 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Signals: Exploiting Co-Engagement and Semantic Links via Graph Neural Networks
Dec 07, 2023



Given a set of candidate entities (e.g. movie titles), the ability to identify similar entities is a core capability of many recommender systems. Most often this is achieved by collaborative filtering approaches, i.e. if users co-engage with a pair of entities frequently enough, the embeddings should be similar. However, relying on co-engagement data alone can result in lower-quality embeddings for new and unpopular entities. We study this problem in the context recommender systems at Netflix. We observe that there is abundant semantic information such as genre, content maturity level, themes, etc. that complements co-engagement signals and provides interpretability in similarity models. To learn entity similarities from both data sources holistically, we propose a novel graph-based approach called SemanticGNN. SemanticGNN models entities, semantic concepts, collaborative edges, and semantic edges within a large-scale knowledge graph and conducts representation learning over it. Our key technical contributions are twofold: (1) we develop a novel relation-aware attention graph neural network (GNN) to handle the imbalanced distribution of relation types in our graph; (2) to handle web-scale graph data that has millions of nodes and billions of edges, we develop a novel distributed graph training paradigm. The proposed model is successfully deployed within Netflix and empirical experiments indicate it yields up to 35% improvement in performance on similarity judgment tasks.
COVID-19 Knowledge Graph: Accelerating Information Retrieval and Discovery for Scientific Literature
Jul 24, 2020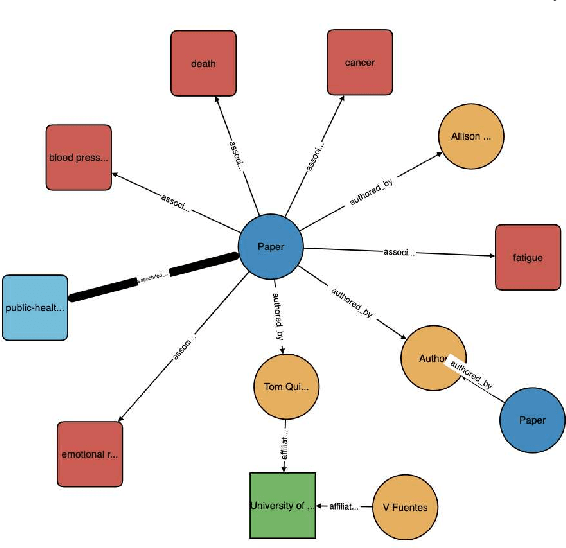
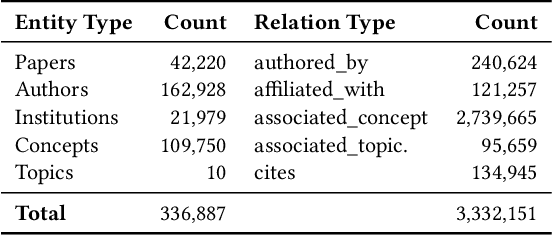
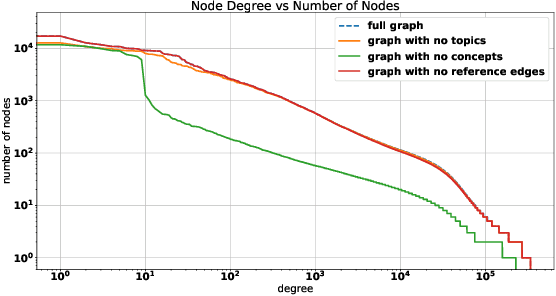

The coronavirus disease (COVID-19) has claimed the lives of over 350,000 people and infected more than 6 million people worldwide. Several search engines have surfaced to provide researchers with additional tools to find and retrieve information from the rapidly growing corpora on COVID-19. These engines lack extraction and visualization tools necessary to retrieve and interpret complex relations inherent to scientific literature. Moreover, because these engines mainly rely upon semantic information, their ability to capture complex global relationships across documents is limited, which reduces the quality of similarity-based article recommendations for users. In this work, we present the COVID-19 Knowledge Graph (CKG), a heterogeneous graph for extracting and visualizing complex relationships between COVID-19 scientific articles. The CKG combines semantic information with document topological information for the application of similar document retrieval. The CKG is constructed using the latent schema of the data, and then enriched with biomedical entity information extracted from the unstructured text of articles using scalable AWS technologies to form relations in the graph. Finally, we propose a document similarity engine that leverages low-dimensional graph embeddings from the CKG with semantic embeddings for similar article retrieval. Analysis demonstrates the quality of relationships in the CKG and shows that it can be used to uncover meaningful information in COVID-19 scientific articles. The CKG helps power www.cord19.aws and is publicly available.