 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoodCapture: Depression Detection Using In-the-Wild Smartphone Images
Feb 25, 2024MoodCapture presents a novel approach that assesses depression based on images automatically captured from the front-facing camera of smartphones as people go about their daily lives. We collect over 125,000 photos in the wild from N=177 participants diagnosed with major depressive disorder for 90 days. Images are captured naturalistically while participants respond to the PHQ-8 depression survey question: \textit{``I have felt down, depressed, or hopeless''}. Our analysis explores important image attributes, such as angle, dominant colors, location, objects, and lighting. We show that a random forest trained with face landmarks can classify samples as depressed or non-depressed and predict raw PHQ-8 scores effectively. Our post-hoc analysis provides several insights through an ablation study, feature importance analysis, and bias assessment. Importantly, we evaluate user concerns about using MoodCapture to detect depression based on sharing photos, providing critical insights into privacy concerns that inform the future design of in-the-wild image-based mental health assessment tools.
Analysis of Empirical Mode Decomposition-based Load and Renewable Time Series Forecasting
Nov 23, 2020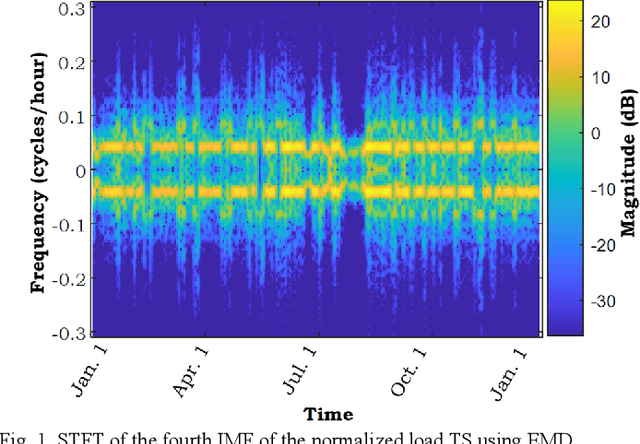
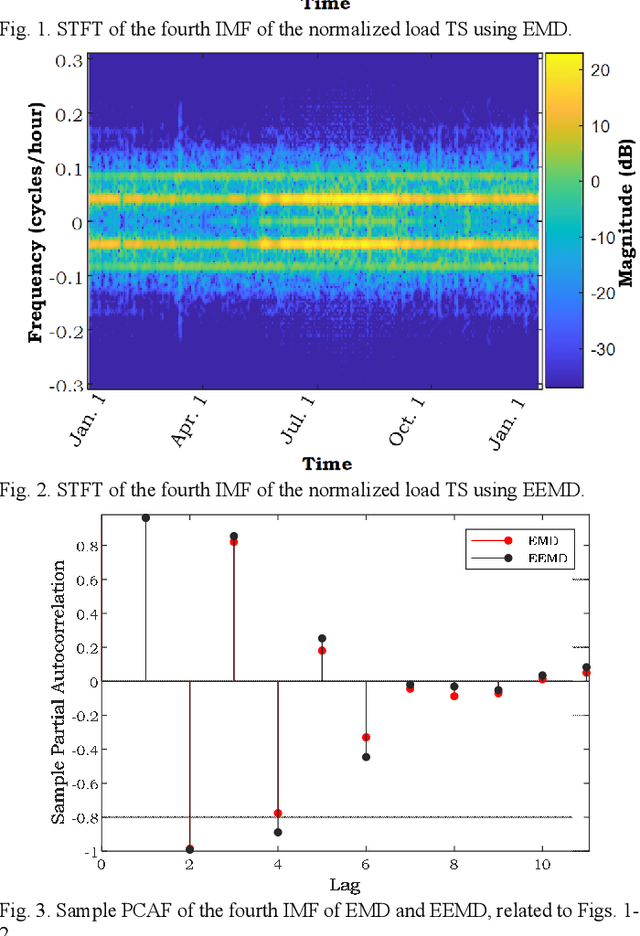
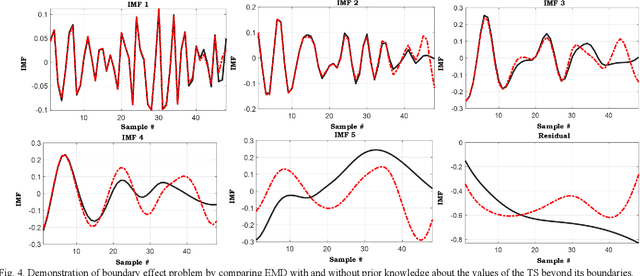
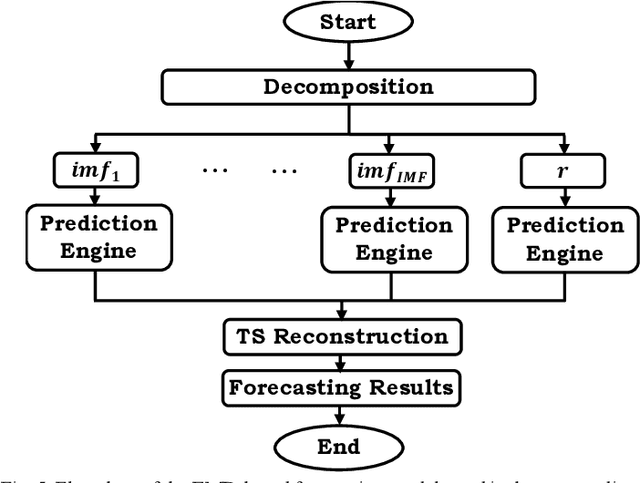
The empirical mode decomposition (EMD) method and its variants have been extensively employed in the load and renewable forecasting literature. Using this multiresolution decomposition, time series (TS) related to the historical load and renewable generation are decomposed into several intrinsic mode functions (IMFs), which are less non-stationary and non-linear. As such, the prediction of the components can theoretically be carried out with notably higher precision. The EMD method is prone to several issues, including modal aliasing and boundary effect problems, but the TS decomposition-based load and renewable generation forecasting literature primarily focuses on comparing the performance of different decomposition approaches from the forecast accuracy standpoint; as a result, these problems have rarely been scrutinized. Underestimating these issues can lead to poor performance of the forecast model in real-time applications. This paper examines these issues and their importance in the model development stage. Using real-world data, EMD-based models are presented, and the impact of the boundary effect is illustrated.
COVID-19 Knowledge Graph: Accelerating Information Retrieval and Discovery for Scientific Literature
Jul 24, 2020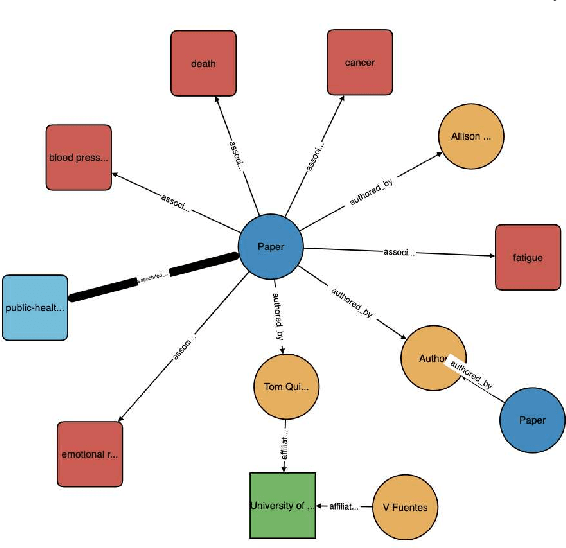
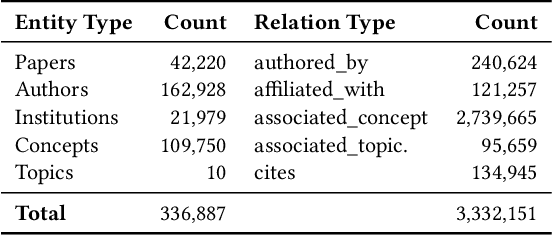
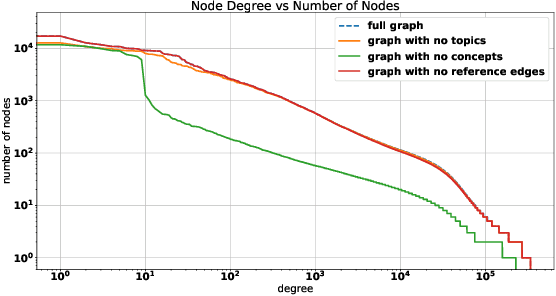

The coronavirus disease (COVID-19) has claimed the lives of over 350,000 people and infected more than 6 million people worldwide. Several search engines have surfaced to provide researchers with additional tools to find and retrieve information from the rapidly growing corpora on COVID-19. These engines lack extraction and visualization tools necessary to retrieve and interpret complex relations inherent to scientific literature. Moreover, because these engines mainly rely upon semantic information, their ability to capture complex global relationships across documents is limited, which reduces the quality of similarity-based article recommendations for users. In this work, we present the COVID-19 Knowledge Graph (CKG), a heterogeneous graph for extracting and visualizing complex relationships between COVID-19 scientific articles. The CKG combines semantic information with document topological information for the application of similar document retrieval. The CKG is constructed using the latent schema of the data, and then enriched with biomedical entity information extracted from the unstructured text of articles using scalable AWS technologies to form relations in the graph. Finally, we propose a document similarity engine that leverages low-dimensional graph embeddings from the CKG with semantic embeddings for similar article retrieval. Analysis demonstrates the quality of relationships in the CKG and shows that it can be used to uncover meaningful information in COVID-19 scientific articles. The CKG helps power www.cord19.aws and is publicly available.