 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph of Attacks with Pruning: Optimizing Stealthy Jailbreak Prompt Generation for Enhanced LLM Content Moderation
Jan 28, 2025We present a modular pipeline that automates the generation of stealthy jailbreak prompts derived from high-level content policies, enhancing LLM content moderation. First, we address query inefficiency and jailbreak strength by developing Graph of Attacks with Pruning (GAP), a method that utilizes strategies from prior jailbreaks, resulting in 92% attack success rate on GPT-3.5 using only 54% of the queries of the prior algorithm. Second, we address the cold-start issue by automatically generating seed prompts from the high-level policy using LLMs. Finally, we demonstrate the utility of these generated jailbreak prompts of improving content moderation by fine-tuning PromptGuard, a model trained to detect jailbreaks, increasing its accuracy on the Toxic-Chat dataset from 5.1% to 93.89%.
TaeBench: Improving Quality of Toxic Adversarial Examples
Oct 08, 2024Toxicity text detectors can be vulnerable to adversarial examples - small perturbations to input text that fool the systems into wrong detection. Existing attack algorithms are time-consuming and often produce invalid or ambiguous adversarial examples, making them less useful for evaluating or improving real-world toxicity content moderators. This paper proposes an annotation pipeline for quality control of generated toxic adversarial examples (TAE). We design model-based automated annotation and human-based quality verification to assess the quality requirements of TAE. Successful TAE should fool a target toxicity model into making benign predictions, be grammatically reasonable, appear natural like human-generated text, and exhibit semantic toxicity. When applying these requirements to more than 20 state-of-the-art (SOTA) TAE attack recipes, we find many invalid samples from a total of 940k raw TAE attack generations. We then utilize the proposed pipeline to filter and curate a high-quality TAE dataset we call TaeBench (of size 264k). Empirically, we demonstrate that TaeBench can effectively transfer-attack SOTA toxicity content moderation models and services. Our experiments also show that TaeBench with adversarial training achieve significant improvements of the robustness of two toxicity detectors.
Less is More for Improving Automatic Evaluation of Factual Consistency
Apr 09, 2024Assessing the factual consistency of automatically generated texts in relation to source context is crucial for developing reliable natural language generation applications. Recent literature proposes AlignScore which uses a unified alignment model to evaluate factual consistency and substantially outperforms previous methods across many benchmark tasks. In this paper, we take a closer look of datasets used in AlignScore and uncover an unexpected finding: utilizing a smaller number of data points can actually improve performance. We process the original AlignScore training dataset to remove noise, augment with robustness-enhanced samples, and utilize a subset comprising 10\% of the data to train an improved factual consistency evaluation model, we call LIM-RA (Less Is More for Robust AlignScore). LIM-RA demonstrates superior performance, consistently outperforming AlignScore and other strong baselines like ChatGPT across four benchmarks (two utilizing traditional natural language generation datasets and two focused on large language model outputs). Our experiments show that LIM-RA achieves the highest score on 24 of the 33 test datasets, while staying competitive on the rest, establishing the new state-of-the-art benchmarks.
COVID-19 Knowledge Graph: Accelerating Information Retrieval and Discovery for Scientific Literature
Jul 24, 2020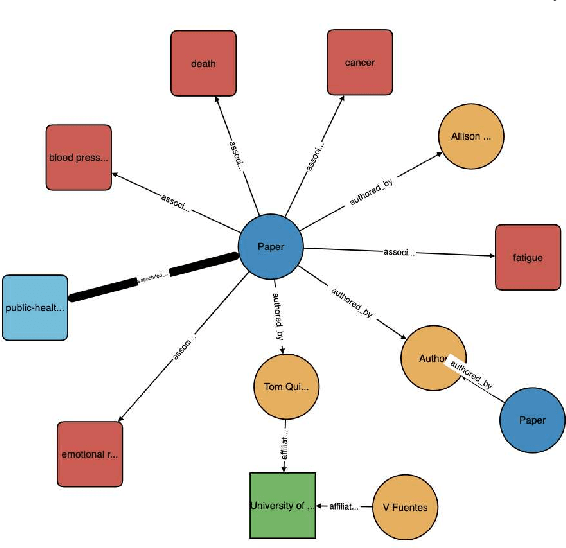
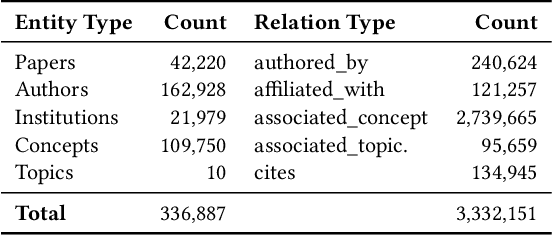
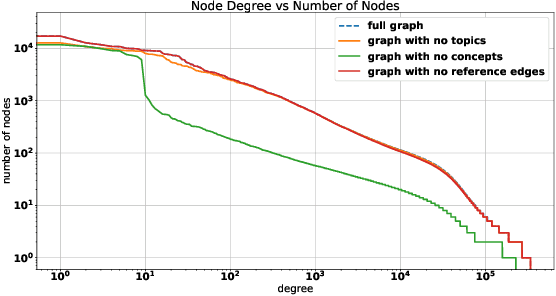

The coronavirus disease (COVID-19) has claimed the lives of over 350,000 people and infected more than 6 million people worldwide. Several search engines have surfaced to provide researchers with additional tools to find and retrieve information from the rapidly growing corpora on COVID-19. These engines lack extraction and visualization tools necessary to retrieve and interpret complex relations inherent to scientific literature. Moreover, because these engines mainly rely upon semantic information, their ability to capture complex global relationships across documents is limited, which reduces the quality of similarity-based article recommendations for users. In this work, we present the COVID-19 Knowledge Graph (CKG), a heterogeneous graph for extracting and visualizing complex relationships between COVID-19 scientific articles. The CKG combines semantic information with document topological information for the application of similar document retrieval. The CKG is constructed using the latent schema of the data, and then enriched with biomedical entity information extracted from the unstructured text of articles using scalable AWS technologies to form relations in the graph. Finally, we propose a document similarity engine that leverages low-dimensional graph embeddings from the CKG with semantic embeddings for similar article retrieval. Analysis demonstrates the quality of relationships in the CKG and shows that it can be used to uncover meaningful information in COVID-19 scientific articles. The CKG helps power www.cord19.aws and is publicly available.
Constrained Cohort Intelligence using Static and Dynamic Penalty Function Approach for Mechanical Components Design
Sep 26, 2016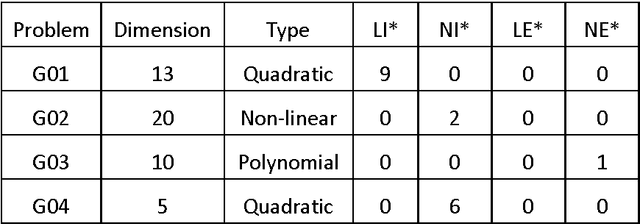

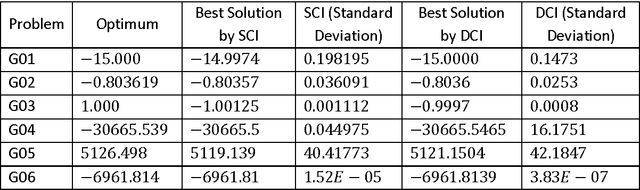
Most of the metaheuristics can efficiently solve unconstrained problems; however, their performance may degenerate if the constraints are involved. This paper proposes two constraint handling approaches for an emerging metaheuristic of Cohort Intelligence (CI). More specifically CI with static penalty function approach (SCI) and CI with dynamic penalty function approach (DCI) are proposed. The approaches have been tested by solving several constrained test problems. The performance of the SCI and DCI have been compared with algorithms like GA, PSO, ABC, d-Ds. In addition, as well as three real world problems from mechanical engineering domain with improved solutions. The results were satisfactory and validated the applicability of CI methodology for solving real world problems.