 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLZero: A Multi-Agent System for End-to-end Machine Learning Automation
May 20, 2025Existing AutoML systems have advanced the automation of machine learning (ML); however, they still require substantial manual configuration and expert input, particularly when handling multimodal data. We introduce MLZero, a novel multi-agent framework powered by Large Language Models (LLMs) that enables end-to-end ML automation across diverse data modalities with minimal human intervention. A cognitive perception module is first employed, transforming raw multimodal inputs into perceptual context that effectively guides the subsequent workflow. To address key limitations of LLMs, such as hallucinated code generation and outdated API knowledge, we enhance the iterative code generation process with semantic and episodic memory. MLZero demonstrates superior performance on MLE-Bench Lite, outperforming all competitors in both success rate and solution quality, securing six gold medals. Additionally, when evaluated on our Multimodal AutoML Agent Benchmark, which includes 25 more challenging tasks spanning diverse data modalities, MLZero outperforms the competing methods by a large margin with a success rate of 0.92 (+263.6\%) and an average rank of 2.28. Our approach maintains its robust effectiveness even with a compact 8B LLM, outperforming full-size systems from existing solutions.
DSMentor: Enhancing Data Science Agents with Curriculum Learning and Online Knowledge Accumulation
May 20, 2025Large language model (LLM) agents have shown promising performance in generating code for solving complex data science problems. Recent studies primarily focus on enhancing in-context learning through improved search, sampling, and planning techniques, while overlooking the importance of the order in which problems are tackled during inference. In this work, we develop a novel inference-time optimization framework, referred to as DSMentor, which leverages curriculum learning -- a strategy that introduces simpler task first and progressively moves to more complex ones as the learner improves -- to enhance LLM agent performance in challenging data science tasks. Our mentor-guided framework organizes data science tasks in order of increasing difficulty and incorporates a growing long-term memory to retain prior experiences, guiding the agent's learning progression and enabling more effective utilization of accumulated knowledge. We evaluate DSMentor through extensive experiments on DSEval and QRData benchmarks. Experiments show that DSMentor using Claude-3.5-Sonnet improves the pass rate by up to 5.2% on DSEval and QRData compared to baseline agents. Furthermore, DSMentor demonstrates stronger causal reasoning ability, improving the pass rate by 8.8% on the causality problems compared to GPT-4 using Program-of-Thoughts prompts. Our work underscores the importance of developing effective strategies for accumulating and utilizing knowledge during inference, mirroring the human learning process and opening new avenues for improving LLM performance through curriculum-based inference optimization.
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
Jan 24, 2025



Recent advances in natural language processing have leveraged instruction tuning to enhance Large Language Models (LLMs) for table-related tasks. However, previous works train different base models with different training data, lacking an apples-to-apples comparison across the result table LLMs. To address this, we fine-tune base models from the Mistral, OLMo, and Phi families on existing public training datasets. Our replication achieves performance on par with or surpassing existing table LLMs, establishing new state-of-the-art performance on Hitab, a table question-answering dataset. More importantly, through systematic out-of-domain evaluation, we decouple the contributions of training data and the base model, providing insight into their individual impacts. In addition, we assess the effects of table-specific instruction tuning on general-purpose benchmarks, revealing trade-offs between specialization and generalization.
FeatNavigator: Automatic Feature Augmentation on Tabular Data
Jun 13, 2024Data-centric AI focuses on understanding and utilizing high-quality, relevant data in training machine learning (ML) models, thereby increasing the likelihood of producing accurate and useful results. Automatic feature augmentation, aiming to augment the initial base table with useful features from other tables, is critical in data preparation as it improves model performance, robustness, and generalizability. While recent works have investigated automatic feature augmentation, most of them have limited capabilities in utilizing all useful features as many of them are in candidate tables not directly joinable with the base table. Worse yet, with numerous join paths leading to these distant features, existing solutions fail to fully exploit them within a reasonable compute budget. We present FeatNavigator, an effective and efficient framework that explores and integrates high-quality features in relational tables for ML models. FeatNavigator evaluates a feature from two aspects: (1) the intrinsic value of a feature towards an ML task (i.e., feature importance) and (2) the efficacy of a join path connecting the feature to the base table (i.e., integration quality). FeatNavigator strategically selects a small set of available features and their corresponding join paths to train a feature importance estimation model and an integration quality prediction model. Furthermore, FeatNavigator's search algorithm exploits both estimated feature importance and integration quality to identify the optimized feature augmentation plan. Our experimental results show that FeatNavigator outperforms state-of-the-art solutions on five public datasets by up to 40.1% in ML model performance.
Hierarchical Compression of Text-Rich Graphs via Large Language Models
Jun 13, 2024

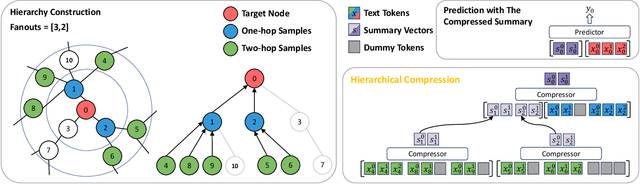
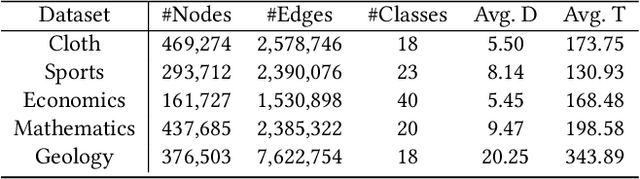
Text-rich graphs, prevalent in data mining contexts like e-commerce and academic graphs, consist of nodes with textual features linked by various relations. Traditional graph machine learning models, such as Graph Neural Networks (GNNs), excel in encoding the graph structural information, but have limited capability in handling rich text on graph nodes. Large Language Models (LLMs), noted for their superior text understanding abilities, offer a solution for processing the text in graphs but face integration challenges due to their limitation for encoding graph structures and their computational complexities when dealing with extensive text in large neighborhoods of interconnected nodes. This paper introduces ``Hierarchical Compression'' (HiCom), a novel method to align the capabilities of LLMs with the structure of text-rich graphs. HiCom processes text in a node's neighborhood in a structured manner by organizing the extensive textual information into a more manageable hierarchy and compressing node text step by step. Therefore, HiCom not only preserves the contextual richness of the text but also addresses the computational challenges of LLMs, which presents an advancement in integrating the text processing power of LLMs with the structural complexities of text-rich graphs. Empirical results show that HiCom can outperform both GNNs and LLM backbones for node classification on e-commerce and citation graphs. HiCom is especially effective for nodes from a dense region in a graph, where it achieves a 3.48% average performance improvement on five datasets while being more efficient than LLM backbones.
KGExplainer: Towards Exploring Connected Subgraph Explanations for Knowledge Graph Completion
Apr 05, 2024


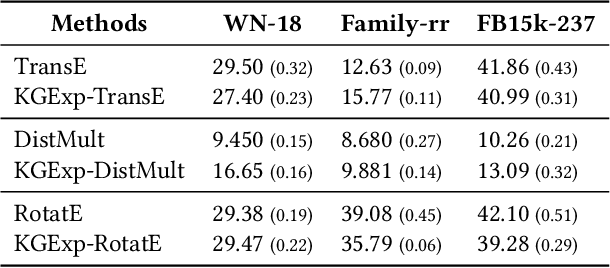
Knowledge graph completion (KGC) aims to alleviate the inherent incompleteness of knowledge graphs (KGs), which is a critical task for various applications, such as recommendations on the web. Although knowledge graph embedding (KGE) models have demonstrated superior predictive performance on KGC tasks, these models infer missing links in a black-box manner that lacks transparency and accountability, preventing researchers from developing accountable models. Existing KGE-based explanation methods focus on exploring key paths or isolated edges as explanations, which is information-less to reason target prediction. Additionally, the missing ground truth leads to these explanation methods being ineffective in quantitatively evaluating explored explanations. To overcome these limitations, we propose KGExplainer, a model-agnostic method that identifies connected subgraph explanations and distills an evaluator to assess them quantitatively. KGExplainer employs a perturbation-based greedy search algorithm to find key connected subgraphs as explanations within the local structure of target predictions. To evaluate the quality of the explored explanations, KGExplainer distills an evaluator from the target KGE model. By forwarding the explanations to the evaluator, our method can examine the fidelity of them. Extensive experiments on benchmark datasets demonstrate that KGExplainer yields promising improvement and achieves an optimal ratio of 83.3% in human evaluation.
Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
Mar 01, 2024Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
OpenTab: Advancing Large Language Models as Open-domain Table Reasoners
Feb 22, 2024



Large Language Models (LLMs) trained on large volumes of data excel at various natural language tasks, but they cannot handle tasks requiring knowledge that has not been trained on previously. One solution is to use a retriever that fetches relevant information to expand LLM's knowledge scope. However, existing textual-oriented retrieval-based LLMs are not ideal on structured table data due to diversified data modalities and large table sizes. In this work, we propose OpenTab, an open-domain table reasoning framework powered by LLMs. Overall, OpenTab leverages table retriever to fetch relevant tables and then generates SQL programs to parse the retrieved tables efficiently. Utilizing the intermediate data derived from the SQL executions, it conducts grounded inference to produce accurate response. Extensive experimental evaluation shows that OpenTab significantly outperforms baselines in both open- and closed-domain settings, achieving up to 21.5% higher accuracy. We further run ablation studies to validate the efficacy of our proposed designs of the system.
Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection
Oct 30, 2023Large Language Models (LLMs) can adapt to new tasks via in-context learning (ICL). ICL is efficient as it does not require any parameter updates to the trained LLM, but only few annotated examples as input for the LLM. In this work, we investigate an active learning approach for ICL, where there is a limited budget for annotating examples. We propose a model-adaptive optimization-free algorithm, termed AdaICL, which identifies examples that the model is uncertain about, and performs semantic diversity-based example selection. Diversity-based sampling improves overall effectiveness, while uncertainty sampling improves budget efficiency and helps the LLM learn new information. Moreover, AdaICL poses its sampling strategy as a Maximum Coverage problem, that dynamically adapts based on the model's feedback and can be approximately solved via greedy algorithms. Extensive experiments on nine datasets and seven LLMs show that AdaICL improves performance by 4.4% accuracy points over SOTA (7.7% relative improvement), is up to 3x more budget-efficient than performing annotations uniformly at random, while it outperforms SOTA with 2x fewer ICL examples.
NameGuess: Column Name Expansion for Tabular Data
Oct 19, 2023Recent advances in large language models have revolutionized many sectors, including the database industry. One common challenge when dealing with large volumes of tabular data is the pervasive use of abbreviated column names, which can negatively impact performance on various data search, access, and understanding tasks. To address this issue, we introduce a new task, called NameGuess, to expand column names (used in database schema) as a natural language generation problem. We create a training dataset of 384K abbreviated-expanded column pairs using a new data fabrication method and a human-annotated evaluation benchmark that includes 9.2K examples from real-world tables. To tackle the complexities associated with polysemy and ambiguity in NameGuess, we enhance auto-regressive language models by conditioning on table content and column header names -- yielding a fine-tuned model (with 2.7B parameters) that matches human performance. Furthermore, we conduct a comprehensive analysis (on multiple LLMs) to validate the effectiveness of table content in NameGuess and identify promising future opportunities. Code has been made available at https://github.com/amazon-science/nameguess.