 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsidering Length Diversity in Retrieval-Augmented Summarization
Mar 12, 2025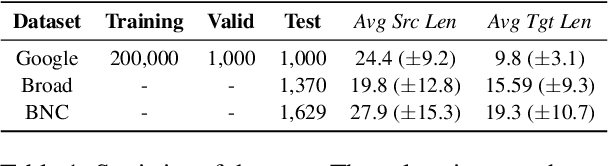
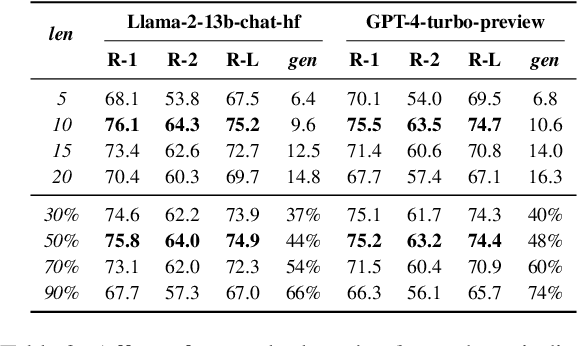
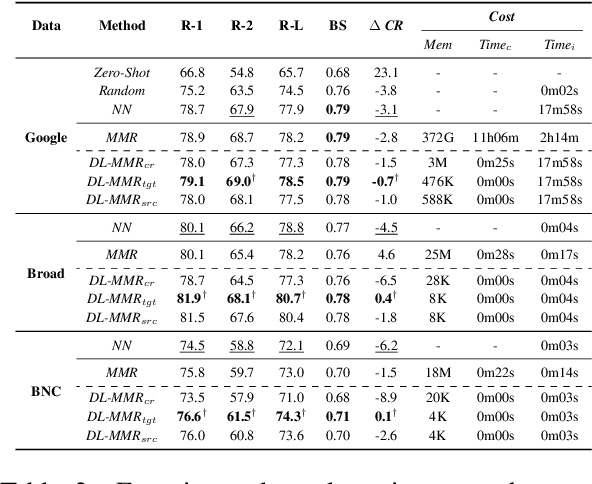
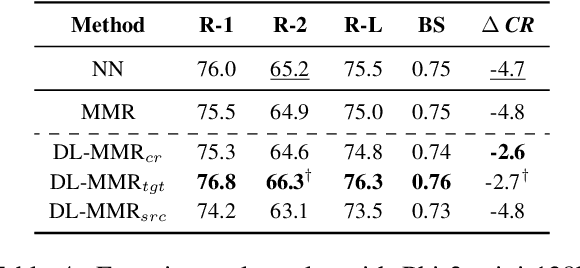
This study investigates retrieval-augmented summarization by specifically examining the impact of exemplar summary lengths under length constraints, not covered by previous work. We propose a Diverse Length-aware Maximal Marginal Relevance (DL-MMR) algorithm to better control summary lengths. This algorithm combines the query relevance with diverse target lengths in retrieval-augmented summarization. Unlike previous methods that necessitate exhaustive exemplar exemplar relevance comparisons using MMR, DL-MMR considers the exemplar target length as well and avoids comparing exemplars to each other, thereby reducing computational cost and conserving memory during the construction of an exemplar pool. Experimental results showed the effectiveness of DL-MMR, which considers length diversity, compared to the original MMR algorithm. DL-MMR additionally showed the effectiveness in memory saving of 781,513 times and computational cost reduction of 500,092 times, while maintaining the same level of informativeness.
InstructCMP: Length Control in Sentence Compression through Instruction-based Large Language Models
Jun 16, 2024Extractive summarization can produce faithful summaries but often requires additional constraints such as a desired summary length. Traditional sentence compression models do not typically consider the constraints because of their restricted model abilities, which require model modifications for coping with them. To bridge this gap, we propose Instruction-based Compression (InstructCMP), an approach to the sentence compression task that can consider the length constraint through instructions by leveraging the zero-shot task-solving abilities of Large Language Models (LLMs). For this purpose, we created new evaluation datasets by transforming traditional sentence compression datasets into an instruction format. By using the datasets, we first reveal that the current LLMs still face challenges in accurately controlling the length for a compressed text. To address this issue, we propose an approach named "length priming," that incorporates additional length information into the instructions without external resources. While the length priming effectively works in a zero-shot setting, a training dataset with the instructions would further improve the ability of length control. Thus, we additionally created a training dataset in an instruction format to fine-tune the model on it. Experimental results and analysis show that applying the length priming significantly improves performances of InstructCMP in both zero-shot and fine-tuning settings without the need of any model modifications.