 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-knowledge LLM hallucination detection and mitigation through fine-grained cross-model consistency
Aug 19, 2025Large language models (LLMs) have demonstrated impressive capabilities across diverse tasks, but they remain susceptible to hallucinations--generating content that appears plausible but contains factual inaccuracies. We present Finch-Zk, a black-box framework that leverages FINe-grained Cross-model consistency to detect and mitigate Hallucinations in LLM outputs without requiring external knowledge sources. Finch-Zk introduces two key innovations: 1) a cross-model consistency checking strategy that reveals fine-grained inaccuracies by comparing responses generated by diverse models from semantically-equivalent prompts, and 2) a targeted mitigation technique that applies precise corrections to problematic segments while preserving accurate content. Experiments on the FELM dataset show Finch-Zk improves hallucination detection F1 scores by 6-39\% compared to existing approaches. For mitigation, Finch-Zk achieves 7-8 absolute percentage points improvement in answer accuracy on the GPQA-diamond dataset when applied to state-of-the-art models like Llama 4 Maverick and Claude 4 Sonnet. Extensive evaluation across multiple models demonstrates that Finch-Zk provides a practical, deployment-ready safeguard for enhancing factual reliability in production LLM systems.
Graph of Attacks with Pruning: Optimizing Stealthy Jailbreak Prompt Generation for Enhanced LLM Content Moderation
Jan 28, 2025We present a modular pipeline that automates the generation of stealthy jailbreak prompts derived from high-level content policies, enhancing LLM content moderation. First, we address query inefficiency and jailbreak strength by developing Graph of Attacks with Pruning (GAP), a method that utilizes strategies from prior jailbreaks, resulting in 92% attack success rate on GPT-3.5 using only 54% of the queries of the prior algorithm. Second, we address the cold-start issue by automatically generating seed prompts from the high-level policy using LLMs. Finally, we demonstrate the utility of these generated jailbreak prompts of improving content moderation by fine-tuning PromptGuard, a model trained to detect jailbreaks, increasing its accuracy on the Toxic-Chat dataset from 5.1% to 93.89%.
EvoSTS Forecasting: Evolutionary Sparse Time-Series Forecasting
Apr 14, 2022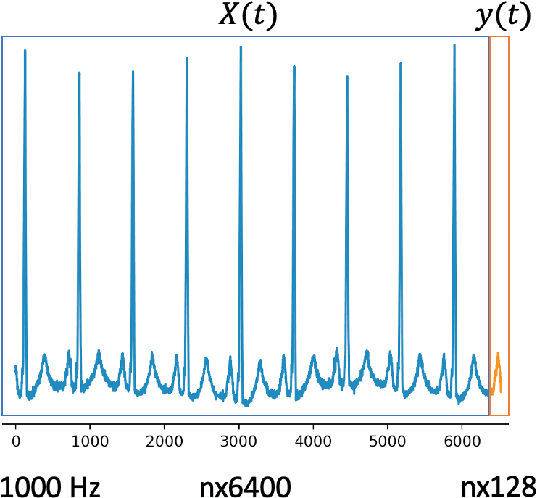
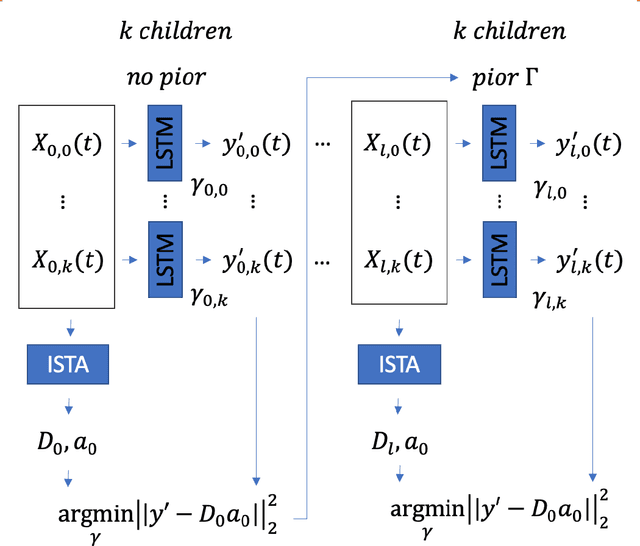

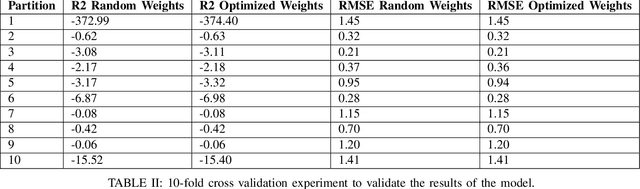
In this work, we highlight our novel evolutionary sparse time-series forecasting algorithm also known as EvoSTS. The algorithm attempts to evolutionary prioritize weights of Long Short-Term Memory (LSTM) Network that best minimize the reconstruction loss of a predicted signal using a learned sparse coded dictionary. In each generation of our evolutionary algorithm, a set number of children with the same initial weights are spawned. Each child undergoes a training step and adjusts their weights on the same data. Due to stochastic back-propagation, the set of children has a variety of weights with different levels of performance. The weights that best minimize the reconstruction loss with a given signal dictionary are passed to the next generation. The predictions from the best-performing weights of the first and last generation are compared. We found improvements while comparing the weights of these two generations. However, due to several confounding parameters and hyperparameter limitations, some of the weights had negligible improvements. To the best of our knowledge, this is the first attempt to use sparse coding in this way to optimize time series forecasting model weights, such as those of an LSTM network.
Towards Searching Efficient and Accurate Neural Network Architectures in Binary Classification Problems
Jan 16, 2021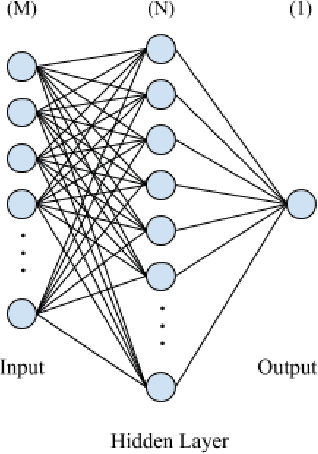
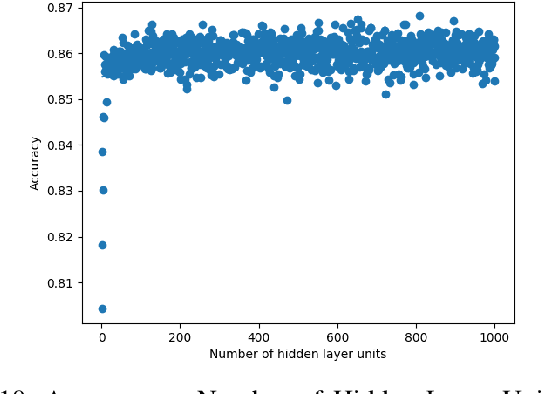
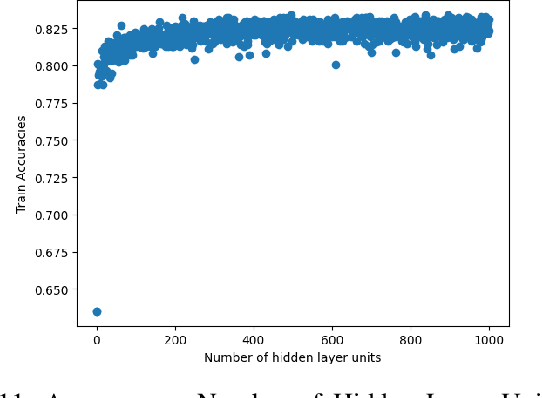
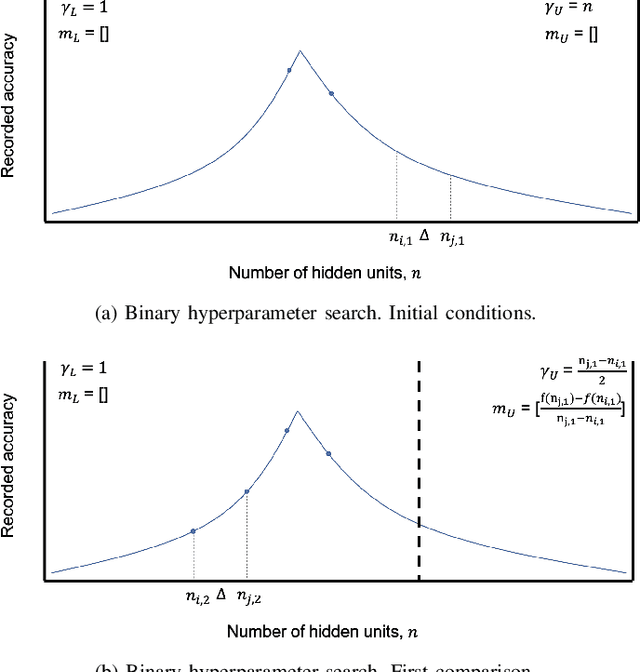
In recent years, deep neural networks have had great success in machine learning and pattern recognition. Architecture size for a neural network contributes significantly to the success of any neural network. In this study, we optimize the selection process by investigating different search algorithms to find a neural network architecture size that yields the highest accuracy. We apply binary search on a very well-defined binary classification network search space and compare the results to those of linear search. We also propose how to relax some of the assumptions regarding the dataset so that our solution can be generalized to any binary classification problem. We report a 100-fold running time improvement over the naive linear search when we apply the binary search method to our datasets in order to find the best architecture candidate. By finding the optimal architecture size for any binary classification problem quickly, we hope that our research contributes to discovering intelligent algorithms for optimizing architecture size selection in machine learning.