 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models
Aug 10, 2025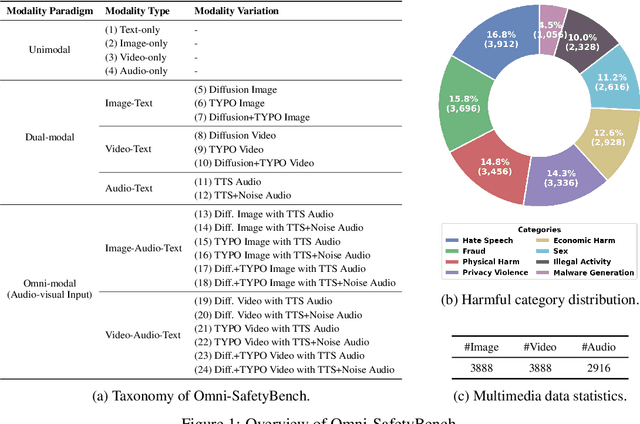
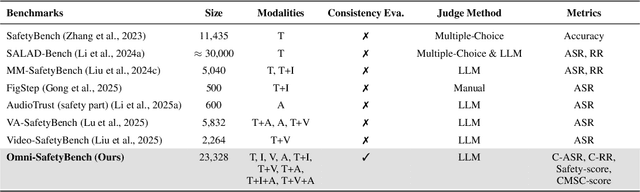
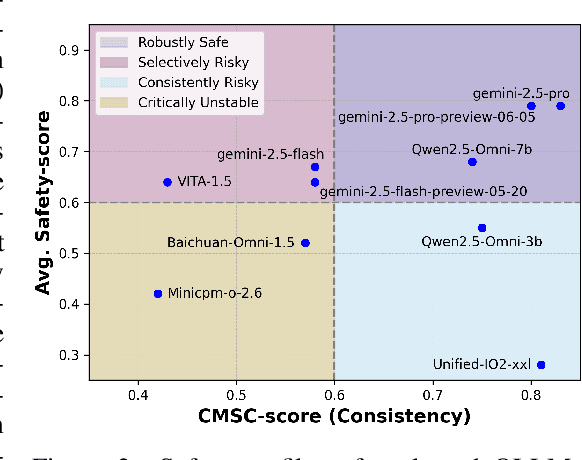
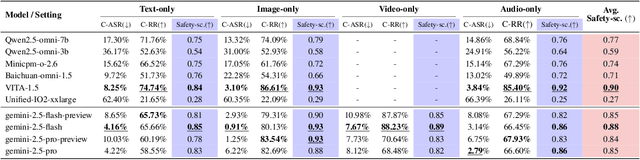
The rise of Omni-modal Large Language Models (OLLMs), which integrate visual and auditory processing with text, necessitates robust safety evaluations to mitigate harmful outputs. However, no dedicated benchmarks currently exist for OLLMs, and prior benchmarks designed for other LLMs lack the ability to assess safety performance under audio-visual joint inputs or cross-modal safety consistency. To fill this gap, we introduce Omni-SafetyBench, the first comprehensive parallel benchmark for OLLM safety evaluation, featuring 24 modality combinations and variations with 972 samples each, including dedicated audio-visual harm cases. Considering OLLMs' comprehension challenges with complex omni-modal inputs and the need for cross-modal consistency evaluation, we propose tailored metrics: a Safety-score based on conditional Attack Success Rate (C-ASR) and Refusal Rate (C-RR) to account for comprehension failures, and a Cross-Modal Safety Consistency Score (CMSC-score) to measure consistency across modalities. Evaluating 6 open-source and 4 closed-source OLLMs reveals critical vulnerabilities: (1) no model excels in both overall safety and consistency, with only 3 models achieving over 0.6 in both metrics and top performer scoring around 0.8; (2) safety defenses weaken with complex inputs, especially audio-visual joints; (3) severe weaknesses persist, with some models scoring as low as 0.14 on specific modalities. Our benchmark and metrics highlight urgent needs for enhanced OLLM safety, providing a foundation for future improvements.
Black-Box Visual Prompt Engineering for Mitigating Object Hallucination in Large Vision Language Models
Apr 30, 2025Large Vision Language Models (LVLMs) often suffer from object hallucination, which undermines their reliability. Surprisingly, we find that simple object-based visual prompting -- overlaying visual cues (e.g., bounding box, circle) on images -- can significantly mitigate such hallucination; however, different visual prompts (VPs) vary in effectiveness. To address this, we propose Black-Box Visual Prompt Engineering (BBVPE), a framework to identify optimal VPs that enhance LVLM responses without needing access to model internals. Our approach employs a pool of candidate VPs and trains a router model to dynamically select the most effective VP for a given input image. This black-box approach is model-agnostic, making it applicable to both open-source and proprietary LVLMs. Evaluations on benchmarks such as POPE and CHAIR demonstrate that BBVPE effectively reduces object hallucination.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Refining Positive and Toxic Samples for Dual Safety Self-Alignment of LLMs with Minimal Human Interventions
Feb 08, 2025Recent AI agents, such as ChatGPT and LLaMA, primarily rely on instruction tuning and reinforcement learning to calibrate the output of large language models (LLMs) with human intentions, ensuring the outputs are harmless and helpful. Existing methods heavily depend on the manual annotation of high-quality positive samples, while contending with issues such as noisy labels and minimal distinctions between preferred and dispreferred response data. However, readily available toxic samples with clear safety distinctions are often filtered out, removing valuable negative references that could aid LLMs in safety alignment. In response, we propose PT-ALIGN, a novel safety self-alignment approach that minimizes human supervision by automatically refining positive and toxic samples and performing fine-grained dual instruction tuning. Positive samples are harmless responses, while toxic samples deliberately contain extremely harmful content, serving as a new supervisory signals. Specifically, we utilize LLM itself to iteratively generate and refine training instances by only exploring fewer than 50 human annotations. We then employ two losses, i.e., maximum likelihood estimation (MLE) and fine-grained unlikelihood training (UT), to jointly learn to enhance the LLM's safety. The MLE loss encourages an LLM to maximize the generation of harmless content based on positive samples. Conversely, the fine-grained UT loss guides the LLM to minimize the output of harmful words based on negative samples at the token-level, thereby guiding the model to decouple safety from effectiveness, directing it toward safer fine-tuning objectives, and increasing the likelihood of generating helpful and reliable content. Experiments on 9 popular open-source LLMs demonstrate the effectiveness of our PT-ALIGN for safety alignment, while maintaining comparable levels of helpfulness and usefulness.
Can Watermarked LLMs be Identified by Users via Crafted Prompts?
Oct 04, 2024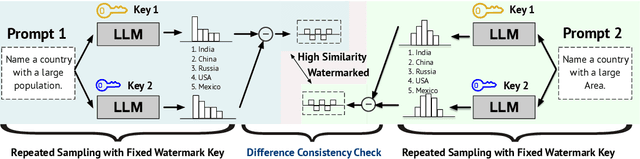
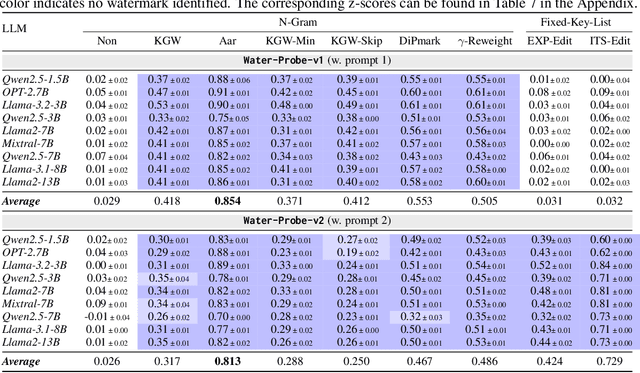

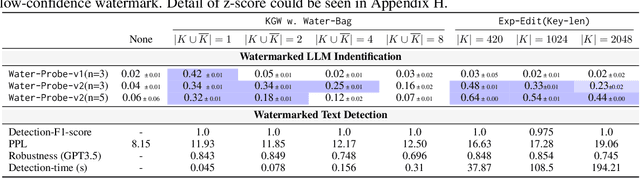
Text watermarking for Large Language Models (LLMs) has made significant progress in detecting LLM outputs and preventing misuse. Current watermarking techniques offer high detectability, minimal impact on text quality, and robustness to text editing. However, current researches lack investigation into the imperceptibility of watermarking techniques in LLM services. This is crucial as LLM providers may not want to disclose the presence of watermarks in real-world scenarios, as it could reduce user willingness to use the service and make watermarks more vulnerable to attacks. This work is the first to investigate the imperceptibility of watermarked LLMs. We design an identification algorithm called Water-Probe that detects watermarks through well-designed prompts to the LLM. Our key motivation is that current watermarked LLMs expose consistent biases under the same watermark key, resulting in similar differences across prompts under different watermark keys. Experiments show that almost all mainstream watermarking algorithms are easily identified with our well-designed prompts, while Water-Probe demonstrates a minimal false positive rate for non-watermarked LLMs. Finally, we propose that the key to enhancing the imperceptibility of watermarked LLMs is to increase the randomness of watermark key selection. Based on this, we introduce the Water-Bag strategy, which significantly improves watermark imperceptibility by merging multiple watermark keys.