 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesFlow: A Probability Inference Framework for Meta-Agent Assisted Workflow Generation
Jan 29, 2026Automatic workflow generation is the process of automatically synthesizing sequences of LLM calls, tool invocations, and post-processing steps for complex end-to-end tasks. Most prior methods cast this task as an optimization problem with limited theoretical grounding. We propose to cast workflow generation as Bayesian inference over a posterior distribution on workflows, and introduce \textbf{Bayesian Workflow Generation (BWG)}, a sampling framework that builds workflows step-by-step using parallel look-ahead rollouts for importance weighting and a sequential in-loop refiner for pool-wide improvements. We prove that, without the refiner, the weighted empirical distribution converges to the target posterior. We instantiate BWG as \textbf{BayesFlow}, a training-free algorithm for workflow construction. Across six benchmark datasets, BayesFlow improves accuracy by up to 9 percentage points over SOTA workflow generation baselines and by up to 65 percentage points over zero-shot prompting, establishing BWG as a principled upgrade to search-based workflow design. Code will be available on https://github.com/BoYuanVisionary/BayesFlow.
Diffusion Language Model Inference with Monte Carlo Tree Search
Dec 13, 2025Diffusion language models (DLMs) have recently emerged as a compelling alternative to autoregressive generation, offering parallel generation and improved global coherence. During inference, DLMs generate text by iteratively denoising masked sequences in parallel; however, determining which positions to unmask and which tokens to commit forms a large combinatorial search problem. Existing inference methods approximate this search using heuristics, which often yield suboptimal decoding paths; other approaches instead rely on additional training to guide token selection. To introduce a principled search mechanism for DLMs inference, we introduce MEDAL, a framework that integrates Monte Carlo Tree SEarch initialization for Diffusion LAnguage Model inference. We employ Monte Carlo Tree Search at the initialization stage to explore promising unmasking trajectories, providing a robust starting point for subsequent refinement. This integration is enabled by restricting the search space to high-confidence actions and prioritizing token choices that improve model confidence over remaining masked positions. Across multiple benchmarks, MEDAL achieves up to 22.0% improvement over existing inference strategies, establishing a new paradigm for search-based inference in diffusion language models.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
OpenTab: Advancing Large Language Models as Open-domain Table Reasoners
Feb 22, 2024



Large Language Models (LLMs) trained on large volumes of data excel at various natural language tasks, but they cannot handle tasks requiring knowledge that has not been trained on previously. One solution is to use a retriever that fetches relevant information to expand LLM's knowledge scope. However, existing textual-oriented retrieval-based LLMs are not ideal on structured table data due to diversified data modalities and large table sizes. In this work, we propose OpenTab, an open-domain table reasoning framework powered by LLMs. Overall, OpenTab leverages table retriever to fetch relevant tables and then generates SQL programs to parse the retrieved tables efficiently. Utilizing the intermediate data derived from the SQL executions, it conducts grounded inference to produce accurate response. Extensive experimental evaluation shows that OpenTab significantly outperforms baselines in both open- and closed-domain settings, achieving up to 21.5% higher accuracy. We further run ablation studies to validate the efficacy of our proposed designs of the system.
Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection
Oct 30, 2023Large Language Models (LLMs) can adapt to new tasks via in-context learning (ICL). ICL is efficient as it does not require any parameter updates to the trained LLM, but only few annotated examples as input for the LLM. In this work, we investigate an active learning approach for ICL, where there is a limited budget for annotating examples. We propose a model-adaptive optimization-free algorithm, termed AdaICL, which identifies examples that the model is uncertain about, and performs semantic diversity-based example selection. Diversity-based sampling improves overall effectiveness, while uncertainty sampling improves budget efficiency and helps the LLM learn new information. Moreover, AdaICL poses its sampling strategy as a Maximum Coverage problem, that dynamically adapts based on the model's feedback and can be approximately solved via greedy algorithms. Extensive experiments on nine datasets and seven LLMs show that AdaICL improves performance by 4.4% accuracy points over SOTA (7.7% relative improvement), is up to 3x more budget-efficient than performing annotations uniformly at random, while it outperforms SOTA with 2x fewer ICL examples.
NameGuess: Column Name Expansion for Tabular Data
Oct 19, 2023Recent advances in large language models have revolutionized many sectors, including the database industry. One common challenge when dealing with large volumes of tabular data is the pervasive use of abbreviated column names, which can negatively impact performance on various data search, access, and understanding tasks. To address this issue, we introduce a new task, called NameGuess, to expand column names (used in database schema) as a natural language generation problem. We create a training dataset of 384K abbreviated-expanded column pairs using a new data fabrication method and a human-annotated evaluation benchmark that includes 9.2K examples from real-world tables. To tackle the complexities associated with polysemy and ambiguity in NameGuess, we enhance auto-regressive language models by conditioning on table content and column header names -- yielding a fine-tuned model (with 2.7B parameters) that matches human performance. Furthermore, we conduct a comprehensive analysis (on multiple LLMs) to validate the effectiveness of table content in NameGuess and identify promising future opportunities. Code has been made available at https://github.com/amazon-science/nameguess.
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Oct 14, 2023

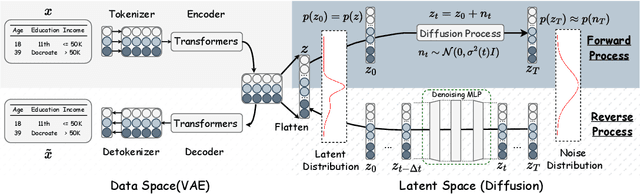

Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces TABSYN, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed TABSYN include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that TABSYN outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
BioBridge: Bridging Biomedical Foundation Models via Knowledge Graph
Oct 12, 2023Foundation models (FMs) are able to leverage large volumes of unlabeled data to demonstrate superior performance across a wide range of tasks. However, FMs developed for biomedical domains have largely remained unimodal, i.e., independently trained and used for tasks on protein sequences alone, small molecule structures alone, or clinical data alone. To overcome this limitation of biomedical FMs, we present BioBridge, a novel parameter-efficient learning framework, to bridge independently trained unimodal FMs to establish multimodal behavior. BioBridge achieves it by utilizing Knowledge Graphs (KG) to learn transformations between one unimodal FM and another without fine-tuning any underlying unimodal FMs. Our empirical results demonstrate that BioBridge can beat the best baseline KG embedding methods (on average by around 76.3%) in cross-modal retrieval tasks. We also identify BioBridge demonstrates out-of-domain generalization ability by extrapolating to unseen modalities or relations. Additionally, we also show that BioBridge presents itself as a general purpose retriever that can aid biomedical multimodal question answering as well as enhance the guided generation of novel drugs.
HYTREL: Hypergraph-enhanced Tabular Data Representation Learning
Jul 14, 2023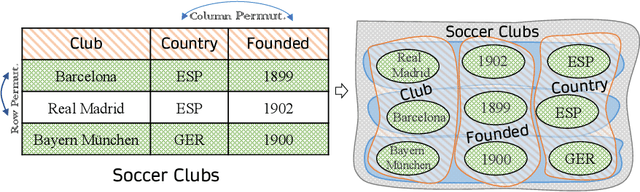
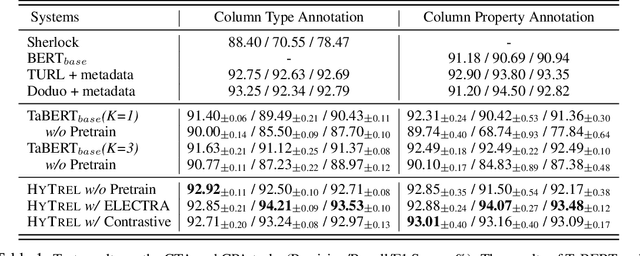
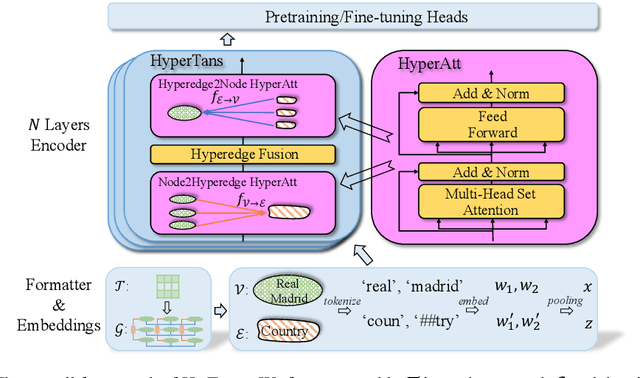
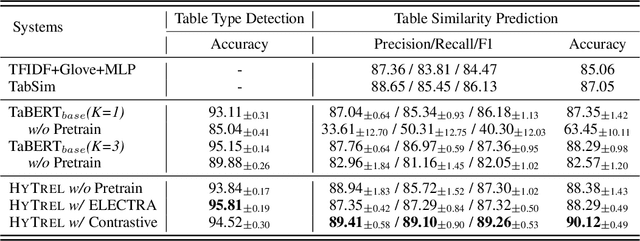
Language models pretrained on large collections of tabular data have demonstrated their effectiveness in several downstream tasks. However, many of these models do not take into account the row/column permutation invariances, hierarchical structure, etc. that exist in tabular data. To alleviate these limitations, we propose HYTREL, a tabular language model, that captures the permutation invariances and three more structural properties of tabular data by using hypergraphs - where the table cells make up the nodes and the cells occurring jointly together in each row, column, and the entire table are used to form three different types of hyperedges. We show that HYTREL is maximally invariant under certain conditions for tabular data, i.e., two tables obtain the same representations via HYTREL iff the two tables are identical up to permutations. Our empirical results demonstrate that HYTREL consistently outperforms other competitive baselines on four downstream tasks with minimal pretraining, illustrating the advantages of incorporating the inductive biases associated with tabular data into the representations. Finally, our qualitative analyses showcase that HYTREL can assimilate the table structures to generate robust representations for the cells, rows, columns, and the entire table.
Equivariant Subgraph Aggregation Networks
Oct 06, 2021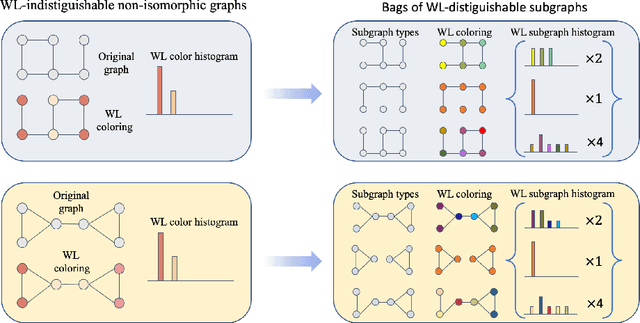
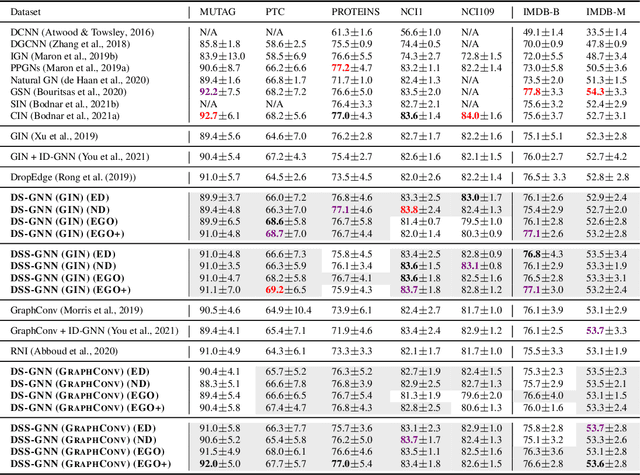
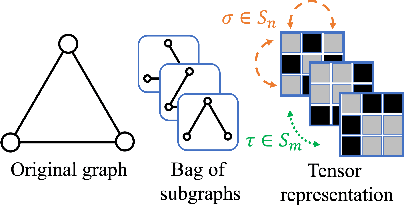
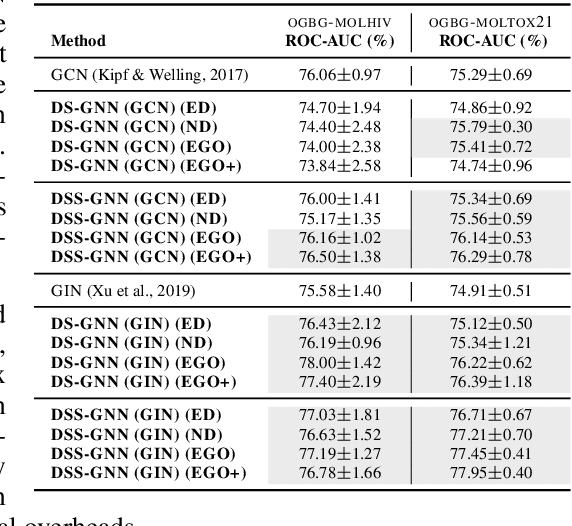
Message-passing neural networks (MPNNs) are the leading architecture for deep learning on graph-structured data, in large part due to their simplicity and scalability. Unfortunately, it was shown that these architectures are limited in their expressive power. This paper proposes a novel framework called Equivariant Subgraph Aggregation Networks (ESAN) to address this issue. Our main observation is that while two graphs may not be distinguishable by an MPNN, they often contain distinguishable subgraphs. Thus, we propose to represent each graph as a set of subgraphs derived by some predefined policy, and to process it using a suitable equivariant architecture. We develop novel variants of the 1-dimensional Weisfeiler-Leman (1-WL) test for graph isomorphism, and prove lower bounds on the expressiveness of ESAN in terms of these new WL variants. We further prove that our approach increases the expressive power of both MPNNs and more expressive architectures. Moreover, we provide theoretical results that describe how design choices such as the subgraph selection policy and equivariant neural architecture affect our architecture's expressive power. To deal with the increased computational cost, we propose a subgraph sampling scheme, which can be viewed as a stochastic version of our framework. A comprehensive set of experiments on real and synthetic datasets demonstrates that our framework improves the expressive power and overall performance of popular GNN architectures.