 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Confidence-Competence Gap in Large Language Models: A Cognitive Study
Paper and Code
Sep 28, 2023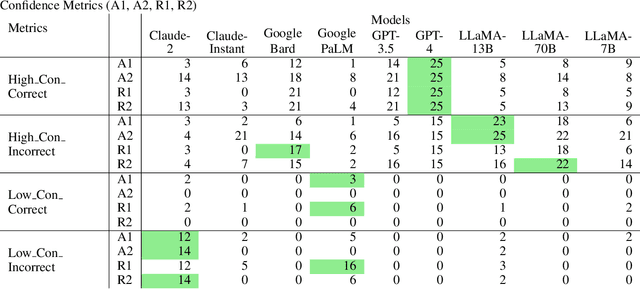
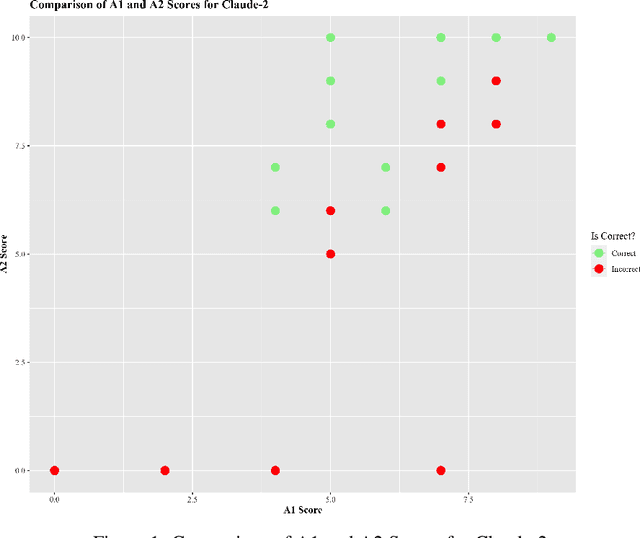
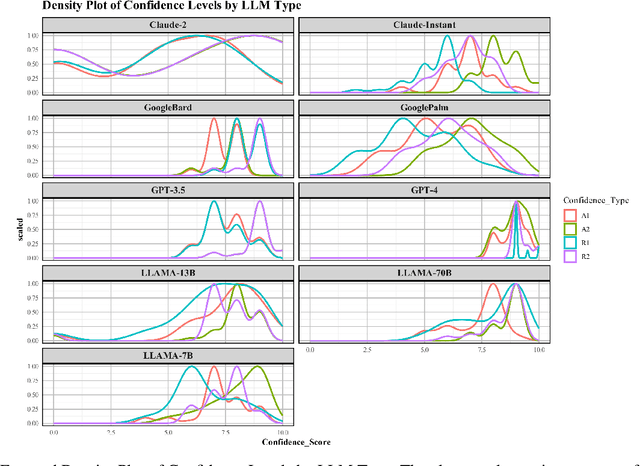
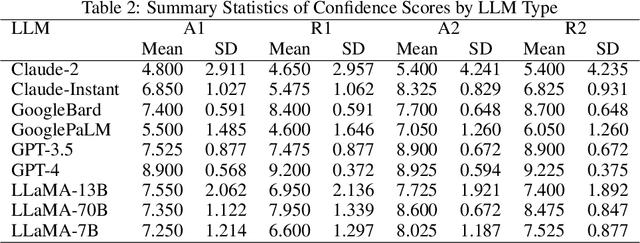
Large Language Models (LLMs) have acquired ubiquitous attention for their performances across diverse domains. Our study here searches through LLMs' cognitive abilities and confidence dynamics. We dive deep into understanding the alignment between their self-assessed confidence and actual performance. We exploit these models with diverse sets of questionnaires and real-world scenarios and extract how LLMs exhibit confidence in their responses. Our findings reveal intriguing instances where models demonstrate high confidence even when they answer incorrectly. This is reminiscent of the Dunning-Kruger effect observed in human psychology. In contrast, there are cases where models exhibit low confidence with correct answers revealing potential underestimation biases. Our results underscore the need for a deeper understanding of their cognitive processes. By examining the nuances of LLMs' self-assessment mechanism, this investigation provides noteworthy revelations that serve to advance the functionalities and broaden the potential applications of these formidable language models.