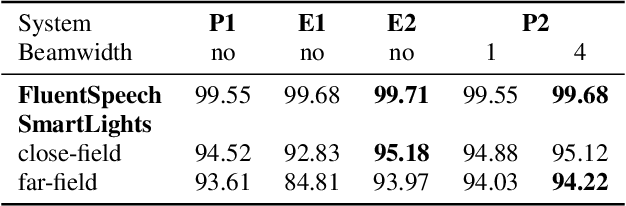
SLU combines ASR and NLU capabilities to accomplish speech-to-intent understanding. In this paper, we compare different ways to combine ASR and NLU, in particular using a single Conformer model with different ways to use its components, to better understand the strengths and weaknesses of each approach. We find that it is not necessarily a choice between two-stage decoding and end-to-end systems which determines the best system for research or application. System optimization still entails carefully improving the performance of each component. It is difficult to prove that one direction is conclusively better than the other. In this paper, we also propose a novel connectionist temporal summarization (CTS) method to reduce the length of acoustic encoding sequences while improving the accuracy and processing speed of end-to-end models. This method achieves the same intent accuracy as the best two-stage SLU recognition with complicated and time-consuming decoding but does so at lower computational cost. This stacked end-to-end SLU system yields an intent accuracy of 93.97% for the SmartLights far-field set, 95.18% for the close-field set, and 99.71% for FluentSpeech.
Three-Module Modeling For End-to-End Spoken Language Understanding Using Pre-trained DNN-HMM-Based Acoustic-Phonetic Model
Apr 07, 2022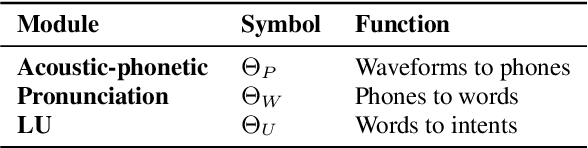
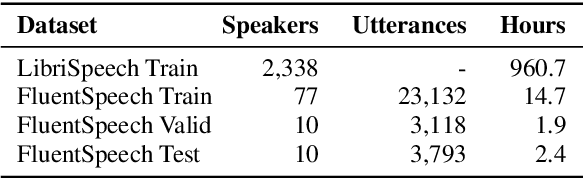
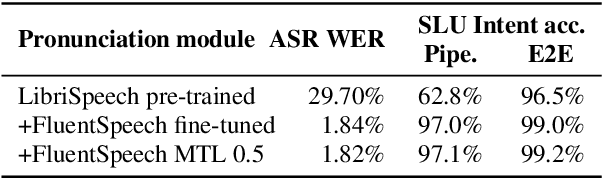

In spoken language understanding (SLU), what the user says is converted to his/her intent. Recent work on end-to-end SLU has shown that accuracy can be improved via pre-training approaches. We revisit ideas presented by Lugosch et al. using speech pre-training and three-module modeling; however, to ease construction of the end-to-end SLU model, we use as our phoneme module an open-source acoustic-phonetic model from a DNN-HMM hybrid automatic speech recognition (ASR) system instead of training one from scratch. Hence we fine-tune on speech only for the word module, and we apply multi-target learning (MTL) on the word and intent modules to jointly optimize SLU performance. MTL yields a relative reduction of 40% in intent-classification error rates (from 1.0% to 0.6%). Note that our three-module model is a streaming method. The final outcome of the proposed three-module modeling approach yields an intent accuracy of 99.4% on FluentSpeech, an intent error rate reduction of 50% compared to that of Lugosch et al. Although we focus on real-time streaming methods, we also list non-streaming methods for comparison.