 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Action Recognition Using Confidence Distillation
Sep 05, 2021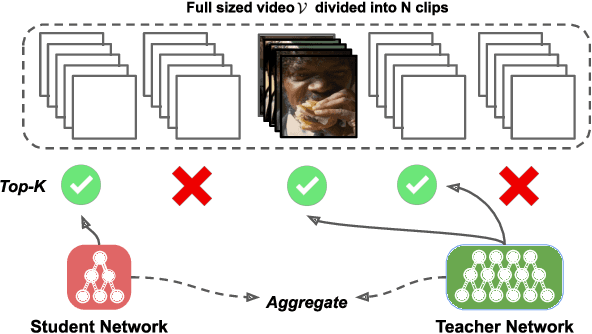

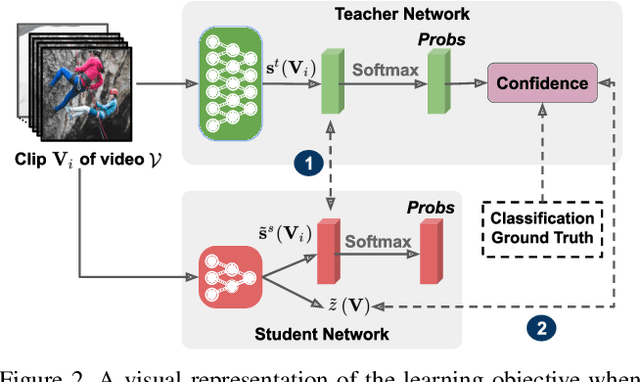
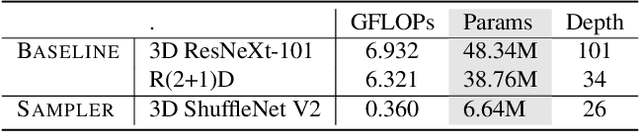
Modern neural networks are powerful predictive models. However, when it comes to recognizing that they may be wrong about their predictions, they perform poorly. For example, for one of the most common activation functions, the ReLU and its variants, even a well-calibrated model can produce incorrect but high confidence predictions. In the related task of action recognition, most current classification methods are based on clip-level classifiers that densely sample a given video for non-overlapping, same-sized clips and aggregate the results using an aggregation function - typically averaging - to achieve video level predictions. While this approach has shown to be effective, it is sub-optimal in recognition accuracy and has a high computational overhead. To mitigate both these issues, we propose the confidence distillation framework to teach a representation of uncertainty of the teacher to the student sampler and divide the task of full video prediction between the student and the teacher models. We conduct extensive experiments on three action recognition datasets and demonstrate that our framework achieves significant improvements in action recognition accuracy (up to 20%) and computational efficiency (more than 40%).
CacheNet: A Model Caching Framework for Deep Learning Inference on the Edge
Jul 03, 2020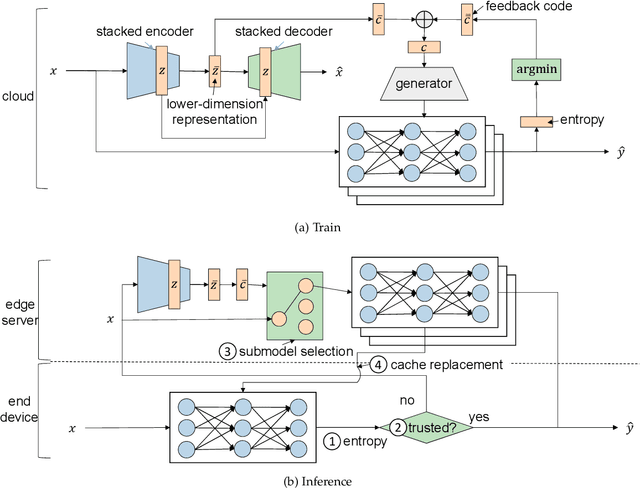
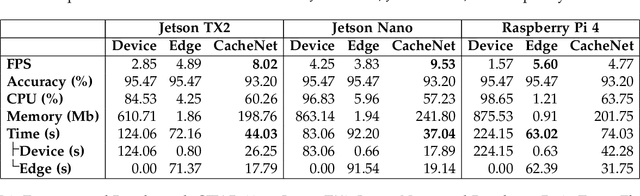
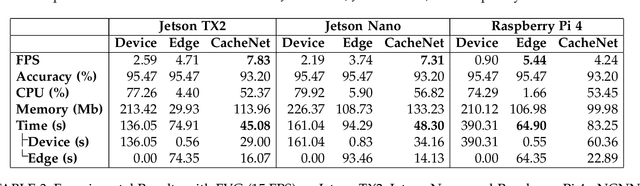
The success of deep neural networks (DNN) in machine perception applications such as image classification and speech recognition comes at the cost of high computation and storage complexity. Inference of uncompressed large scale DNN models can only run in the cloud with extra communication latency back and forth between cloud and end devices, while compressed DNN models achieve real-time inference on end devices at the price of lower predictive accuracy. In order to have the best of both worlds (latency and accuracy), we propose CacheNet, a model caching framework. CacheNet caches low-complexity models on end devices and high-complexity (or full) models on edge or cloud servers. By exploiting temporal locality in streaming data, high cache hit and consequently shorter latency can be achieved with no or only marginal decrease in prediction accuracy. Experiments on CIFAR-10 and FVG have shown CacheNet is 58-217% faster than baseline approaches that run inference tasks on end devices or edge servers alone.