 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsidering Length Diversity in Retrieval-Augmented Summarization
Mar 12, 2025
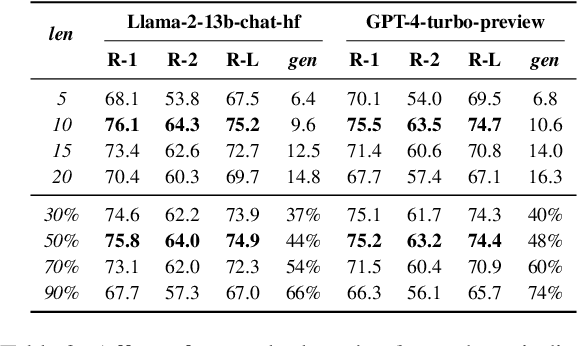
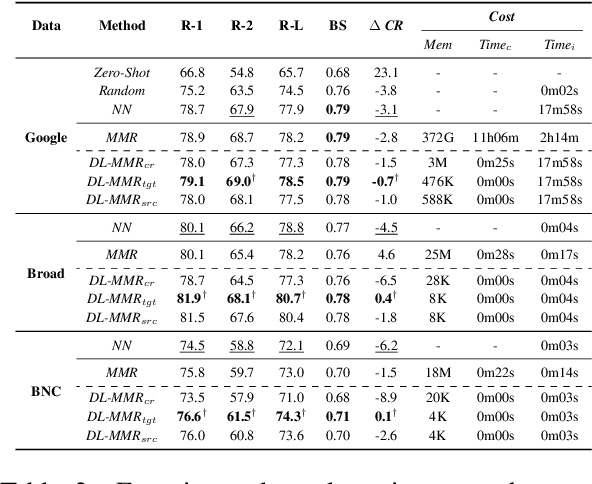
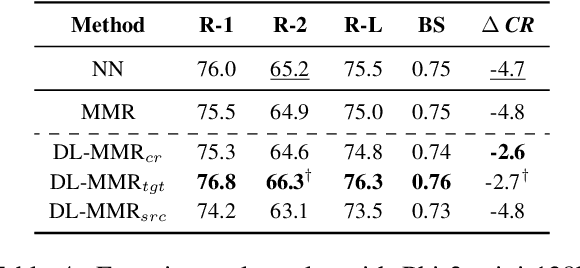
This study investigates retrieval-augmented summarization by specifically examining the impact of exemplar summary lengths under length constraints, not covered by previous work. We propose a Diverse Length-aware Maximal Marginal Relevance (DL-MMR) algorithm to better control summary lengths. This algorithm combines the query relevance with diverse target lengths in retrieval-augmented summarization. Unlike previous methods that necessitate exhaustive exemplar exemplar relevance comparisons using MMR, DL-MMR considers the exemplar target length as well and avoids comparing exemplars to each other, thereby reducing computational cost and conserving memory during the construction of an exemplar pool. Experimental results showed the effectiveness of DL-MMR, which considers length diversity, compared to the original MMR algorithm. DL-MMR additionally showed the effectiveness in memory saving of 781,513 times and computational cost reduction of 500,092 times, while maintaining the same level of informativeness.
ALTBI: Constructing Improved Outlier Detection Models via Optimization of Inlier-Memorization Effect
Aug 19, 2024Outlier detection (OD) is the task of identifying unusual observations (or outliers) from a given or upcoming data by learning unique patterns of normal observations (or inliers). Recently, a study introduced a powerful unsupervised OD (UOD) solver based on a new observation of deep generative models, called inlier-memorization (IM) effect, which suggests that generative models memorize inliers before outliers in early learning stages. In this study, we aim to develop a theoretically principled method to address UOD tasks by maximally utilizing the IM effect. We begin by observing that the IM effect is observed more clearly when the given training data contain fewer outliers. This finding indicates a potential for enhancing the IM effect in UOD regimes if we can effectively exclude outliers from mini-batches when designing the loss function. To this end, we introduce two main techniques: 1) increasing the mini-batch size as the model training proceeds and 2) using an adaptive threshold to calculate the truncated loss function. We theoretically show that these two techniques effectively filter out outliers from the truncated loss function, allowing us to utilize the IM effect to the fullest. Coupled with an additional ensemble strategy, we propose our method and term it Adaptive Loss Truncation with Batch Increment (ALTBI). We provide extensive experimental results to demonstrate that ALTBI achieves state-of-the-art performance in identifying outliers compared to other recent methods, even with significantly lower computation costs. Additionally, we show that our method yields robust performances when combined with privacy-preserving algorithms.
ODIM: an efficient method to detect outliers via inlier-memorization effect of deep generative models
Jan 11, 2023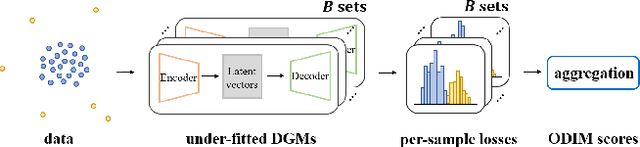
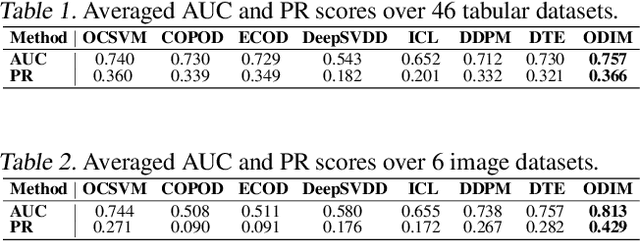

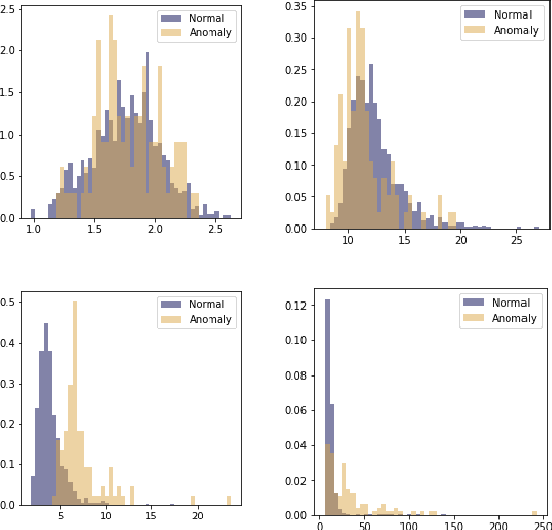
Identifying whether a given sample is an outlier or not is an important issue in various real-world domains. This study aims to solve the unsupervised outlier detection problem where training data contain outliers, but any label information about inliers and outliers is not given. We propose a powerful and efficient learning framework to identify outliers in a training data set using deep neural networks. We start with a new observation called the inlier-memorization (IM) effect. When we train a deep generative model with data contaminated with outliers, the model first memorizes inliers before outliers. Exploiting this finding, we develop a new method called the outlier detection via the IM effect (ODIM). The ODIM only requires a few updates; thus, it is computationally efficient, tens of times faster than other deep-learning-based algorithms. Also, the ODIM filters out outliers successfully, regardless of the types of data, such as tabular, image, and sequential. We empirically demonstrate the superiority and efficiency of the ODIM by analyzing 20 data sets.