 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4's assessment of its performance in a USMLE-based case study
Feb 15, 2024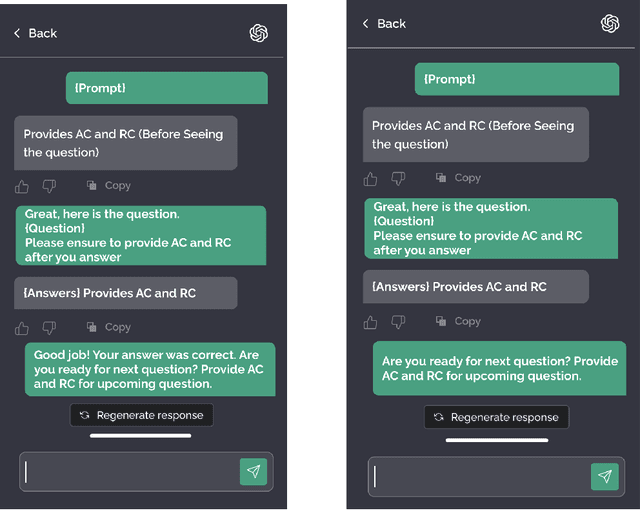
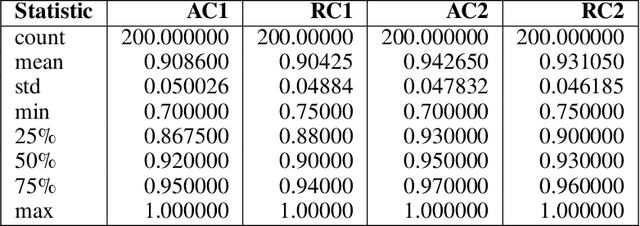
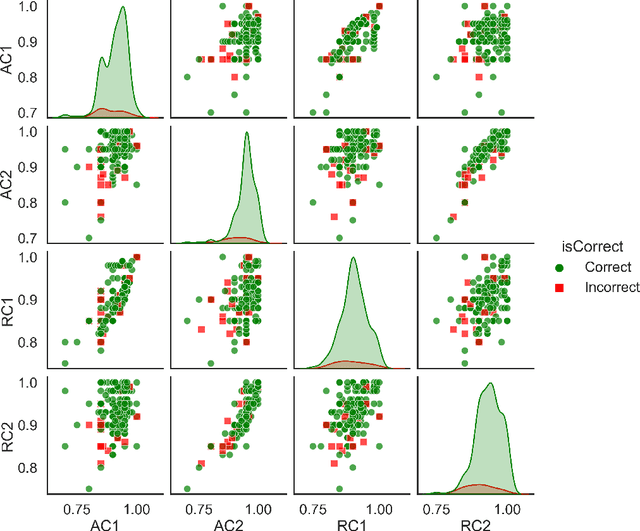
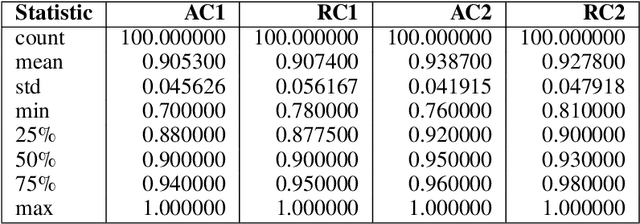
This study investigates GPT-4's assessment of its performance in healthcare applications. A simple prompting technique was used to prompt the LLM with questions taken from the United States Medical Licensing Examination (USMLE) questionnaire and it was tasked to evaluate its confidence score before posing the question and after asking the question. The questionnaire was categorized into two groups-questions with feedback (WF) and questions with no feedback(NF) post-question. The model was asked to provide absolute and relative confidence scores before and after each question. The experimental findings were analyzed using statistical tools to study the variability of confidence in WF and NF groups. Additionally, a sequential analysis was conducted to observe the performance variation for the WF and NF groups. Results indicate that feedback influences relative confidence but doesn't consistently increase or decrease it. Understanding the performance of LLM is paramount in exploring its utility in sensitive areas like healthcare. This study contributes to the ongoing discourse on the reliability of AI, particularly of LLMs like GPT-4, within healthcare, offering insights into how feedback mechanisms might be optimized to enhance AI-assisted medical education and decision support.