 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation of Uncertainty using Deep Latent Factor Model
Oct 22, 2025



Deep ensembles deliver state-of-the-art, reliable uncertainty quantification, but their heavy computational and memory requirements hinder their practical deployments to real applications such as on-device AI. Knowledge distillation compresses an ensemble into small student models, but existing techniques struggle to preserve uncertainty partly because reducing the size of DNNs typically results in variation reduction. To resolve this limitation, we introduce a new method of distribution distillation (i.e. compressing a teacher ensemble into a student distribution instead of a student ensemble) called Gaussian distillation, which estimates the distribution of a teacher ensemble through a special Gaussian process called the deep latent factor model (DLF) by treating each member of the teacher ensemble as a realization of a certain stochastic process. The mean and covariance functions in the DLF model are estimated stably by using the expectation-maximization (EM) algorithm. By using multiple benchmark datasets, we demonstrate that the proposed Gaussian distillation outperforms existing baselines. In addition, we illustrate that Gaussian distillation works well for fine-tuning of language models and distribution shift problems.
Fairness Through Matching
Jan 06, 2025



Group fairness requires that different protected groups, characterized by a given sensitive attribute, receive equal outcomes overall. Typically, the level of group fairness is measured by the statistical gap between predictions from different protected groups. In this study, we reveal an implicit property of existing group fairness measures, which provides an insight into how the group-fair models behave. Then, we develop a new group-fair constraint based on this implicit property to learn group-fair models. To do so, we first introduce a notable theoretical observation: every group-fair model has an implicitly corresponding transport map between the input spaces of each protected group. Based on this observation, we introduce a new group fairness measure termed Matched Demographic Parity (MDP), which quantifies the averaged gap between predictions of two individuals (from different protected groups) matched by a given transport map. Then, we prove that any transport map can be used in MDP to learn group-fair models, and develop a novel algorithm called Fairness Through Matching (FTM), which learns a group-fair model using MDP constraint with an user-specified transport map. We specifically propose two favorable types of transport maps for MDP, based on the optimal transport theory, and discuss their advantages. Experiments reveal that FTM successfully trains group-fair models with certain desirable properties by choosing the transport map accordingly.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Masked Bayesian Neural Networks : Theoretical Guarantee and its Posterior Inference
May 24, 2023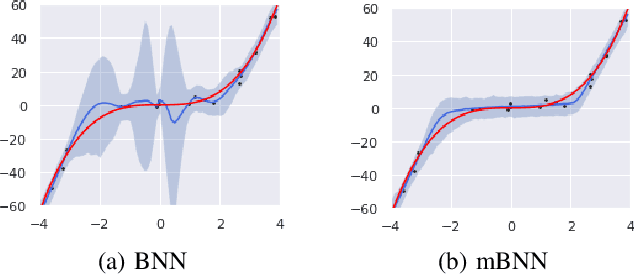
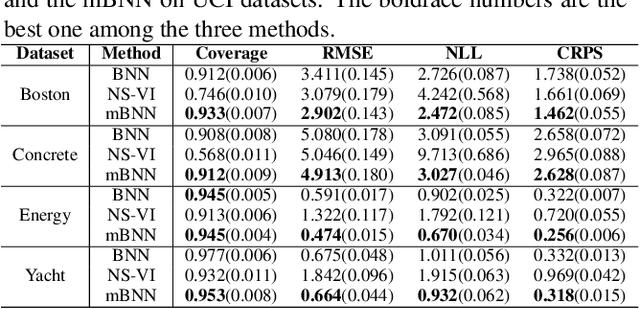
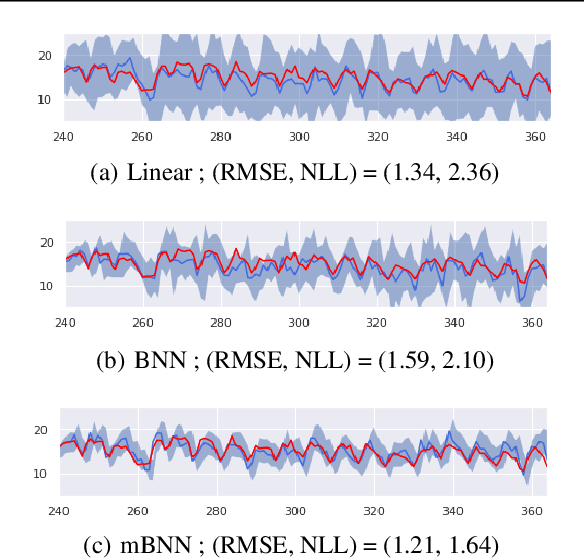
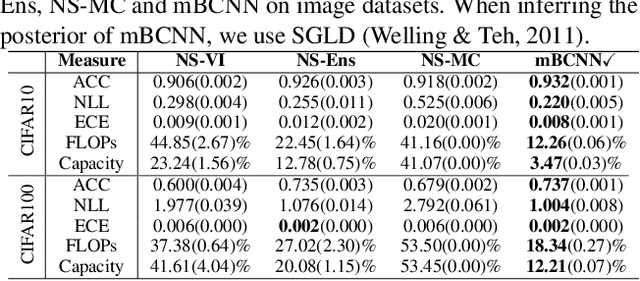
Bayesian approaches for learning deep neural networks (BNN) have been received much attention and successfully applied to various applications. Particularly, BNNs have the merit of having better generalization ability as well as better uncertainty quantification. For the success of BNN, search an appropriate architecture of the neural networks is an important task, and various algorithms to find good sparse neural networks have been proposed. In this paper, we propose a new node-sparse BNN model which has good theoretical properties and is computationally feasible. We prove that the posterior concentration rate to the true model is near minimax optimal and adaptive to the smoothness of the true model. In particular the adaptiveness is the first of its kind for node-sparse BNNs. In addition, we develop a novel MCMC algorithm which makes the Bayesian inference of the node-sparse BNN model feasible in practice.
ODIM: an efficient method to detect outliers via inlier-memorization effect of deep generative models
Jan 11, 2023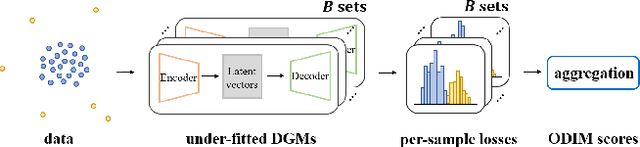
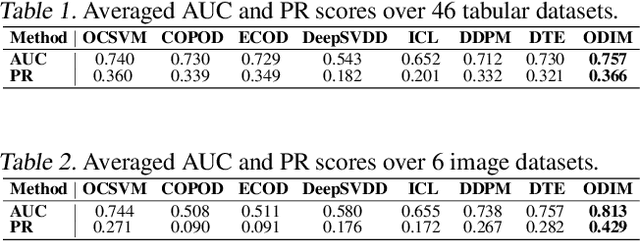

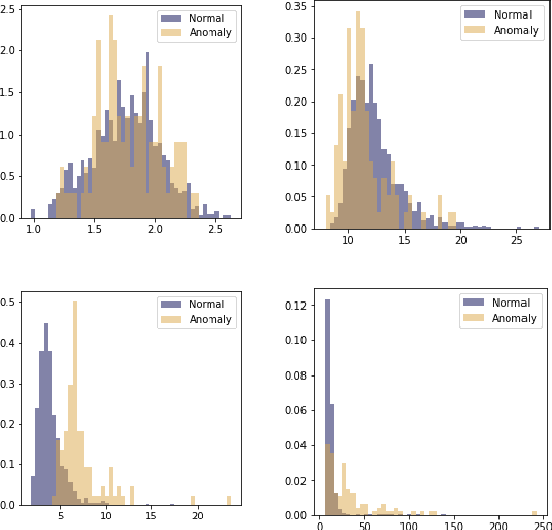
Identifying whether a given sample is an outlier or not is an important issue in various real-world domains. This study aims to solve the unsupervised outlier detection problem where training data contain outliers, but any label information about inliers and outliers is not given. We propose a powerful and efficient learning framework to identify outliers in a training data set using deep neural networks. We start with a new observation called the inlier-memorization (IM) effect. When we train a deep generative model with data contaminated with outliers, the model first memorizes inliers before outliers. Exploiting this finding, we develop a new method called the outlier detection via the IM effect (ODIM). The ODIM only requires a few updates; thus, it is computationally efficient, tens of times faster than other deep-learning-based algorithms. Also, the ODIM filters out outliers successfully, regardless of the types of data, such as tabular, image, and sequential. We empirically demonstrate the superiority and efficiency of the ODIM by analyzing 20 data sets.
Masked Bayesian Neural Networks : Computation and Optimality
Jun 02, 2022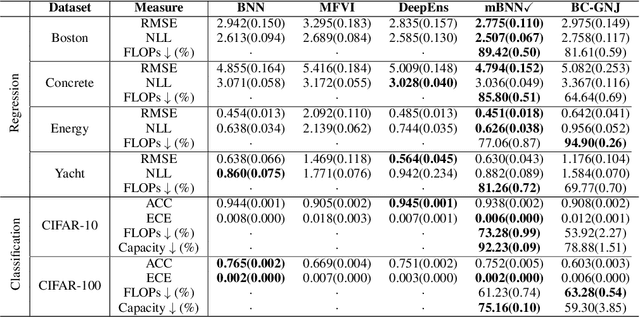
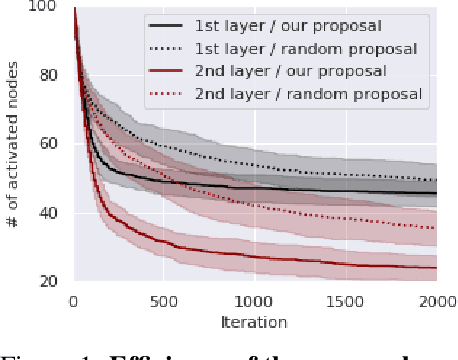
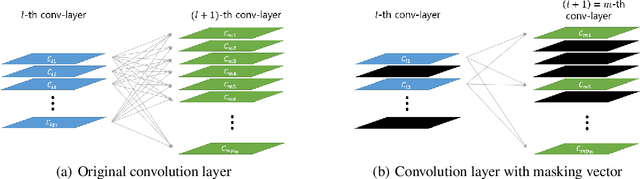
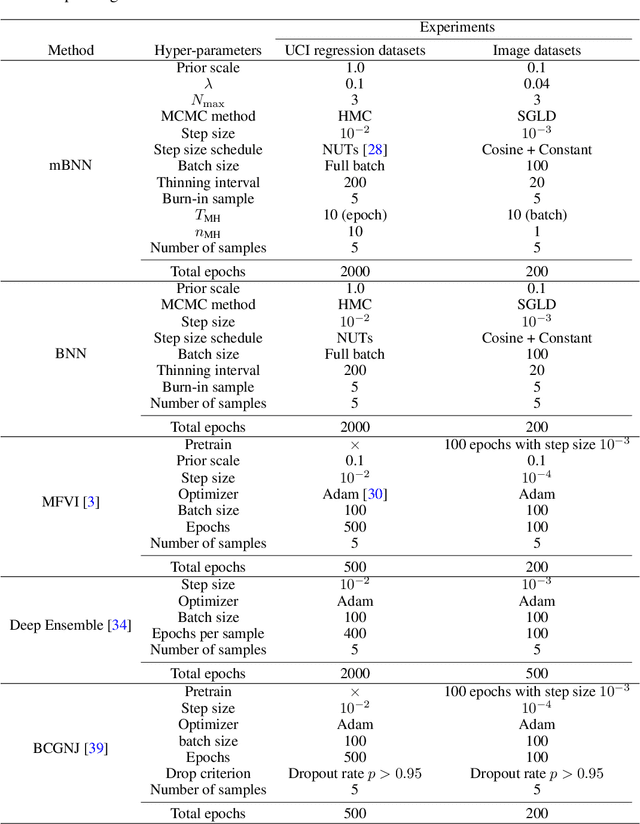
As data size and computing power increase, the architectures of deep neural networks (DNNs) have been getting more complex and huge, and thus there is a growing need to simplify such complex and huge DNNs. In this paper, we propose a novel sparse Bayesian neural network (BNN) which searches a good DNN with an appropriate complexity. We employ the masking variables at each node which can turn off some nodes according to the posterior distribution to yield a nodewise sparse DNN. We devise a prior distribution such that the posterior distribution has theoretical optimalities (i.e. minimax optimality and adaptiveness), and develop an efficient MCMC algorithm. By analyzing several benchmark datasets, we illustrate that the proposed BNN performs well compared to other existing methods in the sense that it discovers well condensed DNN architectures with similar prediction accuracy and uncertainty quantification compared to large DNNs.