 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Goal-Oriented Joint Source-Channel Coding: Distortion-Classification-Power Trade-off
Sep 17, 2025
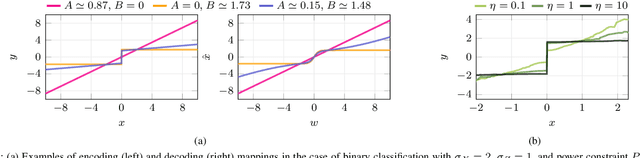
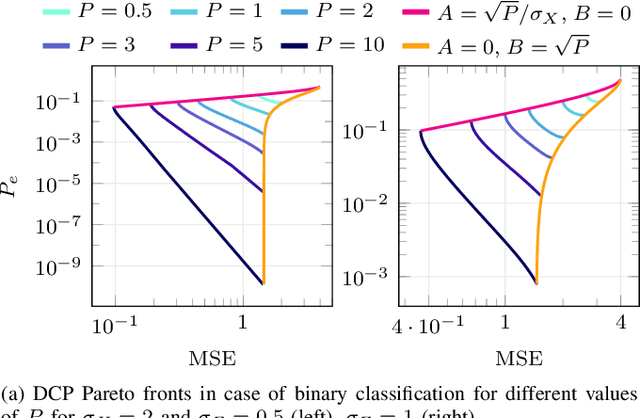
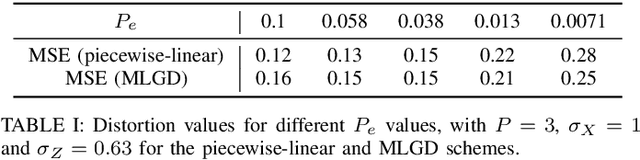
Joint source-channel coding is a compelling paradigm when low-latency and low-complexity communication is required. This work proposes a theoretical framework that integrates classification and anomaly detection within the conventional signal reconstruction objective. Assuming a Gaussian scalar source and constraining the encoder to piecewise linear mappings, we derive tractable design rules and explicitly characterize the trade-offs between distortion, classification error, and transmission power.
MoodCapture: Depression Detection Using In-the-Wild Smartphone Images
Feb 25, 2024MoodCapture presents a novel approach that assesses depression based on images automatically captured from the front-facing camera of smartphones as people go about their daily lives. We collect over 125,000 photos in the wild from N=177 participants diagnosed with major depressive disorder for 90 days. Images are captured naturalistically while participants respond to the PHQ-8 depression survey question: \textit{``I have felt down, depressed, or hopeless''}. Our analysis explores important image attributes, such as angle, dominant colors, location, objects, and lighting. We show that a random forest trained with face landmarks can classify samples as depressed or non-depressed and predict raw PHQ-8 scores effectively. Our post-hoc analysis provides several insights through an ablation study, feature importance analysis, and bias assessment. Importantly, we evaluate user concerns about using MoodCapture to detect depression based on sharing photos, providing critical insights into privacy concerns that inform the future design of in-the-wild image-based mental health assessment tools.
Spectral Ranking Inferences based on General Multiway Comparisons
Aug 13, 2023This paper studies the performance of the spectral method in the estimation and uncertainty quantification of the unobserved preference scores of compared entities in a very general and more realistic setup in which the comparison graph consists of hyper-edges of possible heterogeneous sizes and the number of comparisons can be as low as one for a given hyper-edge. Such a setting is pervasive in real applications, circumventing the need to specify the graph randomness and the restrictive homogeneous sampling assumption imposed in the commonly-used Bradley-Terry-Luce (BTL) or Plackett-Luce (PL) models. Furthermore, in the scenarios when the BTL or PL models are appropriate, we unravel the relationship between the spectral estimator and the Maximum Likelihood Estimator (MLE). We discover that a two-step spectral method, where we apply the optimal weighting estimated from the equal weighting vanilla spectral method, can achieve the same asymptotic efficiency as the MLE. Given the asymptotic distributions of the estimated preference scores, we also introduce a comprehensive framework to carry out both one-sample and two-sample ranking inferences, applicable to both fixed and random graph settings. It is noteworthy that it is the first time effective two-sample rank testing methods are proposed. Finally, we substantiate our findings via comprehensive numerical simulations and subsequently apply our developed methodologies to perform statistical inferences on statistics journals and movie rankings.
Using Mobile Data and Deep Models to Assess Auditory Verbal Hallucinations
Apr 20, 2023



Hallucination is an apparent perception in the absence of real external sensory stimuli. An auditory hallucination is a perception of hearing sounds that are not real. A common form of auditory hallucination is hearing voices in the absence of any speakers which is known as Auditory Verbal Hallucination (AVH). AVH is fragments of the mind's creation that mostly occur in people diagnosed with mental illnesses such as bipolar disorder and schizophrenia. Assessing the valence of hallucinated voices (i.e., how negative or positive voices are) can help measure the severity of a mental illness. We study N=435 individuals, who experience hearing voices, to assess auditory verbal hallucination. Participants report the valence of voices they hear four times a day for a month through ecological momentary assessments with questions that have four answering scales from ``not at all'' to ``extremely''. We collect these self-reports as the valence supervision of AVH events via a mobile application. Using the application, participants also record audio diaries to describe the content of hallucinated voices verbally. In addition, we passively collect mobile sensing data as contextual signals. We then experiment with how predictive these linguistic and contextual cues from the audio diary and mobile sensing data are of an auditory verbal hallucination event. Finally, using transfer learning and data fusion techniques, we train a neural net model that predicts the valance of AVH with a performance of 54\% top-1 and 72\% top-2 F1 score.
Inference on Time Series Nonparametric Conditional Moment Restrictions Using General Sieves
Jan 03, 2023General nonlinear sieve learnings are classes of nonlinear sieves that can approximate nonlinear functions of high dimensional variables much more flexibly than various linear sieves (or series). This paper considers general nonlinear sieve quasi-likelihood ratio (GN-QLR) based inference on expectation functionals of time series data, where the functionals of interest are based on some nonparametric function that satisfy conditional moment restrictions and are learned using multilayer neural networks. While the asymptotic normality of the estimated functionals depends on some unknown Riesz representer of the functional space, we show that the optimally weighted GN-QLR statistic is asymptotically Chi-square distributed, regardless whether the expectation functional is regular (root-$n$ estimable) or not. This holds when the data are weakly dependent beta-mixing condition. We apply our method to the off-policy evaluation in reinforcement learning, by formulating the Bellman equation into the conditional moment restriction framework, so that we can make inference about the state-specific value functional using the proposed GN-QLR method with time series data. In addition, estimating the averaged partial means and averaged partial derivatives of nonparametric instrumental variables and quantile IV models are also presented as leading examples. Finally, a Monte Carlo study shows the finite sample performance of the procedure
Ranking Inferences Based on the Top Choice of Multiway Comparisons
Dec 07, 2022



This paper considers ranking inference of $n$ items based on the observed data on the top choice among $M$ randomly selected items at each trial. This is a useful modification of the Plackett-Luce model for $M$-way ranking with only the top choice observed and is an extension of the celebrated Bradley-Terry-Luce model that corresponds to $M=2$. Under a uniform sampling scheme in which any $M$ distinguished items are selected for comparisons with probability $p$ and the selected $M$ items are compared $L$ times with multinomial outcomes, we establish the statistical rates of convergence for underlying $n$ preference scores using both $\ell_2$-norm and $\ell_\infty$-norm, with the minimum sampling complexity. In addition, we establish the asymptotic normality of the maximum likelihood estimator that allows us to construct confidence intervals for the underlying scores. Furthermore, we propose a novel inference framework for ranking items through a sophisticated maximum pairwise difference statistic whose distribution is estimated via a valid Gaussian multiplier bootstrap. The estimated distribution is then used to construct simultaneous confidence intervals for the differences in the preference scores and the ranks of individual items. They also enable us to address various inference questions on the ranks of these items. Extensive simulation studies lend further support to our theoretical results. A real data application illustrates the usefulness of the proposed methods convincingly.
Patient-independent Schizophrenia Relapse Prediction Using Mobile Sensor based Daily Behavioral Rhythm Changes
Jun 25, 2021

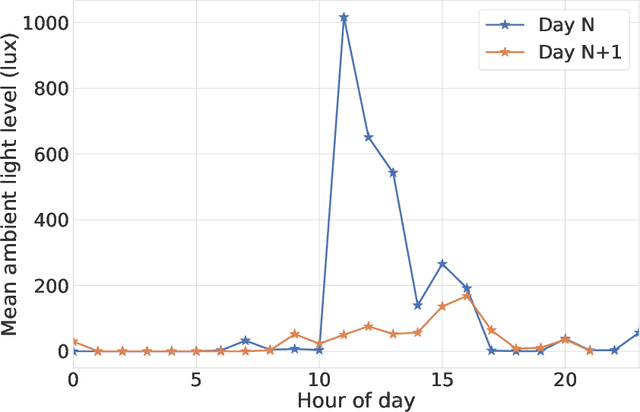
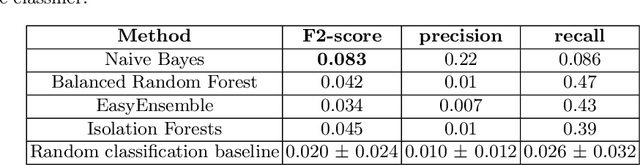
A schizophrenia relapse has severe consequences for a patient's health, work, and sometimes even life safety. If an oncoming relapse can be predicted on time, for example by detecting early behavioral changes in patients, then interventions could be provided to prevent the relapse. In this work, we investigated a machine learning based schizophrenia relapse prediction model using mobile sensing data to characterize behavioral features. A patient-independent model providing sequential predictions, closely representing the clinical deployment scenario for relapse prediction, was evaluated. The model uses the mobile sensing data from the recent four weeks to predict an oncoming relapse in the next week. We used the behavioral rhythm features extracted from daily templates of mobile sensing data, self-reported symptoms collected via EMA (Ecological Momentary Assessment), and demographics to compare different classifiers for the relapse prediction. Naive Bayes based model gave the best results with an F2 score of 0.083 when evaluated in a dataset consisting of 63 schizophrenia patients, each monitored for up to a year. The obtained F2 score, though low, is better than the baseline performance of random classification (F2 score of 0.02 $\pm$ 0.024). Thus, mobile sensing has predictive value for detecting an oncoming relapse and needs further investigation to improve the current performance. Towards that end, further feature engineering and model personalization based on the behavioral idiosyncrasies of a patient could be helpful.
Global Convergence of Policy Gradient for Linear-Quadratic Mean-Field Control/Game in Continuous Time
Aug 16, 2020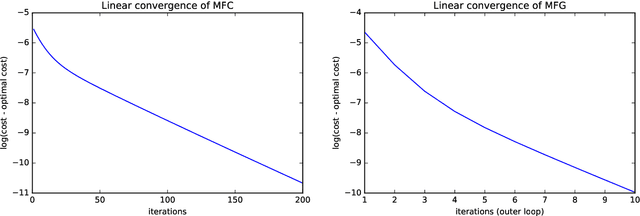
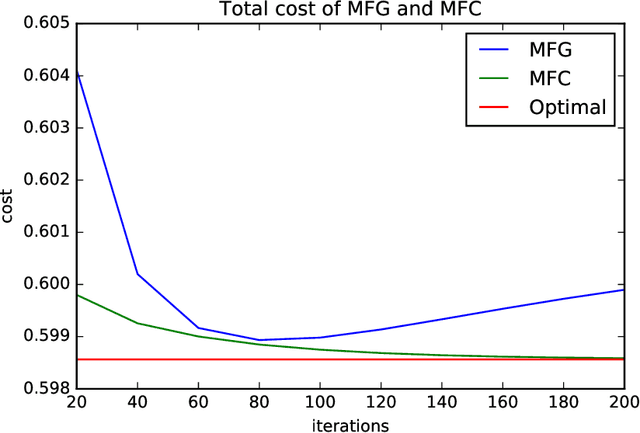
Reinforcement learning is a powerful tool to learn the optimal policy of possibly multiple agents by interacting with the environment. As the number of agents grow to be very large, the system can be approximated by a mean-field problem. Therefore, it has motivated new research directions for mean-field control (MFC) and mean-field game (MFG). In this paper, we study the policy gradient method for the linear-quadratic mean-field control and game, where we assume each agent has identical linear state transitions and quadratic cost functions. While most of the recent works on policy gradient for MFC and MFG are based on discrete-time models, we focus on the continuous-time models where some analyzing techniques can be interesting to the readers. For both MFC and MFG, we provide policy gradient update and show that it converges to the optimal solution at a linear rate, which is verified by a synthetic simulation. For MFG, we also provide sufficient conditions for the existence and uniqueness of the Nash equilibrium.