 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Different Ways to Use The Conformer Model For Spoken Language Understanding
Paper and Code
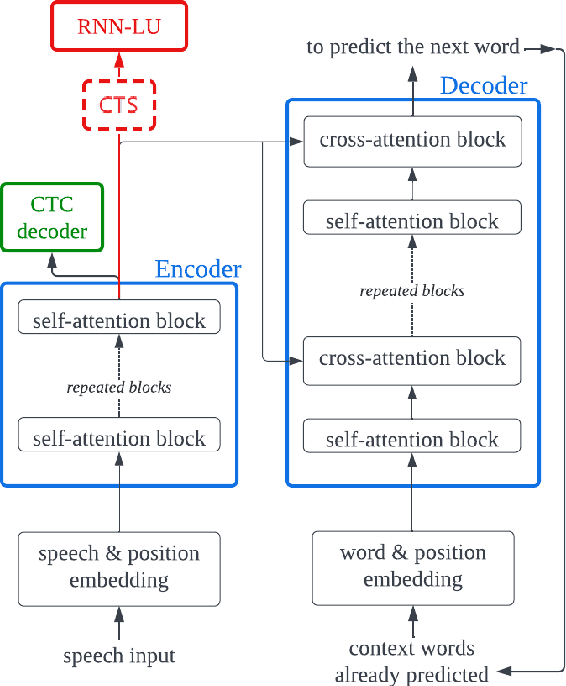
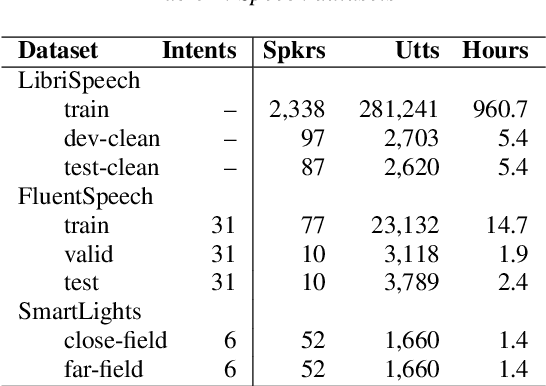
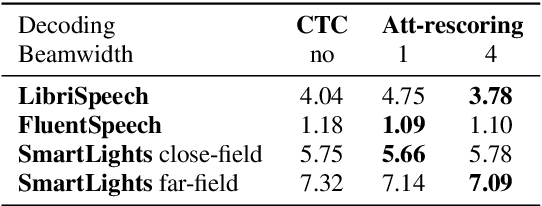
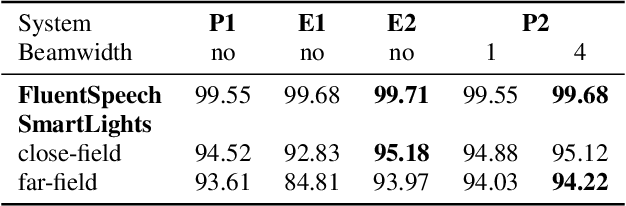
SLU combines ASR and NLU capabilities to accomplish speech-to-intent understanding. In this paper, we compare different ways to combine ASR and NLU, in particular using a single Conformer model with different ways to use its components, to better understand the strengths and weaknesses of each approach. We find that it is not necessarily a choice between two-stage decoding and end-to-end systems which determines the best system for research or application. System optimization still entails carefully improving the performance of each component. It is difficult to prove that one direction is conclusively better than the other. In this paper, we also propose a novel connectionist temporal summarization (CTS) method to reduce the length of acoustic encoding sequences while improving the accuracy and processing speed of end-to-end models. This method achieves the same intent accuracy as the best two-stage SLU recognition with complicated and time-consuming decoding but does so at lower computational cost. This stacked end-to-end SLU system yields an intent accuracy of 93.97% for the SmartLights far-field set, 95.18% for the close-field set, and 99.71% for FluentSpeech.