 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-optimal neural boundary detection from unlabeled noisy images
May 30, 2026We study boundary detection for unlabeled noisy images from a statistical perspective. The aim is to recover an unknown object region from raw intensity observations without pixel-wise annotating labels or a parametric model for the intensity distributions. Motivated by robust Gibbs posterior approaches based on thresholded misclassification losses, we propose a continuous hinge-type surrogate loss for boundary detection. The proposed loss is amenable to gradient-based optimization and can be combined with deep neural networks to represent complex object boundaries. We prove that the proposed loss function is Fisher consistent under a mild separation assumption and obtain a calibration inequality linking excess surrogate risk to the symmetric difference error of the estimated region. Under a piecewise smooth boundary model, we prove that the resulting deep neural network estimator achieves the minimax-optimal boundary recovery rate, up to logarithmic factors. The piecewise smooth formulation accommodates boundaries with corners and kinks, thereby extending beyond globally smooth boundary models. Numerical experiments demonstrate that the proposed method accurately and stably recovers object boundaries across a range of noise levels and shape configurations, and compares favorably with existing unsupervised boundary detection methods.
Early-stopped aggregation: Adaptive inference with computational efficiency
Apr 15, 2026When considering a model selection or, more generally, an aggregation approach for adaptive statistical inference, it is often necessary to compute estimators over a wide range of model complexities including unnecessarily large models even when the true data-generating process is relatively simple, due to the lack of prior knowledge. This requirement can lead to substantial computational inefficiency. In this work, we propose a novel framework for efficient model aggregation called the early-stopped aggregation (ESA): instead of computing and aggregating estimators for all candidate models, we compute only a small number of simpler ones using an early-stopping criterion and aggregate only these for final inference. Our framework is versatile and applies to both Bayesian model selection, in particular, within the variational Bayes framework, and frequentist estimation, including a general penalized estimation setting. We investigate adaptive optimal property of the ESA approach across three learning paradigms. We first show that ESA achieves optimal adaptive contraction rates in the variational Bayes setting under mild conditions. We extend this result to variational empirical Bayes, where prior hyperparameters are chosen in a data-dependent manner. In addition, we apply the ESA approach to frequentist aggregation including both penalization-based and sample-splitting implementations, and establish corresponding theory. As we demonstrate, there is a clear unification between early-stopped Bayes and frequentist penalized aggregation, with a common "energy" functional comprising a data-fitting term and a complexity-control term that drives both procedures. We further present several applications and numerical studies that highlight the efficiency and strong performance of the proposed approach.
Online Conformal Inference with Retrospective Adjustment for Faster Adaptation to Distribution Shift
Nov 06, 2025



Conformal prediction has emerged as a powerful framework for constructing distribution-free prediction sets with guaranteed coverage assuming only the exchangeability assumption. However, this assumption is often violated in online environments where data distributions evolve over time. Several recent approaches have been proposed to address this limitation, but, typically, they slowly adapt to distribution shifts because they update predictions only in a forward manner, that is, they generate a prediction for a newly observed data point while previously computed predictions are not updated. In this paper, we propose a novel online conformal inference method with retrospective adjustment, which is designed to achieve faster adaptation to distributional shifts. Our method leverages regression approaches with efficient leave-one-out update formulas to retroactively adjust past predictions when new data arrive, thereby aligning the entire set of predictions with the most recent data distribution. Through extensive numerical studies performed on both synthetic and real-world data sets, we show that the proposed approach achieves faster coverage recalibration and improved statistical efficiency compared to existing online conformal prediction methods.
Knowledge Distillation of Uncertainty using Deep Latent Factor Model
Oct 22, 2025



Deep ensembles deliver state-of-the-art, reliable uncertainty quantification, but their heavy computational and memory requirements hinder their practical deployments to real applications such as on-device AI. Knowledge distillation compresses an ensemble into small student models, but existing techniques struggle to preserve uncertainty partly because reducing the size of DNNs typically results in variation reduction. To resolve this limitation, we introduce a new method of distribution distillation (i.e. compressing a teacher ensemble into a student distribution instead of a student ensemble) called Gaussian distillation, which estimates the distribution of a teacher ensemble through a special Gaussian process called the deep latent factor model (DLF) by treating each member of the teacher ensemble as a realization of a certain stochastic process. The mean and covariance functions in the DLF model are estimated stably by using the expectation-maximization (EM) algorithm. By using multiple benchmark datasets, we demonstrate that the proposed Gaussian distillation outperforms existing baselines. In addition, we illustrate that Gaussian distillation works well for fine-tuning of language models and distribution shift problems.
Nonparametric estimation of a factorizable density using diffusion models
Jan 03, 2025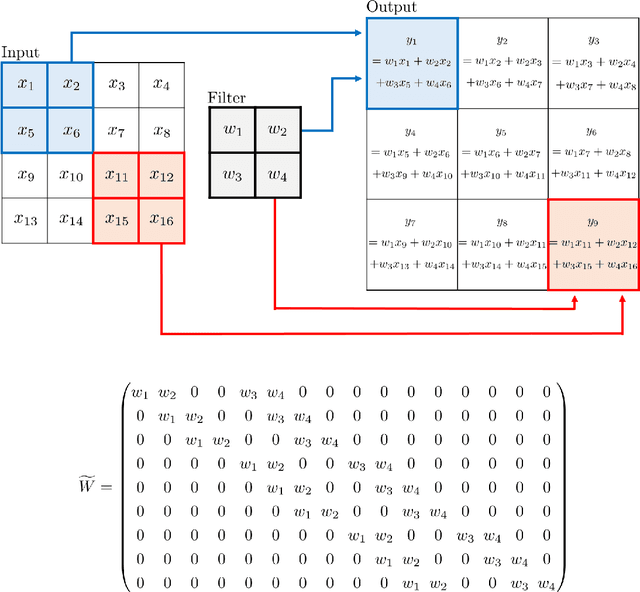
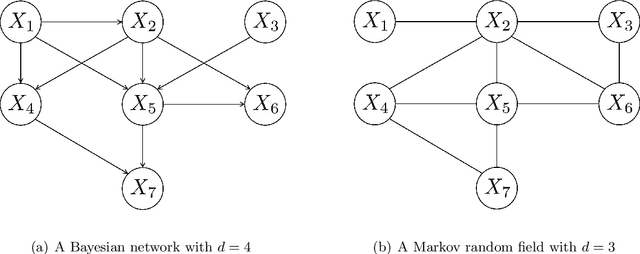
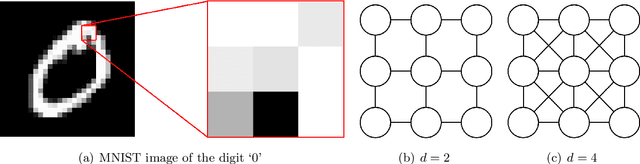
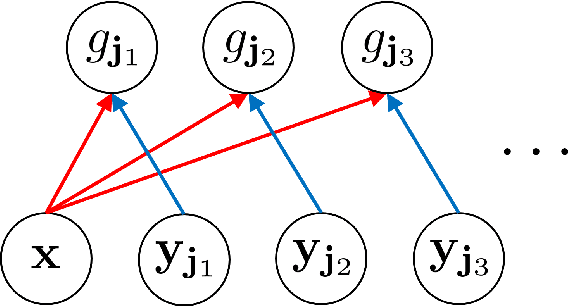
In recent years, diffusion models, and more generally score-based deep generative models, have achieved remarkable success in various applications, including image and audio generation. In this paper, we view diffusion models as an implicit approach to nonparametric density estimation and study them within a statistical framework to analyze their surprising performance. A key challenge in high-dimensional statistical inference is leveraging low-dimensional structures inherent in the data to mitigate the curse of dimensionality. We assume that the underlying density exhibits a low-dimensional structure by factorizing into low-dimensional components, a property common in examples such as Bayesian networks and Markov random fields. Under suitable assumptions, we demonstrate that an implicit density estimator constructed from diffusion models adapts to the factorization structure and achieves the minimax optimal rate with respect to the total variation distance. In constructing the estimator, we design a sparse weight-sharing neural network architecture, where sparsity and weight-sharing are key features of practical architectures such as convolutional neural networks and recurrent neural networks.
A Bayesian sparse factor model with adaptive posterior concentration
May 29, 2023In this paper, we propose a new Bayesian inference method for a high-dimensional sparse factor model that allows both the factor dimensionality and the sparse structure of the loading matrix to be inferred. The novelty is to introduce a certain dependence between the sparsity level and the factor dimensionality, which leads to adaptive posterior concentration while keeping computational tractability. We show that the posterior distribution asymptotically concentrates on the true factor dimensionality, and more importantly, this posterior consistency is adaptive to the sparsity level of the true loading matrix and the noise variance. We also prove that the proposed Bayesian model attains the optimal detection rate of the factor dimensionality in a more general situation than those found in the literature. Moreover, we obtain a near-optimal posterior concentration rate of the covariance matrix. Numerical studies are conducted and show the superiority of the proposed method compared with other competitors.
Masked Bayesian Neural Networks : Theoretical Guarantee and its Posterior Inference
May 24, 2023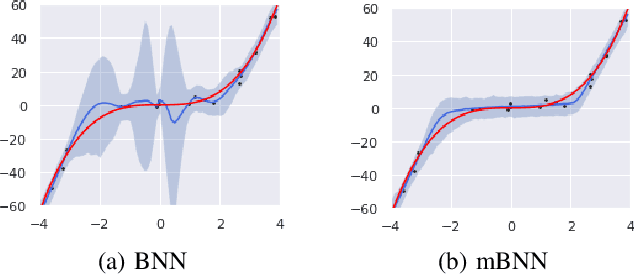
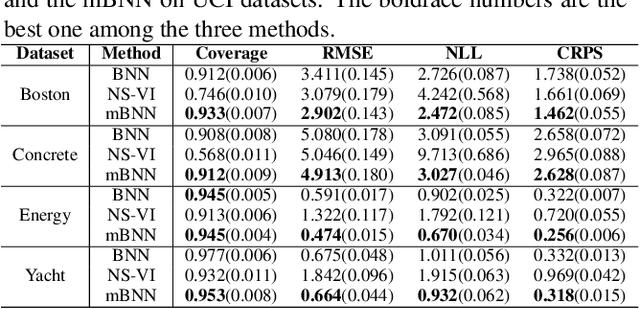
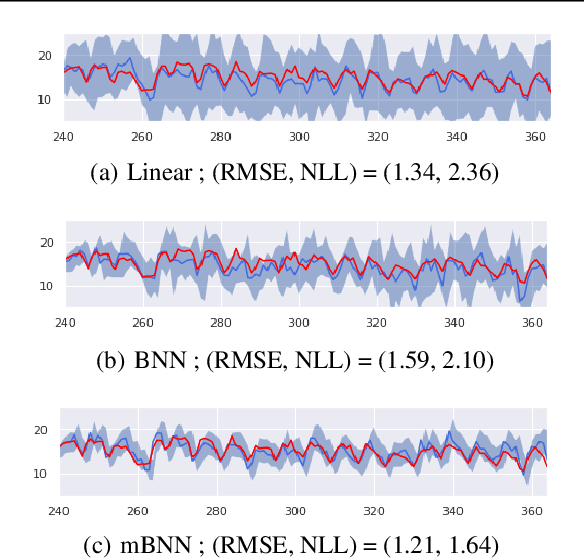
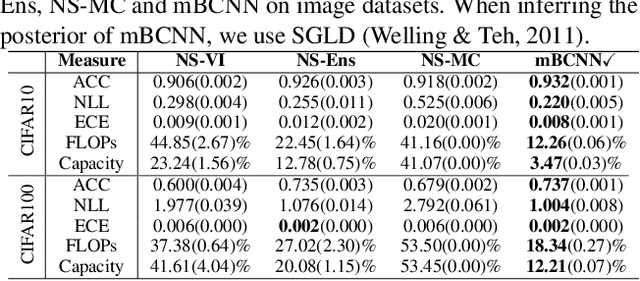
Bayesian approaches for learning deep neural networks (BNN) have been received much attention and successfully applied to various applications. Particularly, BNNs have the merit of having better generalization ability as well as better uncertainty quantification. For the success of BNN, search an appropriate architecture of the neural networks is an important task, and various algorithms to find good sparse neural networks have been proposed. In this paper, we propose a new node-sparse BNN model which has good theoretical properties and is computationally feasible. We prove that the posterior concentration rate to the true model is near minimax optimal and adaptive to the smoothness of the true model. In particular the adaptiveness is the first of its kind for node-sparse BNNs. In addition, we develop a novel MCMC algorithm which makes the Bayesian inference of the node-sparse BNN model feasible in practice.
Intrinsic and extrinsic deep learning on manifolds
Feb 16, 2023We propose extrinsic and intrinsic deep neural network architectures as general frameworks for deep learning on manifolds. Specifically, extrinsic deep neural networks (eDNNs) preserve geometric features on manifolds by utilizing an equivariant embedding from the manifold to its image in the Euclidean space. Moreover, intrinsic deep neural networks (iDNNs) incorporate the underlying intrinsic geometry of manifolds via exponential and log maps with respect to a Riemannian structure. Consequently, we prove that the empirical risk of the empirical risk minimizers (ERM) of eDNNs and iDNNs converge in optimal rates. Overall, The eDNNs framework is simple and easy to compute, while the iDNNs framework is accurate and fast converging. To demonstrate the utilities of our framework, various simulation studies, and real data analyses are presented with eDNNs and iDNNs.
The convergent Indian buffet process
Jun 16, 2022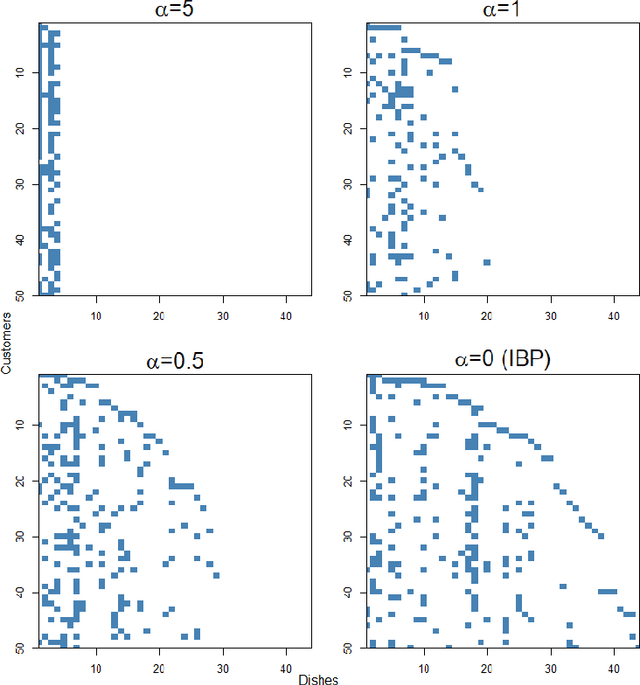
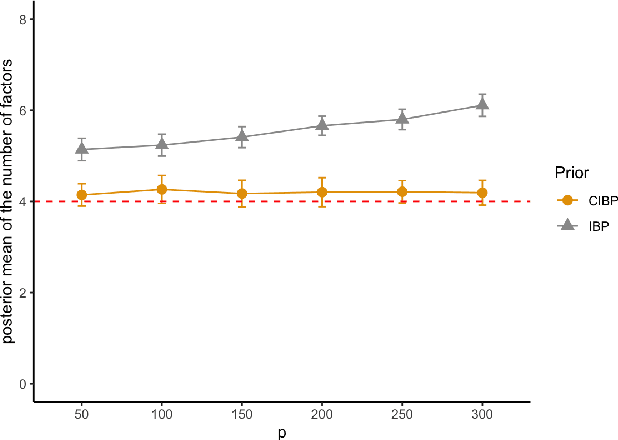
We propose a new Bayesian nonparametric prior for latent feature models, which we call the convergent Indian buffet process (CIBP). We show that under the CIBP, the number of latent features is distributed as a Poisson distribution with the mean monotonically increasing but converging to a certain value as the number of objects goes to infinity. That is, the expected number of features is bounded above even when the number of objects goes to infinity, unlike the standard Indian buffet process under which the expected number of features increases with the number of objects. We provide two alternative representations of the CIBP based on a hierarchical distribution and a completely random measure, respectively, which are of independent interest. The proposed CIBP is assessed on a high-dimensional sparse factor model.
Masked Bayesian Neural Networks : Computation and Optimality
Jun 02, 2022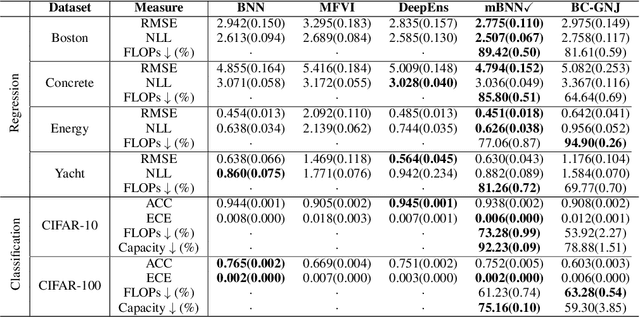
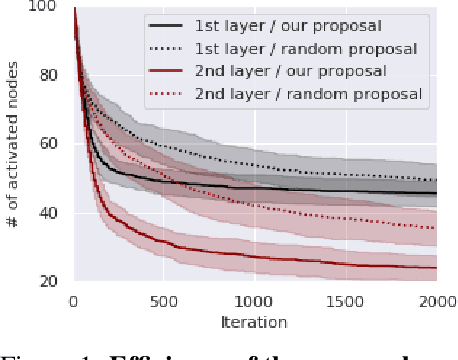
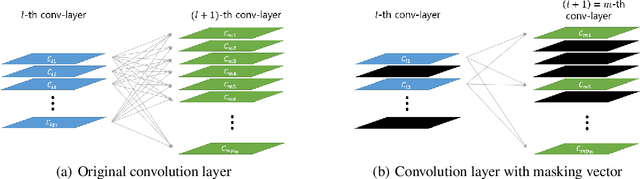
As data size and computing power increase, the architectures of deep neural networks (DNNs) have been getting more complex and huge, and thus there is a growing need to simplify such complex and huge DNNs. In this paper, we propose a novel sparse Bayesian neural network (BNN) which searches a good DNN with an appropriate complexity. We employ the masking variables at each node which can turn off some nodes according to the posterior distribution to yield a nodewise sparse DNN. We devise a prior distribution such that the posterior distribution has theoretical optimalities (i.e. minimax optimality and adaptiveness), and develop an efficient MCMC algorithm. By analyzing several benchmark datasets, we illustrate that the proposed BNN performs well compared to other existing methods in the sense that it discovers well condensed DNN architectures with similar prediction accuracy and uncertainty quantification compared to large DNNs.