 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding Connectionist Temporal Summarization into Conformer to Improve Its Decoder Efficiency For Speech Recognition
Paper and Code
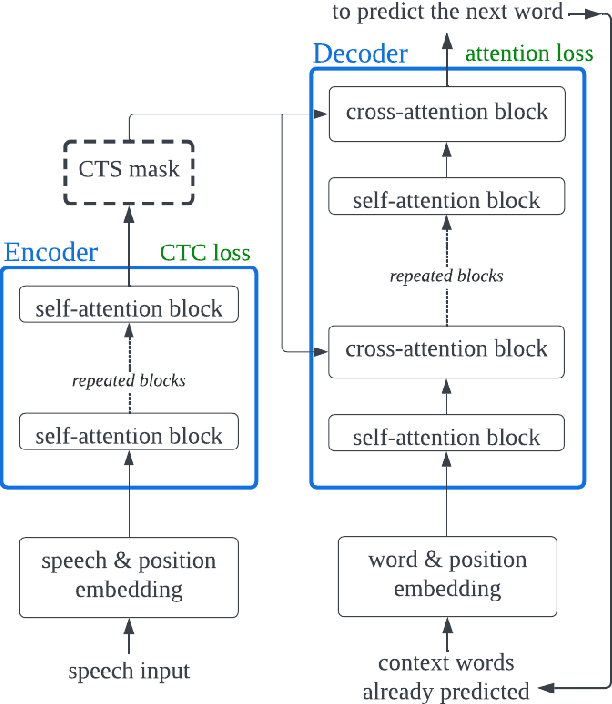
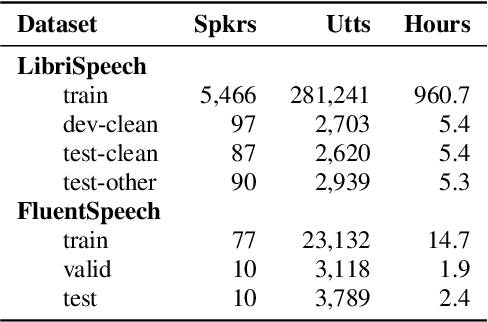
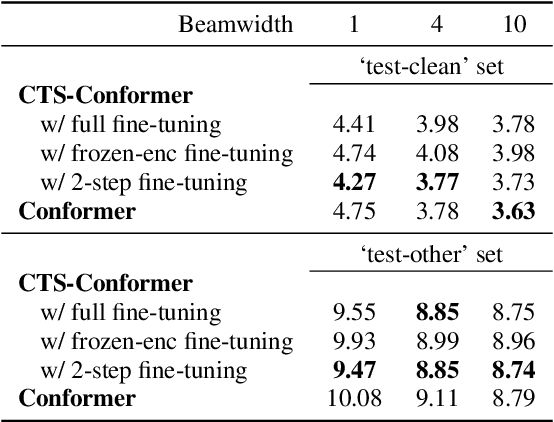

The Conformer model is an excellent architecture for speech recognition modeling that effectively utilizes the hybrid losses of connectionist temporal classification (CTC) and attention to train model parameters. To improve the decoding efficiency of Conformer, we propose a novel connectionist temporal summarization (CTS) method that reduces the number of frames required for the attention decoder fed from the acoustic sequences generated by the encoder, thus reducing operations. However, to achieve such decoding improvements, we must fine-tune model parameters, as cross-attention observations are changed and thus require corresponding refinements. Our final experiments show that, with a beamwidth of 4, the LibriSpeech's decoding budget can be reduced by up to 20% and for FluentSpeech data it can be reduced by 11%, without losing ASR accuracy. An improvement in accuracy is even found for the LibriSpeech "test-other" set. The word error rate (WER) is reduced by 6\% relative at the beam width of 1 and by 3% relative at the beam width of 4.