 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Security and Strengthening Defenses in Automated Short-Answer Grading Systems
Apr 30, 2025This study examines vulnerabilities in transformer-based automated short-answer grading systems used in medical education, with a focus on how these systems can be manipulated through adversarial gaming strategies. Our research identifies three main types of gaming strategies that exploit the system's weaknesses, potentially leading to false positives. To counteract these vulnerabilities, we implement several adversarial training methods designed to enhance the systems' robustness. Our results indicate that these methods significantly reduce the susceptibility of grading systems to such manipulations, especially when combined with ensemble techniques like majority voting and ridge regression, which further improve the system's defense against sophisticated adversarial inputs. Additionally, employing large language models such as GPT-4 with varied prompting techniques has shown promise in recognizing and scoring gaming strategies effectively. The findings underscore the importance of continuous improvements in AI-driven educational tools to ensure their reliability and fairness in high-stakes settings.
Flood of Techniques and Drought of Theories: Emotion Mining in Disasters
Jul 09, 2024Emotion mining has become a crucial tool for understanding human emotions during disasters, leveraging the extensive data generated on social media platforms. This paper aims to summarize existing research on emotion mining within disaster contexts, highlighting both significant discoveries and persistent issues. On the one hand, emotion mining techniques have achieved acceptable accuracy enabling applications such as rapid damage assessment and mental health surveillance. On the other hand, with many studies adopting data-driven approaches, several methodological issues remain. These include arbitrary emotion classification, ignoring biases inherent in data collection from social media, such as the overrepresentation of individuals from higher socioeconomic status on Twitter, and the lack of application of theoretical frameworks like cross-cultural comparisons. These problems can be summarized as a notable lack of theory-driven research and ignoring insights from social and behavioral sciences. This paper underscores the need for interdisciplinary collaboration between computer scientists and social scientists to develop more robust and theoretically grounded approaches in emotion mining. By addressing these gaps, we aim to enhance the effectiveness and reliability of emotion mining methodologies, ultimately contributing to improved disaster preparedness, response, and recovery. Keywords: emotion mining, sentiment analysis, natural disasters, psychology, technological disasters
Exploring New Frontiers in Agricultural NLP: Investigating the Potential of Large Language Models for Food Applications
Jun 20, 2023



This paper explores new frontiers in agricultural natural language processing by investigating the effectiveness of using food-related text corpora for pretraining transformer-based language models. In particular, we focus on the task of semantic matching, which involves establishing mappings between food descriptions and nutrition data. To accomplish this, we fine-tune a pre-trained transformer-based language model, AgriBERT, on this task, utilizing an external source of knowledge, such as the FoodOn ontology. To advance the field of agricultural NLP, we propose two new avenues of exploration: (1) utilizing GPT-based models as a baseline and (2) leveraging ChatGPT as an external source of knowledge. ChatGPT has shown to be a strong baseline in many NLP tasks, and we believe it has the potential to improve our model in the task of semantic matching and enhance our model's understanding of food-related concepts and relationships. Additionally, we experiment with other applications, such as cuisine prediction based on food ingredients, and expand the scope of our research to include other NLP tasks beyond semantic matching. Overall, this paper provides promising avenues for future research in this field, with potential implications for improving the performance of agricultural NLP applications.
Edge: Enriching Knowledge Graph Embeddings with External Text
Apr 11, 2021


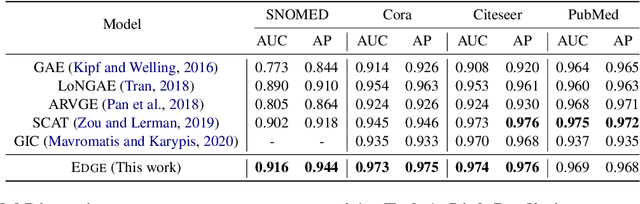
Knowledge graphs suffer from sparsity which degrades the quality of representations generated by various methods. While there is an abundance of textual information throughout the web and many existing knowledge bases, aligning information across these diverse data sources remains a challenge in the literature. Previous work has partially addressed this issue by enriching knowledge graph entities based on "hard" co-occurrence of words present in the entities of the knowledge graphs and external text, while we achieve "soft" augmentation by proposing a knowledge graph enrichment and embedding framework named Edge. Given an original knowledge graph, we first generate a rich but noisy augmented graph using external texts in semantic and structural level. To distill the relevant knowledge and suppress the introduced noise, we design a graph alignment term in a shared embedding space between the original graph and augmented graph. To enhance the embedding learning on the augmented graph, we further regularize the locality relationship of target entity based on negative sampling. Experimental results on four benchmark datasets demonstrate the robustness and effectiveness of Edge in link prediction and node classification.