 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepScale: An Online Frame Size Adaptation Approach to Accelerate Visual Multi-object Tracking
Paper and Code
Aug 18, 2021

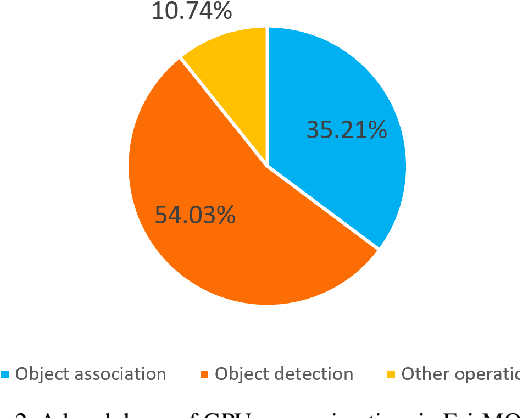
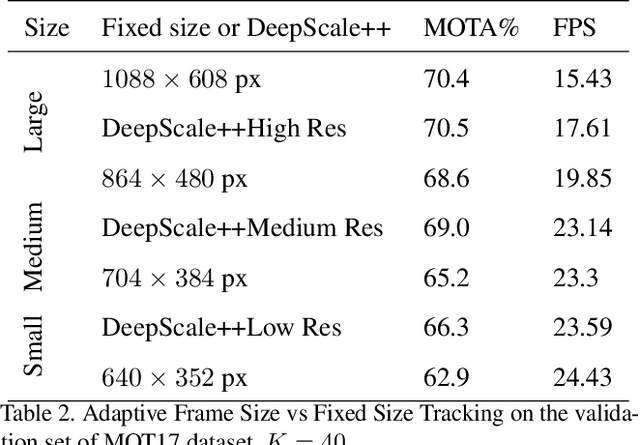
In surveillance and search and rescue applications, it is important to perform multi-target tracking (MOT) in real-time on low-end devices. Today's MOT solutions employ deep neural networks, which tend to have high computation complexity. Recognizing the effects of frame sizes on tracking performance, we propose DeepScale, a model agnostic frame size selection approach that operates on top of existing fully convolutional network-based trackers to accelerate tracking throughput. In the training stage, we incorporate detectability scores into a one-shot tracker architecture so that DeepScale can learn representation estimations for different frame sizes in a self-supervised manner. {During inference, it can adapt frame sizes according to the complexity of visual contents based on user-controlled parameters.} Extensive experiments and benchmark tests on MOT datasets demonstrate the effectiveness and flexibility of DeepScale. Compared to a state-of-the-art tracker, DeepScale++, a variant of DeepScale achieves 1.57X accelerated with only moderate degradation (~ 2.3%) in tracking accuracy on the MOT15 dataset in one configuration.