 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4's assessment of its performance in a USMLE-based case study
Feb 15, 2024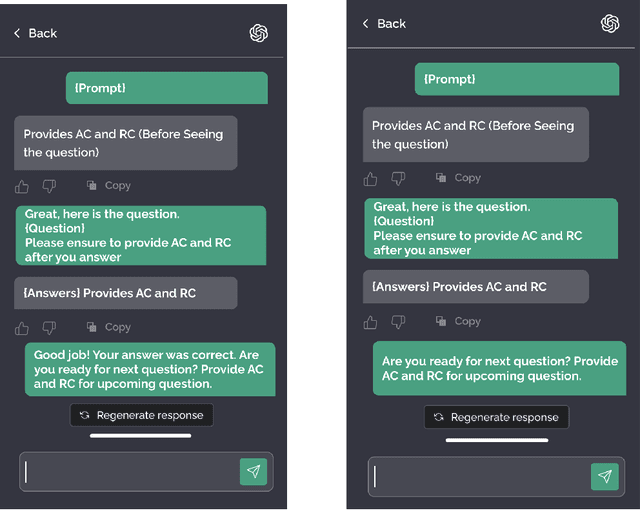
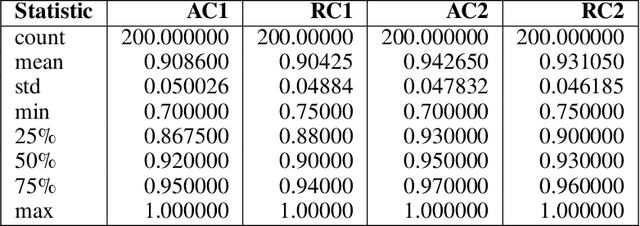
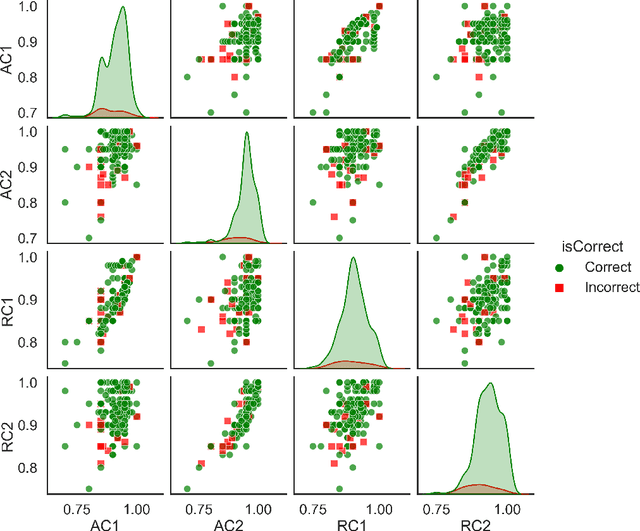
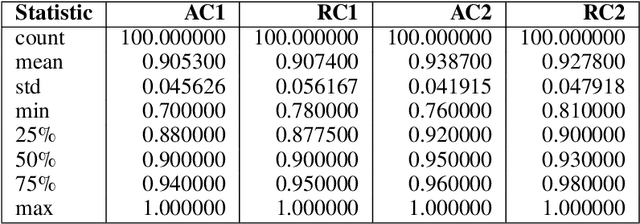
This study investigates GPT-4's assessment of its performance in healthcare applications. A simple prompting technique was used to prompt the LLM with questions taken from the United States Medical Licensing Examination (USMLE) questionnaire and it was tasked to evaluate its confidence score before posing the question and after asking the question. The questionnaire was categorized into two groups-questions with feedback (WF) and questions with no feedback(NF) post-question. The model was asked to provide absolute and relative confidence scores before and after each question. The experimental findings were analyzed using statistical tools to study the variability of confidence in WF and NF groups. Additionally, a sequential analysis was conducted to observe the performance variation for the WF and NF groups. Results indicate that feedback influences relative confidence but doesn't consistently increase or decrease it. Understanding the performance of LLM is paramount in exploring its utility in sensitive areas like healthcare. This study contributes to the ongoing discourse on the reliability of AI, particularly of LLMs like GPT-4, within healthcare, offering insights into how feedback mechanisms might be optimized to enhance AI-assisted medical education and decision support.
The Confidence-Competence Gap in Large Language Models: A Cognitive Study
Sep 28, 2023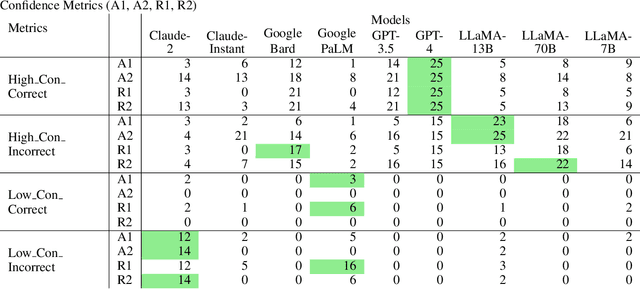
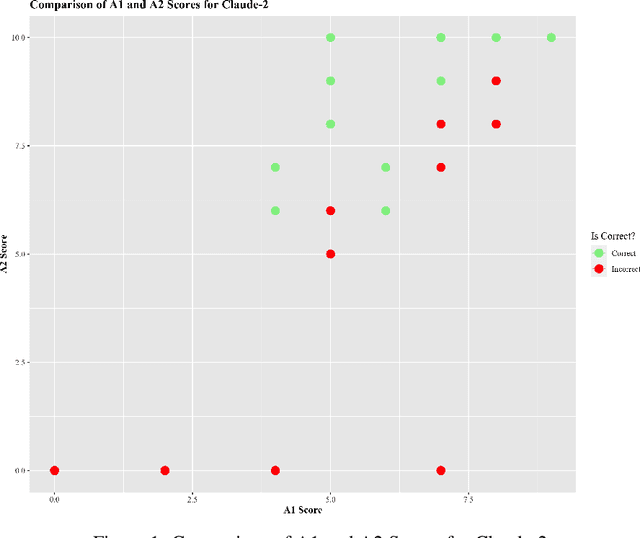
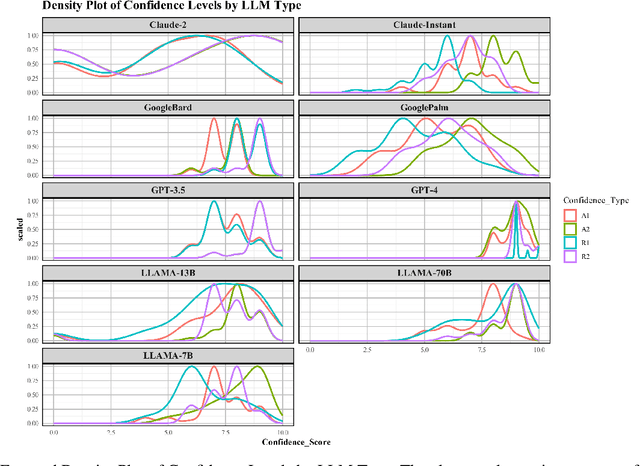
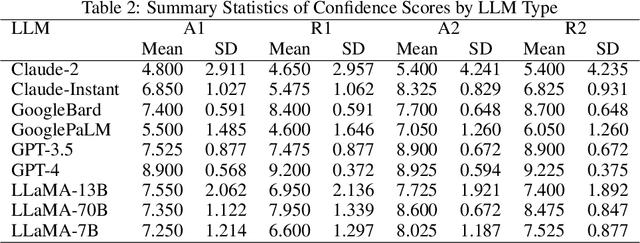
Large Language Models (LLMs) have acquired ubiquitous attention for their performances across diverse domains. Our study here searches through LLMs' cognitive abilities and confidence dynamics. We dive deep into understanding the alignment between their self-assessed confidence and actual performance. We exploit these models with diverse sets of questionnaires and real-world scenarios and extract how LLMs exhibit confidence in their responses. Our findings reveal intriguing instances where models demonstrate high confidence even when they answer incorrectly. This is reminiscent of the Dunning-Kruger effect observed in human psychology. In contrast, there are cases where models exhibit low confidence with correct answers revealing potential underestimation biases. Our results underscore the need for a deeper understanding of their cognitive processes. By examining the nuances of LLMs' self-assessment mechanism, this investigation provides noteworthy revelations that serve to advance the functionalities and broaden the potential applications of these formidable language models.
Exploring New Frontiers in Agricultural NLP: Investigating the Potential of Large Language Models for Food Applications
Jun 20, 2023



This paper explores new frontiers in agricultural natural language processing by investigating the effectiveness of using food-related text corpora for pretraining transformer-based language models. In particular, we focus on the task of semantic matching, which involves establishing mappings between food descriptions and nutrition data. To accomplish this, we fine-tune a pre-trained transformer-based language model, AgriBERT, on this task, utilizing an external source of knowledge, such as the FoodOn ontology. To advance the field of agricultural NLP, we propose two new avenues of exploration: (1) utilizing GPT-based models as a baseline and (2) leveraging ChatGPT as an external source of knowledge. ChatGPT has shown to be a strong baseline in many NLP tasks, and we believe it has the potential to improve our model in the task of semantic matching and enhance our model's understanding of food-related concepts and relationships. Additionally, we experiment with other applications, such as cuisine prediction based on food ingredients, and expand the scope of our research to include other NLP tasks beyond semantic matching. Overall, this paper provides promising avenues for future research in this field, with potential implications for improving the performance of agricultural NLP applications.