 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4's assessment of its performance in a USMLE-based case study
Feb 15, 2024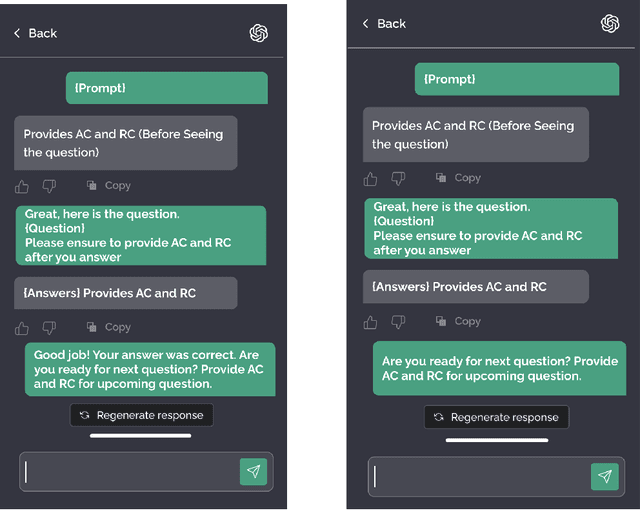
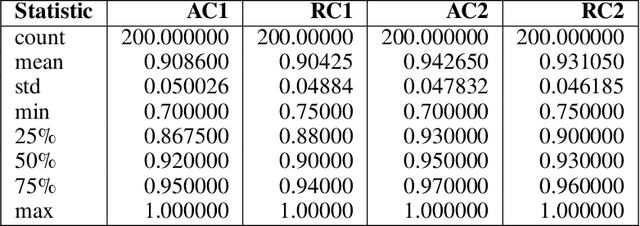
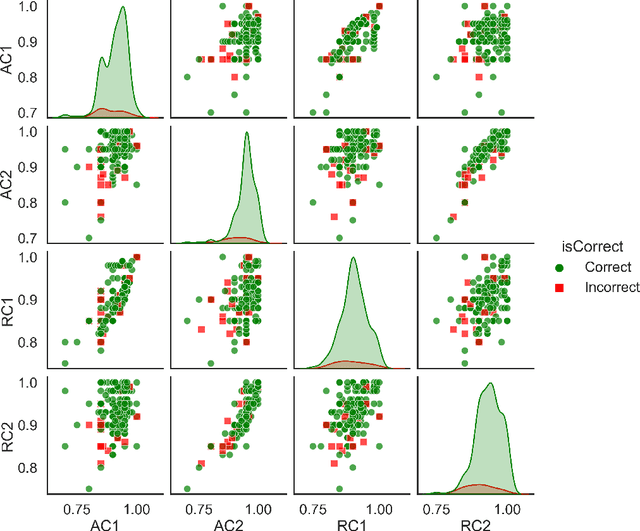
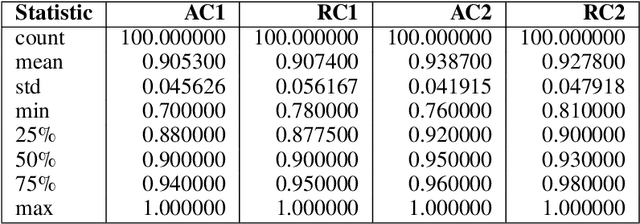
This study investigates GPT-4's assessment of its performance in healthcare applications. A simple prompting technique was used to prompt the LLM with questions taken from the United States Medical Licensing Examination (USMLE) questionnaire and it was tasked to evaluate its confidence score before posing the question and after asking the question. The questionnaire was categorized into two groups-questions with feedback (WF) and questions with no feedback(NF) post-question. The model was asked to provide absolute and relative confidence scores before and after each question. The experimental findings were analyzed using statistical tools to study the variability of confidence in WF and NF groups. Additionally, a sequential analysis was conducted to observe the performance variation for the WF and NF groups. Results indicate that feedback influences relative confidence but doesn't consistently increase or decrease it. Understanding the performance of LLM is paramount in exploring its utility in sensitive areas like healthcare. This study contributes to the ongoing discourse on the reliability of AI, particularly of LLMs like GPT-4, within healthcare, offering insights into how feedback mechanisms might be optimized to enhance AI-assisted medical education and decision support.
The Confidence-Competence Gap in Large Language Models: A Cognitive Study
Sep 28, 2023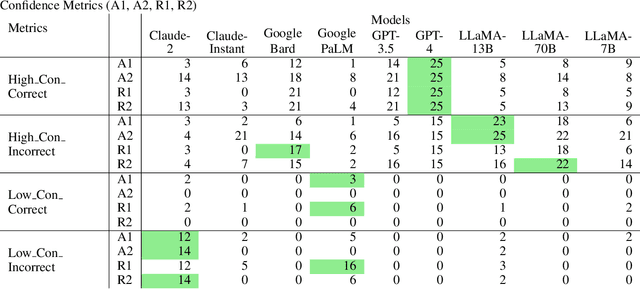
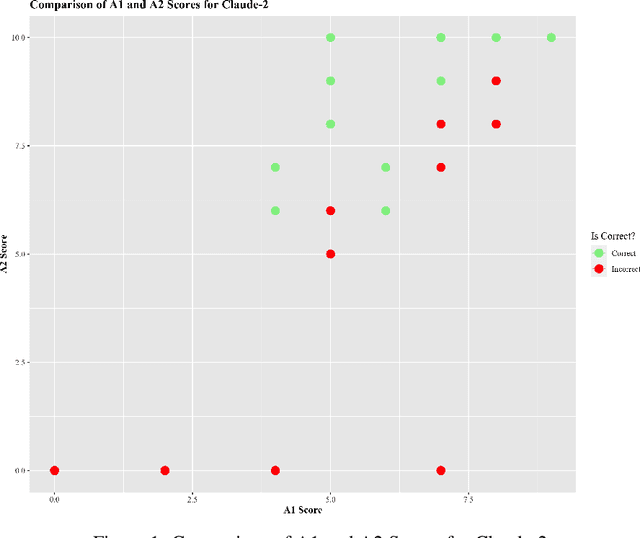
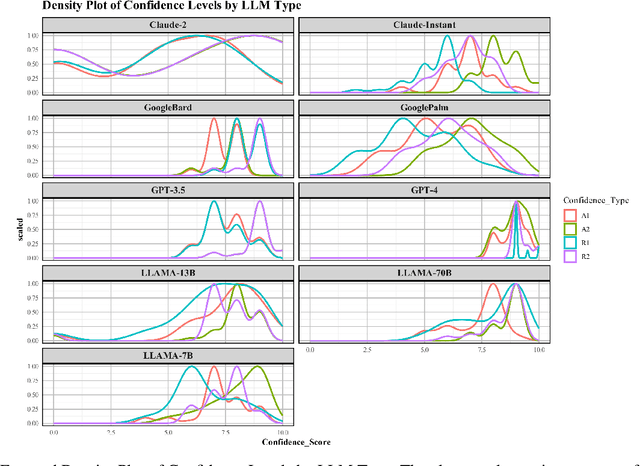
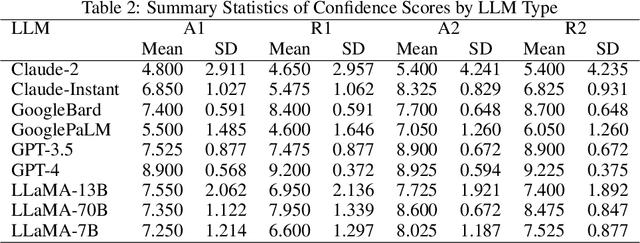
Large Language Models (LLMs) have acquired ubiquitous attention for their performances across diverse domains. Our study here searches through LLMs' cognitive abilities and confidence dynamics. We dive deep into understanding the alignment between their self-assessed confidence and actual performance. We exploit these models with diverse sets of questionnaires and real-world scenarios and extract how LLMs exhibit confidence in their responses. Our findings reveal intriguing instances where models demonstrate high confidence even when they answer incorrectly. This is reminiscent of the Dunning-Kruger effect observed in human psychology. In contrast, there are cases where models exhibit low confidence with correct answers revealing potential underestimation biases. Our results underscore the need for a deeper understanding of their cognitive processes. By examining the nuances of LLMs' self-assessment mechanism, this investigation provides noteworthy revelations that serve to advance the functionalities and broaden the potential applications of these formidable language models.
Evaluation of ChatGPT for NLP-based Mental Health Applications
Mar 28, 2023Large language models (LLM) have been successful in several natural language understanding tasks and could be relevant for natural language processing (NLP)-based mental health application research. In this work, we report the performance of LLM-based ChatGPT (with gpt-3.5-turbo backend) in three text-based mental health classification tasks: stress detection (2-class classification), depression detection (2-class classification), and suicidality detection (5-class classification). We obtained annotated social media posts for the three classification tasks from public datasets. Then ChatGPT API classified the social media posts with an input prompt for classification. We obtained F1 scores of 0.73, 0.86, and 0.37 for stress detection, depression detection, and suicidality detection, respectively. A baseline model that always predicted the dominant class resulted in F1 scores of 0.35, 0.60, and 0.19. The zero-shot classification accuracy obtained with ChatGPT indicates a potential use of language models for mental health classification tasks.
Dyadic Interaction Assessment from Free-living Audio for Depression Severity Assessment
Sep 08, 2022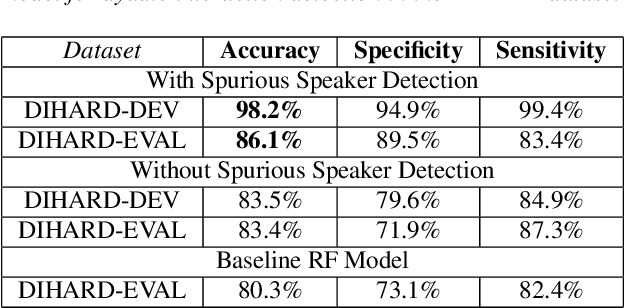
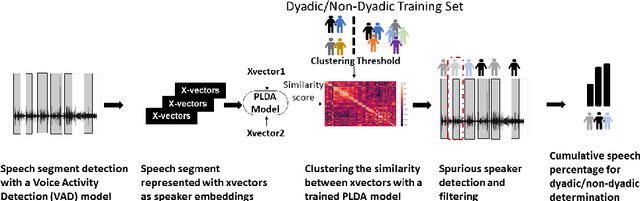
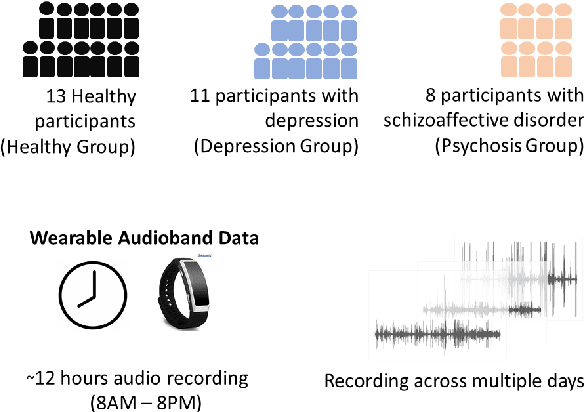
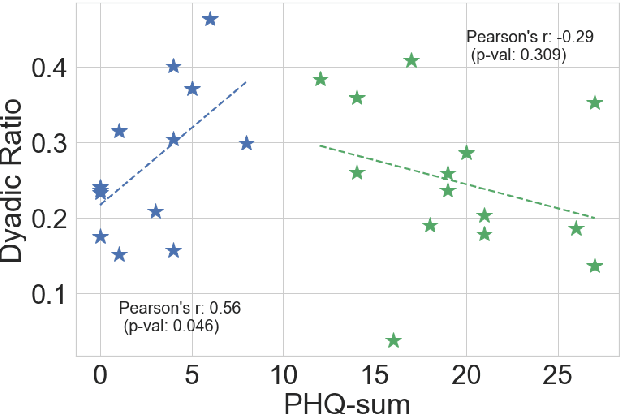
Psychomotor retardation in depression has been associated with speech timing changes from dyadic clinical interviews. In this work, we investigate speech timing features from free-living dyadic interactions. Apart from the possibility of continuous monitoring to complement clinical visits, a study in free-living conditions would also allow inferring sociability features such as dyadic interaction frequency implicated in depression. We adapted a speaker count estimator as a dyadic interaction detector with a specificity of 89.5% and a sensitivity of 86.1% in the DIHARD dataset. Using the detector, we obtained speech timing features from the detected dyadic interactions in multi-day audio recordings of 32 participants comprised of 13 healthy individuals, 11 individuals with depression, and 8 individuals with psychotic disorders. The dyadic interaction frequency increased with depression severity in participants with no or mild depression, indicating a potential diagnostic marker of depression onset. However, the dyadic interaction frequency decreased with increasing depression severity for participants with moderate or severe depression. In terms of speech timing features, the response time had a significant positive correlation with depression severity. Our work shows the potential of dyadic interaction analysis from audio recordings of free-living to obtain markers of depression severity.
Psychotic Relapse Prediction in Schizophrenia Patients using A Mobile Sensing-based Supervised Deep Learning Model
May 24, 2022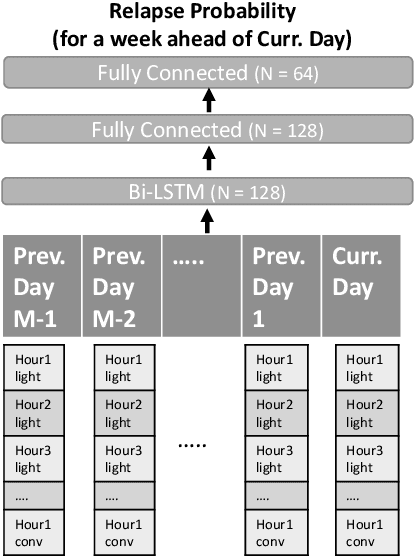
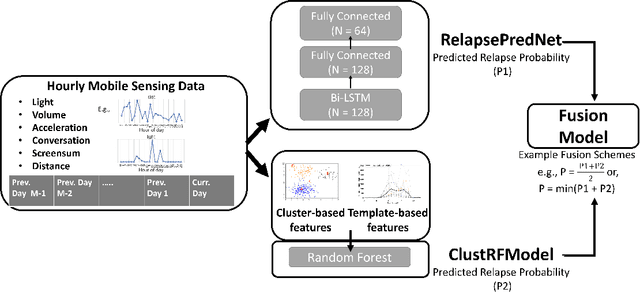
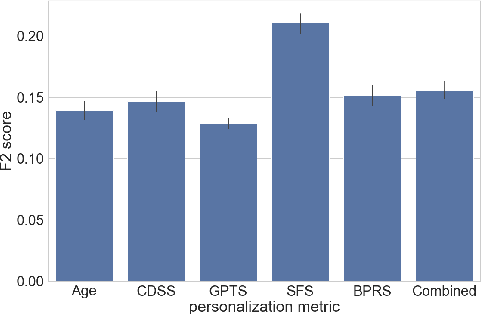
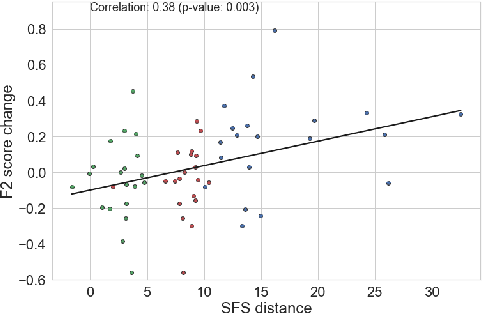
Mobile sensing-based modeling of behavioral changes could predict an oncoming psychotic relapse in schizophrenia patients for timely interventions. Deep learning models could complement existing non-deep learning models for relapse prediction by modeling latent behavioral features relevant to the prediction. However, given the inter-individual behavioral differences, model personalization might be required for a predictive model. In this work, we propose RelapsePredNet, a Long Short-Term Memory (LSTM) neural network-based model for relapse prediction. The model is personalized for a particular patient by training using data from patients most similar to the given patient. Several demographics and baseline mental health scores were considered as personalization metrics to define patient similarity. We investigated the effect of personalization on training dataset characteristics, learned embeddings, and relapse prediction performance. We compared RelapsePredNet with a deep learning-based anomaly detection model for relapse prediction. Further, we investigated if RelapsePredNet could complement ClusterRFModel (a random forest model leveraging clustering and template features proposed in prior work) in a fusion model, by identifying latent behavioral features relevant for relapse prediction. The CrossCheck dataset consisting of continuous mobile sensing data obtained from 63 schizophrenia patients, each monitored for up to a year, was used for our evaluations. The proposed RelapsePredNet outperformed the deep learning-based anomaly detection model for relapse prediction. The F2 score for prediction were 0.21 and 0.52 in the full test set and the Relapse Test Set (consisting of data from patients who have had relapse only), respectively. These corresponded to a 29.4% and 38.8% improvement compared to the existing deep learning-based model for relapse prediction.
Patient-independent Schizophrenia Relapse Prediction Using Mobile Sensor based Daily Behavioral Rhythm Changes
Jun 25, 2021

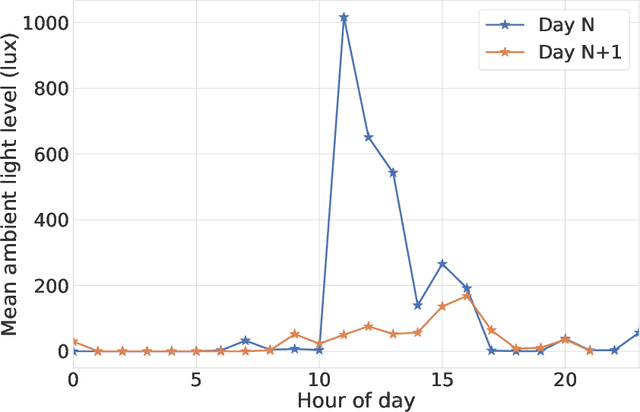
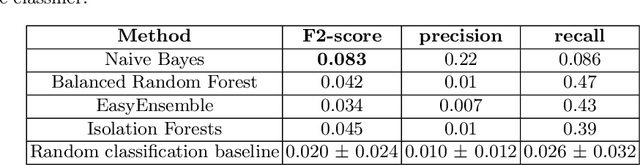
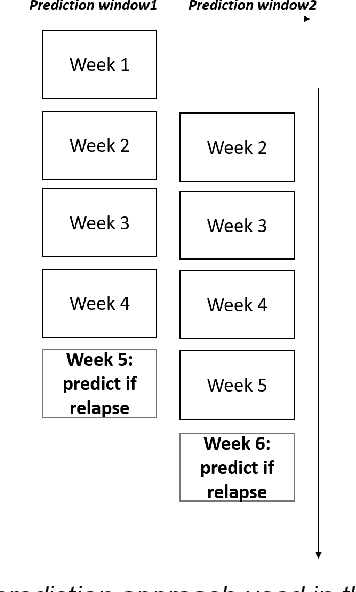
A schizophrenia relapse has severe consequences for a patient's health, work, and sometimes even life safety. If an oncoming relapse can be predicted on time, for example by detecting early behavioral changes in patients, then interventions could be provided to prevent the relapse. In this work, we investigated a machine learning based schizophrenia relapse prediction model using mobile sensing data to characterize behavioral features. A patient-independent model providing sequential predictions, closely representing the clinical deployment scenario for relapse prediction, was evaluated. The model uses the mobile sensing data from the recent four weeks to predict an oncoming relapse in the next week. We used the behavioral rhythm features extracted from daily templates of mobile sensing data, self-reported symptoms collected via EMA (Ecological Momentary Assessment), and demographics to compare different classifiers for the relapse prediction. Naive Bayes based model gave the best results with an F2 score of 0.083 when evaluated in a dataset consisting of 63 schizophrenia patients, each monitored for up to a year. The obtained F2 score, though low, is better than the baseline performance of random classification (F2 score of 0.02 $\pm$ 0.024). Thus, mobile sensing has predictive value for detecting an oncoming relapse and needs further investigation to improve the current performance. Towards that end, further feature engineering and model personalization based on the behavioral idiosyncrasies of a patient could be helpful.
Routine Clustering of Mobile Sensor Data Facilitates Psychotic Relapse Prediction in Schizophrenia Patients
Jun 22, 2021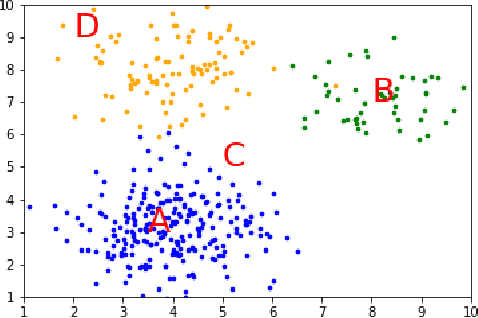


We aim to develop clustering models to obtain behavioral representations from continuous multimodal mobile sensing data towards relapse prediction tasks. The identified clusters could represent different routine behavioral trends related to daily living of patients as well as atypical behavioral trends associated with impending relapse. We used the mobile sensing data obtained in the CrossCheck project for our analysis. Continuous data from six different mobile sensing-based modalities (e.g. ambient light, sound/conversation, acceleration etc.) obtained from a total of 63 schizophrenia patients, each monitored for up to a year, were used for the clustering models and relapse prediction evaluation. Two clustering models, Gaussian Mixture Model (GMM) and Partition Around Medoids (PAM), were used to obtain behavioral representations from the mobile sensing data. The features obtained from the clustering models were used to train and evaluate a personalized relapse prediction model using Balanced Random Forest. The personalization was done by identifying optimal features for a given patient based on a personalization subset consisting of other patients who are of similar age. The clusters identified using the GMM and PAM models were found to represent different behavioral patterns (such as clusters representing sedentary days, active but with low communications days, etc.). Significant changes near the relapse periods were seen in the obtained behavioral representation features from the clustering models. The clustering model based features, together with other features characterizing the mobile sensing data, resulted in an F2 score of 0.24 for the relapse prediction task in a leave-one-patient-out evaluation setting. This obtained F2 score is significantly higher than a random classification baseline with an average F2 score of 0.042.