 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Online Policies for Person Tracking in Multi-View Environments
Dec 26, 2023

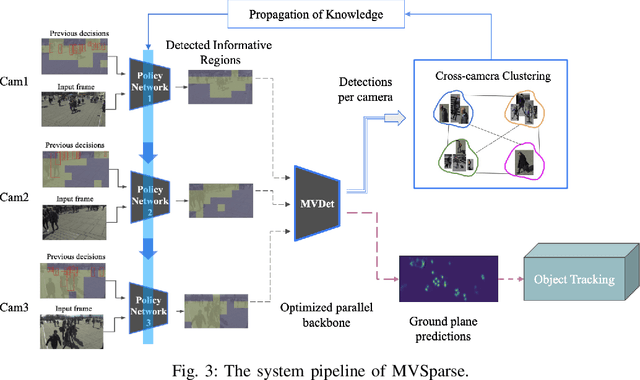

In this paper, we introduce MVSparse, a novel and efficient framework for cooperative multi-person tracking across multiple synchronized cameras. The MVSparse system is comprised of a carefully orchestrated pipeline, combining edge server-based models with distributed lightweight Reinforcement Learning (RL) agents operating on individual cameras. These RL agents intelligently select informative blocks within each frame based on historical camera data and detection outcomes from neighboring cameras, significantly reducing computational load and communication overhead. The edge server aggregates multiple camera views to perform detection tasks and provides feedback to the individual agents. By projecting inputs from various perspectives onto a common ground plane and applying deep detection models, MVSparse optimally leverages temporal and spatial redundancy in multi-view videos. Notably, our contributions include an empirical analysis of multi-camera pedestrian tracking datasets, the development of a multi-camera, multi-person detection pipeline, and the implementation of MVSparse, yielding impressive results on both open datasets and real-world scenarios. Experimentally, MVSparse accelerates overall inference time by 1.88X and 1.60X compared to a baseline approach while only marginally compromising tracking accuracy by 2.27% and 3.17%, respectively, showcasing its promising potential for efficient multi-camera tracking applications.
AttTrack: Online Deep Attention Transfer for Multi-object Tracking
Oct 16, 2022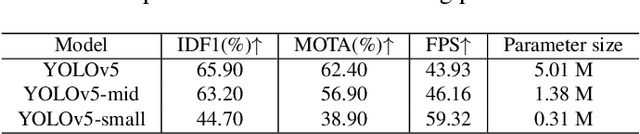

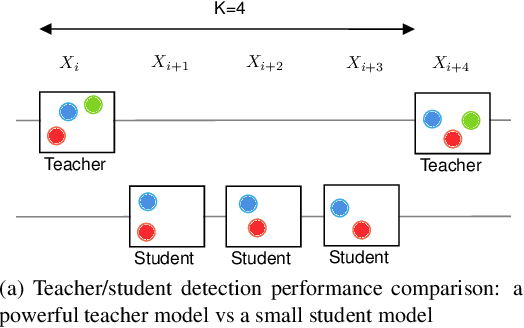

Multi-object tracking (MOT) is a vital component of intelligent video analytics applications such as surveillance and autonomous driving. The time and storage complexity required to execute deep learning models for visual object tracking hinder their adoption on embedded devices with limited computing power. In this paper, we aim to accelerate MOT by transferring the knowledge from high-level features of a complex network (teacher) to a lightweight network (student) at both training and inference times. The proposed AttTrack framework has three key components: 1) cross-model feature learning to align intermediate representations from the teacher and student models, 2) interleaving the execution of the two models at inference time, and 3) incorporating the updated predictions from the teacher model as prior knowledge to assist the student model. Experiments on pedestrian tracking tasks are conducted on the MOT17 and MOT15 datasets using two different object detection backbones YOLOv5 and DLA34 show that AttTrack can significantly improve student model tracking performance while sacrificing only minor degradation of tracking speed.
DeepScale: An Online Frame Size Adaptation Approach to Accelerate Visual Multi-object Tracking
Aug 18, 2021

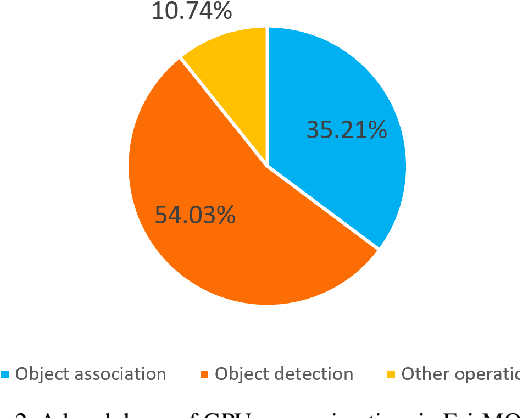
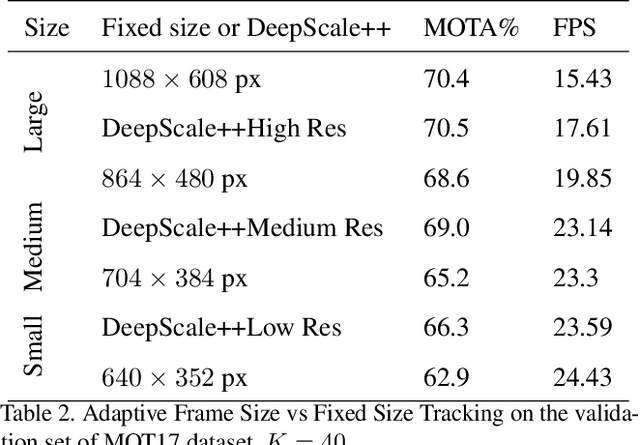
In surveillance and search and rescue applications, it is important to perform multi-target tracking (MOT) in real-time on low-end devices. Today's MOT solutions employ deep neural networks, which tend to have high computation complexity. Recognizing the effects of frame sizes on tracking performance, we propose DeepScale, a model agnostic frame size selection approach that operates on top of existing fully convolutional network-based trackers to accelerate tracking throughput. In the training stage, we incorporate detectability scores into a one-shot tracker architecture so that DeepScale can learn representation estimations for different frame sizes in a self-supervised manner. {During inference, it can adapt frame sizes according to the complexity of visual contents based on user-controlled parameters.} Extensive experiments and benchmark tests on MOT datasets demonstrate the effectiveness and flexibility of DeepScale. Compared to a state-of-the-art tracker, DeepScale++, a variant of DeepScale achieves 1.57X accelerated with only moderate degradation (~ 2.3%) in tracking accuracy on the MOT15 dataset in one configuration.