 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoG: Towards automatic graph construction from tabular data
Jan 25, 2025



Recent years have witnessed significant advancements in graph machine learning (GML), with its applications spanning numerous domains. However, the focus of GML has predominantly been on developing powerful models, often overlooking a crucial initial step: constructing suitable graphs from common data formats, such as tabular data. This construction process is fundamental to applying graphbased models, yet it remains largely understudied and lacks formalization. Our research aims to address this gap by formalizing the graph construction problem and proposing an effective solution. We identify two critical challenges to achieve this goal: 1. The absence of dedicated datasets to formalize and evaluate the effectiveness of graph construction methods, and 2. Existing automatic construction methods can only be applied to some specific cases, while tedious human engineering is required to generate high-quality graphs. To tackle these challenges, we present a two-fold contribution. First, we introduce a set of datasets to formalize and evaluate graph construction methods. Second, we propose an LLM-based solution, AutoG, automatically generating high-quality graph schemas without human intervention. The experimental results demonstrate that the quality of constructed graphs is critical to downstream task performance, and AutoG can generate high-quality graphs that rival those produced by human experts.
Hierarchical Compression of Text-Rich Graphs via Large Language Models
Jun 13, 2024

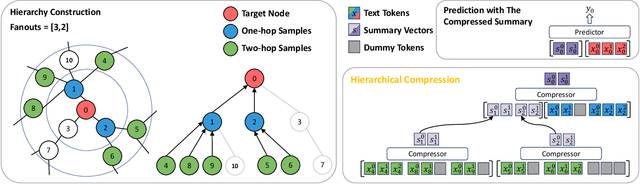
Text-rich graphs, prevalent in data mining contexts like e-commerce and academic graphs, consist of nodes with textual features linked by various relations. Traditional graph machine learning models, such as Graph Neural Networks (GNNs), excel in encoding the graph structural information, but have limited capability in handling rich text on graph nodes. Large Language Models (LLMs), noted for their superior text understanding abilities, offer a solution for processing the text in graphs but face integration challenges due to their limitation for encoding graph structures and their computational complexities when dealing with extensive text in large neighborhoods of interconnected nodes. This paper introduces ``Hierarchical Compression'' (HiCom), a novel method to align the capabilities of LLMs with the structure of text-rich graphs. HiCom processes text in a node's neighborhood in a structured manner by organizing the extensive textual information into a more manageable hierarchy and compressing node text step by step. Therefore, HiCom not only preserves the contextual richness of the text but also addresses the computational challenges of LLMs, which presents an advancement in integrating the text processing power of LLMs with the structural complexities of text-rich graphs. Empirical results show that HiCom can outperform both GNNs and LLM backbones for node classification on e-commerce and citation graphs. HiCom is especially effective for nodes from a dense region in a graph, where it achieves a 3.48% average performance improvement on five datasets while being more efficient than LLM backbones.
KGExplainer: Towards Exploring Connected Subgraph Explanations for Knowledge Graph Completion
Apr 05, 2024


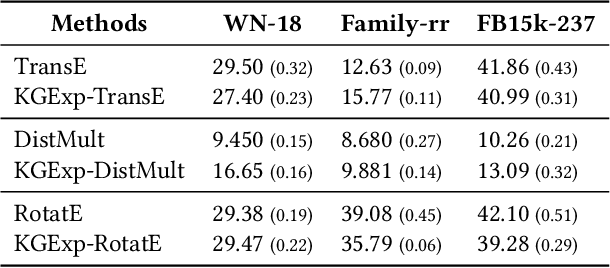
Knowledge graph completion (KGC) aims to alleviate the inherent incompleteness of knowledge graphs (KGs), which is a critical task for various applications, such as recommendations on the web. Although knowledge graph embedding (KGE) models have demonstrated superior predictive performance on KGC tasks, these models infer missing links in a black-box manner that lacks transparency and accountability, preventing researchers from developing accountable models. Existing KGE-based explanation methods focus on exploring key paths or isolated edges as explanations, which is information-less to reason target prediction. Additionally, the missing ground truth leads to these explanation methods being ineffective in quantitatively evaluating explored explanations. To overcome these limitations, we propose KGExplainer, a model-agnostic method that identifies connected subgraph explanations and distills an evaluator to assess them quantitatively. KGExplainer employs a perturbation-based greedy search algorithm to find key connected subgraphs as explanations within the local structure of target predictions. To evaluate the quality of the explored explanations, KGExplainer distills an evaluator from the target KGE model. By forwarding the explanations to the evaluator, our method can examine the fidelity of them. Extensive experiments on benchmark datasets demonstrate that KGExplainer yields promising improvement and achieves an optimal ratio of 83.3% in human evaluation.