 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATRAS: Adversarially Trained Robust Architecture Search
Jun 13, 2021

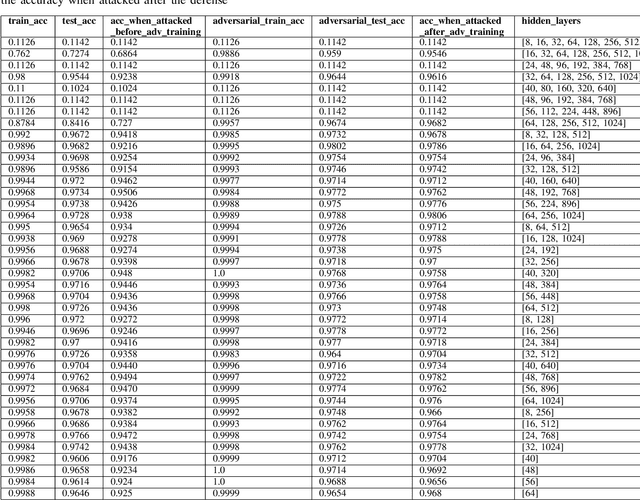
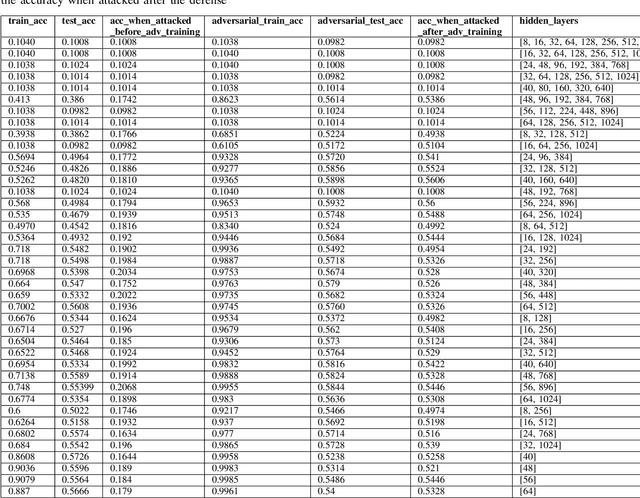
In this paper, we explore the effect of architecture completeness on adversarial robustness. We train models with different architectures on CIFAR-10 and MNIST dataset. For each model, we vary different number of layers and different number of nodes in the layer. For every architecture candidate, we use Fast Gradient Sign Method (FGSM) to generate untargeted adversarial attacks and use adversarial training to defend against those attacks. For each architecture candidate, we report pre-attack, post-attack and post-defense accuracy for the model as well as the architecture parameters and the impact of completeness to the model accuracies.
Functional Protein Structure Annotation Using a Deep Convolutional Generative Adversarial Network
Apr 18, 2021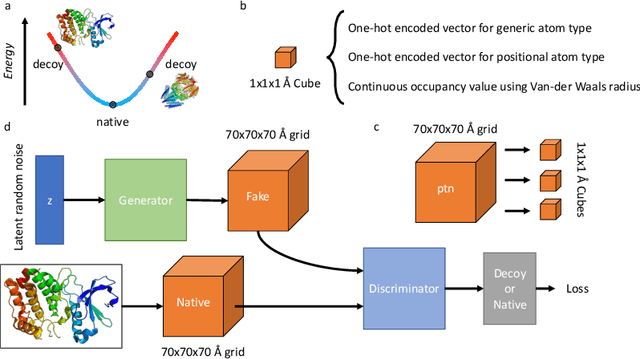
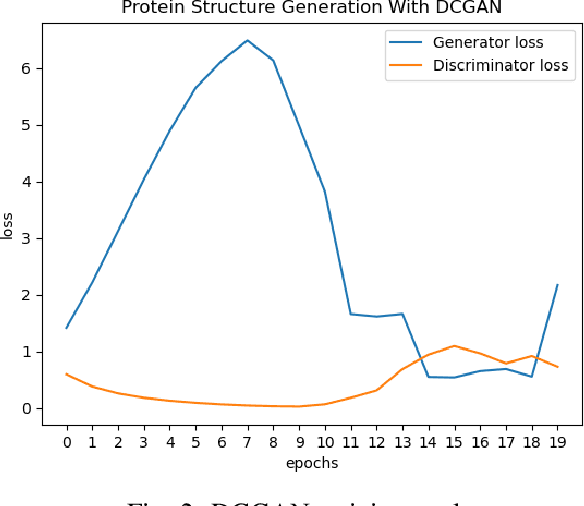
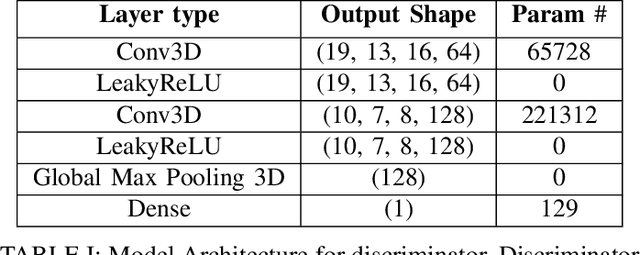
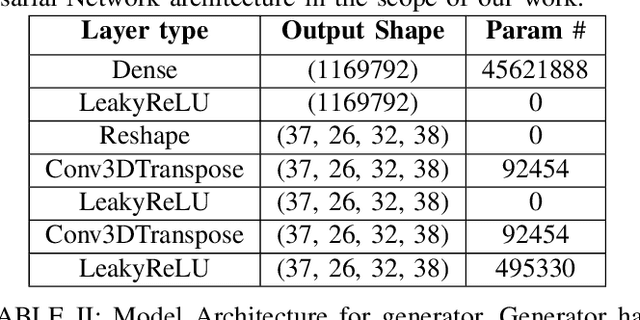
Identifying novel functional protein structures is at the heart of molecular engineering and molecular biology, requiring an often computationally exhaustive search. We introduce the use of a Deep Convolutional Generative Adversarial Network (DCGAN) to classify protein structures based on their functionality by encoding each sample in a grid object structure using three features in each object: the generic atom type, the position atom type, and its occupancy relative to a given atom. We train DCGAN on 3-dimensional (3D) decoy and native protein structures in order to generate and discriminate 3D protein structures. At the end of our training, loss converges to a local minimum and our DCGAN can annotate functional proteins robustly against adversarial protein samples. In the future we hope to extend the novel structures we found from the generator in our DCGAN with more samples to explore more granular functionality with varying functions. We hope that our effort will advance the field of protein structure prediction.
Extreme Volatility Prediction in Stock Market: When GameStop meets Long Short-Term Memory Networks
Mar 09, 2021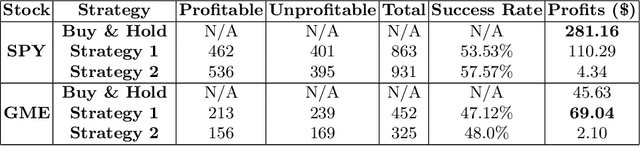
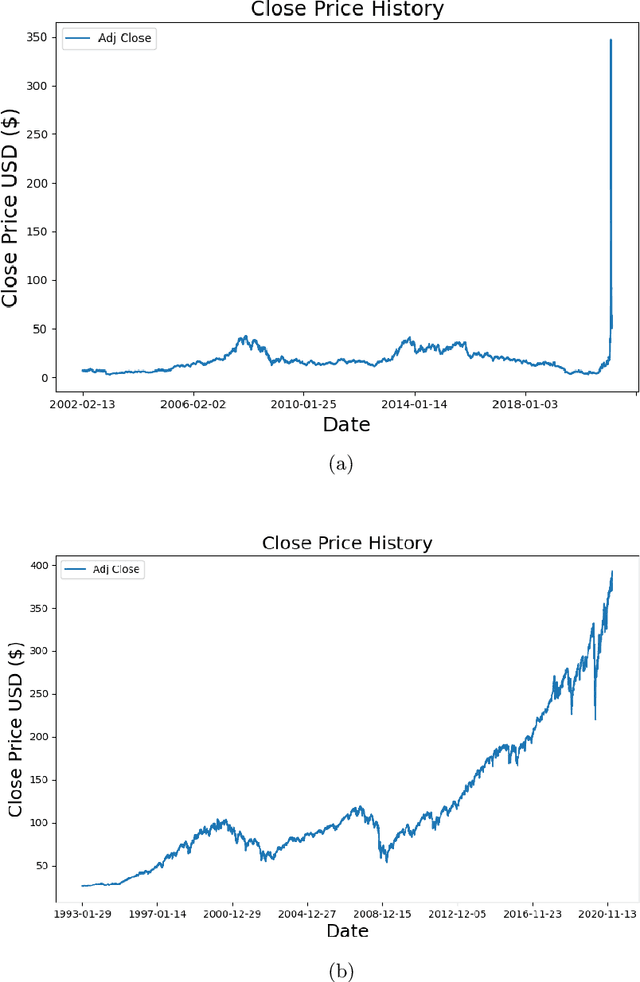
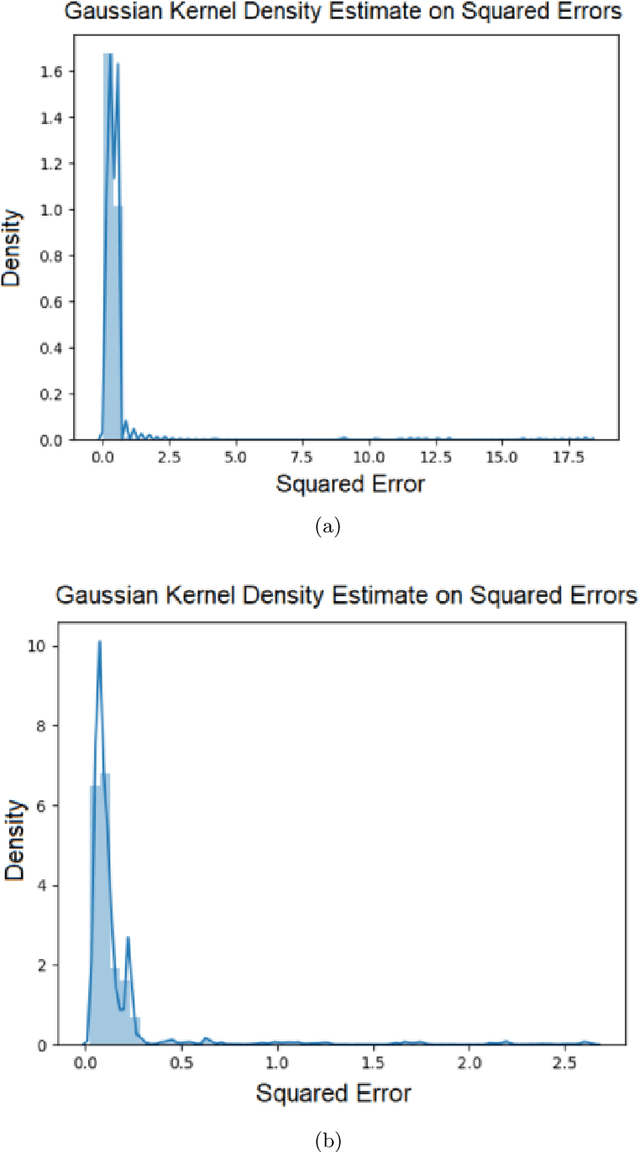
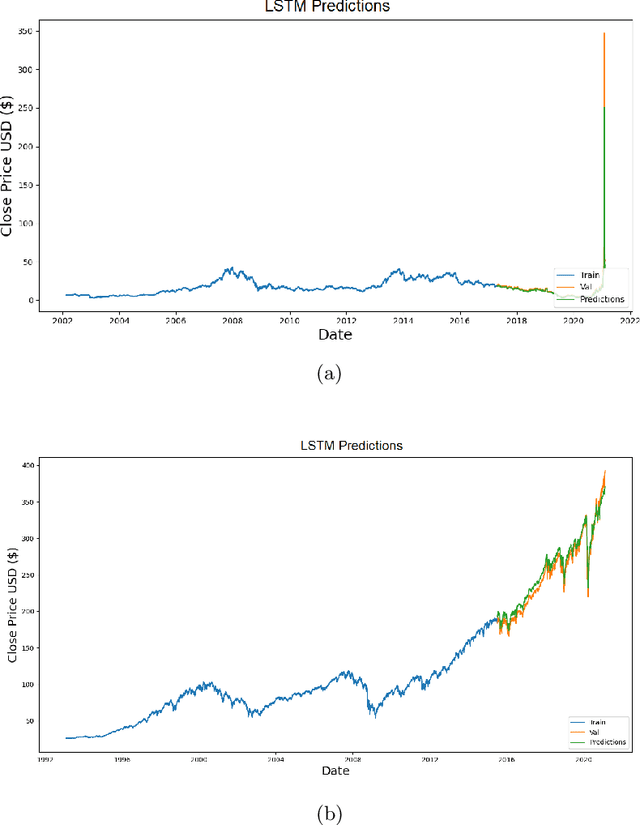
The beginning of 2021 saw a surge in volatility for certain stocks such as GameStop company stock (Ticker GME under NYSE). GameStop stock increased around 10 fold from its decade-long average to its peak at \$485. In this paper, we hypothesize a buy-and-hold strategy can be outperformed in the presence of extreme volatility by predicting and trading consolidation breakouts. We investigate GME stock for its volatility and compare it to SPY as a benchmark (since it is a less volatile ETF fund) from February 2002 to February 2021. For strategy 1, we develop a Long Short-term Memory (LSTM) Neural Network to predict stock prices recurrently with a very short look ahead period in the presence of extreme volatility. For our strategy 2, we develop an LSTM autoencoder network specifically designed to trade only on consolidation breakouts after predicting anomalies in the stock price. When back-tested in our simulations, our strategy 1 executes 863 trades for SPY and 452 trades for GME. Our strategy 2 executes 931 trades for SPY and 325 trades for GME. We compare both strategies to buying and holding one single share for the period that we picked as a benchmark. In our simulations, SPY returns \$281.160 from buying and holding one single share, \$110.29 from strategy 1 with 53.5% success rate and \$4.34 from strategy 2 with 57.6% success rate. GME returns \$45.63 from buying and holding one single share, \$69.046 from strategy 1 with 47.12% success rate and \$2.10 from strategy 2 with 48% success rate. Overall, buying and holding outperforms all deep-learning assisted prediction models in our study except for when the LSTM-based prediction model (strategy 1) is applied to GME. We hope that our study sheds more light into the field of extreme volatility predictions based on LSTMs to outperform buying and holding strategy.
Robust SleepNets
Feb 24, 2021

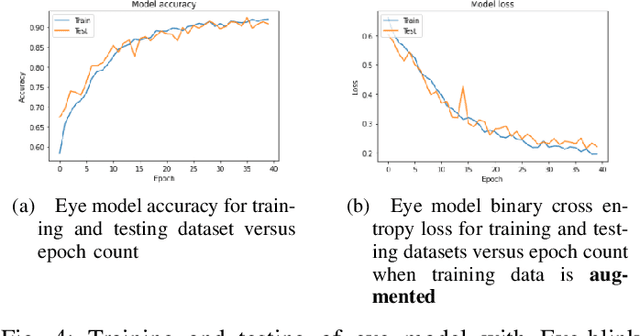
State-of-the-art convolutional neural networks excel in machine learning tasks such as face recognition, and object classification but suffer significantly when adversarial attacks are present. It is crucial that machine critical systems, where machine learning models are deployed, utilize robust models to handle a wide range of variability in the real world and malicious actors that may use adversarial attacks. In this study, we investigate eye closedness detection to prevent vehicle accidents related to driver disengagements and driver drowsiness. Specifically, we focus on adversarial attacks in this application domain, but emphasize that the methodology can be applied to many other domains. We develop two models to detect eye closedness: first model on eye images and a second model on face images. We adversarially attack the models with Projected Gradient Descent, Fast Gradient Sign and DeepFool methods and report adversarial success rate. We also study the effect of training data augmentation. Finally, we adversarially train the same models on perturbed images and report the success rate for the defense against these attacks. We hope our study sets up the work to prevent potential vehicle accidents by capturing drivers' face images and alerting them in case driver's eyes are closed due to drowsiness.
Evaluating Online and Offline Accuracy Traversal Algorithms for k-Complete Neural Network Architectures
Jan 16, 2021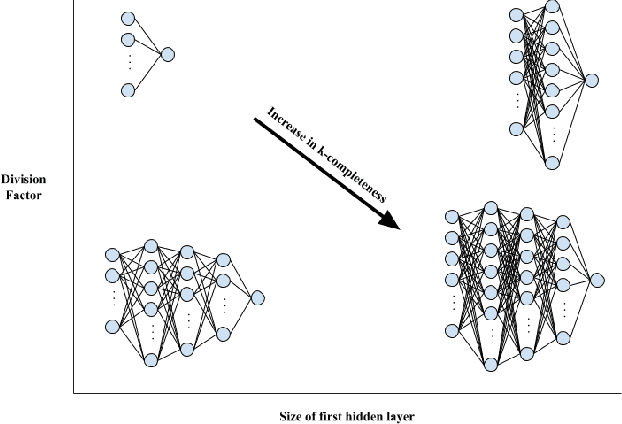
Architecture sizes for neural networks have been studied widely and several search methods have been offered to find the best architecture size in the shortest amount of time possible. In this paper, we study compact neural network architectures for binary classification and investigate improvements in speed and accuracy when favoring overcomplete architecture candidates that have a very high-dimensional representation of the input. We hypothesize that an overcomplete model architecture that creates a relatively high-dimensional representation of the input will be not only be more accurate but would also be easier and faster to find. In an NxM search space, we propose an online traversal algorithm that finds the best architecture candidate in O(1) time for best case and O(N) amortized time for average case for any compact binary classification problem by using k-completeness as heuristics in our search. The two other offline search algorithms we implement are brute force traversal and diagonal traversal, which both find the best architecture candidate in O(NxM) time. We compare our new algorithm to brute force and diagonal searching as a baseline and report search time improvement of 52.1% over brute force and of 15.4% over diagonal search to find the most accurate neural network architecture when given the same dataset. In all cases discussed in the paper, our online traversal algorithm can find an accurate, if not better, architecture in significantly shorter amount of time.
Towards Searching Efficient and Accurate Neural Network Architectures in Binary Classification Problems
Jan 16, 2021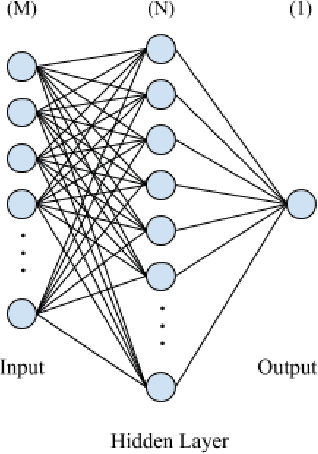
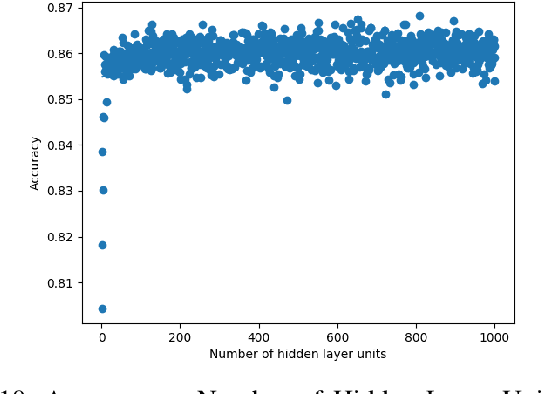
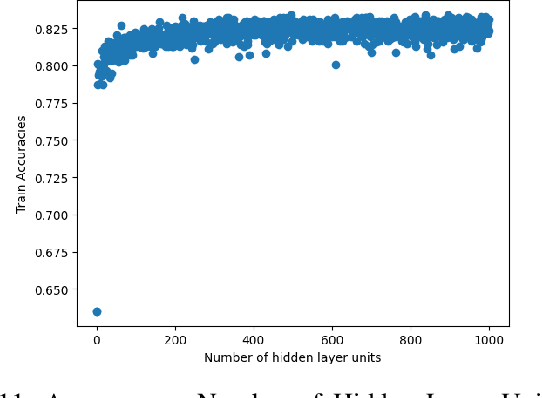
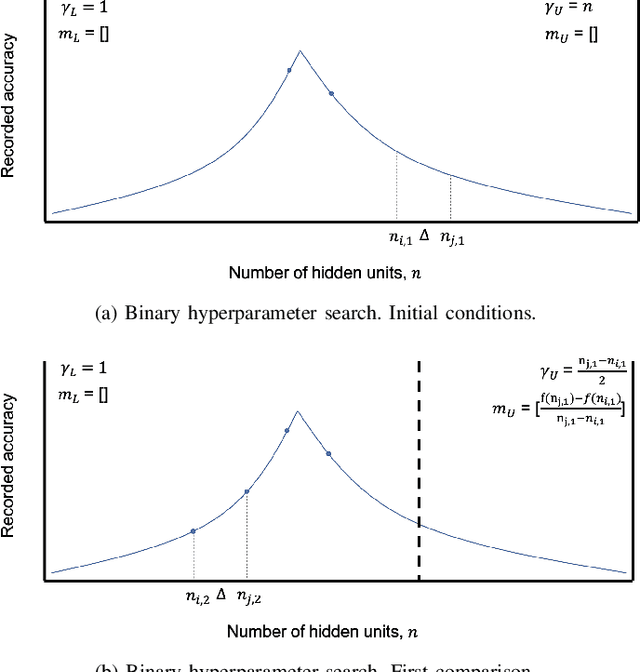
In recent years, deep neural networks have had great success in machine learning and pattern recognition. Architecture size for a neural network contributes significantly to the success of any neural network. In this study, we optimize the selection process by investigating different search algorithms to find a neural network architecture size that yields the highest accuracy. We apply binary search on a very well-defined binary classification network search space and compare the results to those of linear search. We also propose how to relax some of the assumptions regarding the dataset so that our solution can be generalized to any binary classification problem. We report a 100-fold running time improvement over the naive linear search when we apply the binary search method to our datasets in order to find the best architecture candidate. By finding the optimal architecture size for any binary classification problem quickly, we hope that our research contributes to discovering intelligent algorithms for optimizing architecture size selection in machine learning.
Towards Evaluating Driver Fatigue with Robust Deep Learning Models
Jul 16, 2020
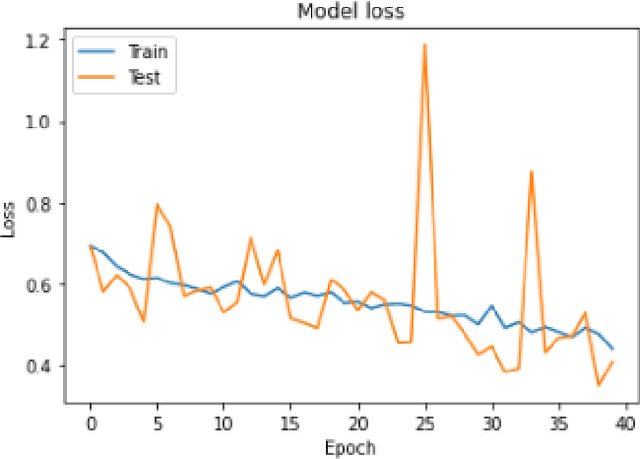
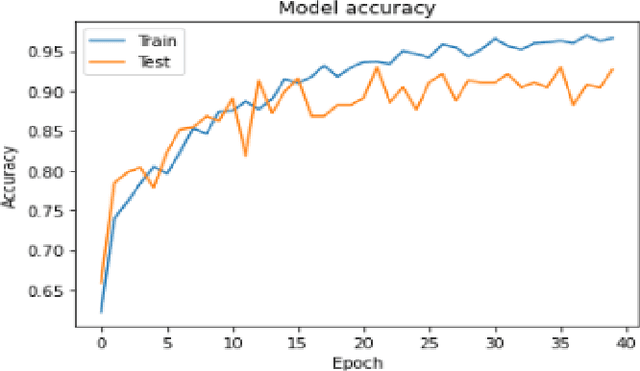
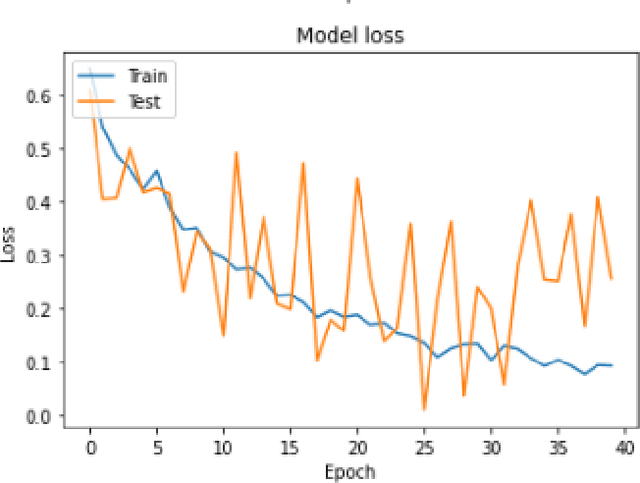
In this paper, we explore different deep learning based approaches to detect driver fatigue. Drowsy driving results in approximately 72,000 crashes and 44,000 injuries every year in the US and detecting drowsiness and alerting the driver can save many lives. There have been many approaches to detect fatigue, of which eye closedness detection is one. We propose a framework to detect eye closedness in a captured camera frame as a gateway for detecting drowsiness. We explore two different datasets to detect eye closedness. We develop an eye model by using new Eye-blink dataset and a face model by using the Closed Eyes in the Wild (CEW). We also explore different techniques to make the models more robust by adding noise. We achieve 95.84% accuracy on our eye model that detects eye blinking and 80.01% accuracy on our face model that detects eye blinking. We also see that we can improve our accuracy on the face model by 6% when we add noise to our training data and apply data augmentation. We hope that our work will be useful to the field of driver fatigue detection to avoid potential vehicle accidents related to drowsy driving.
Adversarial Attacks against Neural Networks in Audio Domain: Exploiting Principal Components
Jul 14, 2020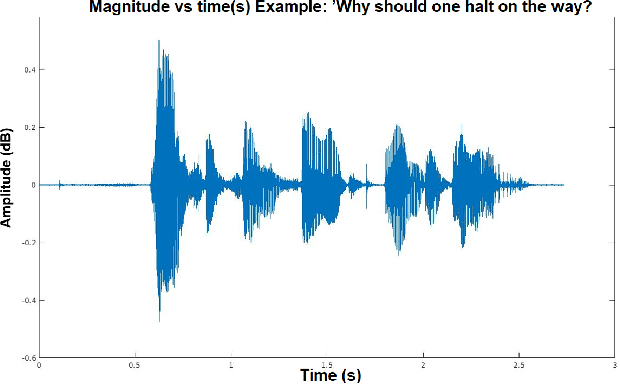
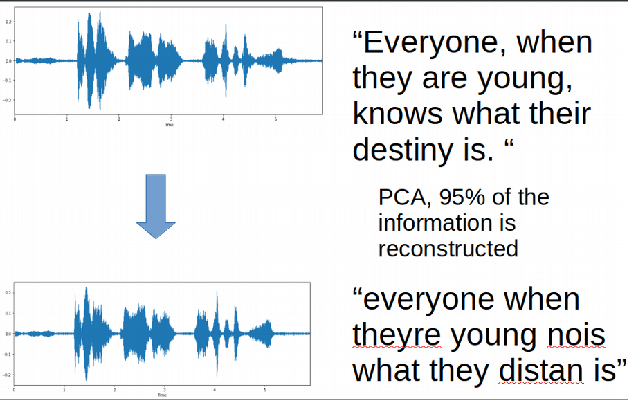

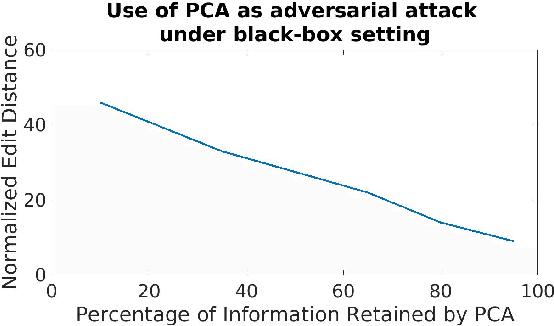
Adversarial attacks are inputs that are similar to original inputs but altered on purpose. Speech-to-text neural networks that are widely used today are prone to misclassify adversarial attacks. In this study, first, we investigate the presence of targeted adversarial attacks by altering wave forms from Common Voice data set. We craft adversarial wave forms via Connectionist Temporal Classification Loss Function, and attack DeepSpeech, a speech-to-text neural network implemented by Mozilla. We achieve 100% adversarial success rate (zero successful classification by DeepSpeech) on all 25 adversarial wave forms that we crafted. Second, we investigate the use of PCA as a defense mechanism against adversarial attacks. We reduce dimensionality by applying PCA to these 25 attacks that we created and test them against DeepSpeech. We observe zero successful classification by DeepSpeech, which suggests PCA is not a good defense mechanism in audio domain. Finally, instead of using PCA as a defense mechanism, we use PCA this time to craft adversarial inputs under a black-box setting with minimal adversarial knowledge. With no knowledge regarding the model, parameters, or weights, we craft adversarial attacks by applying PCA to samples from Common Voice data set and achieve 100% adversarial success under black-box setting again when tested against DeepSpeech. We also experiment with different percentage of components necessary to result in a classification during attacking process. In all cases, adversary becomes successful.
Towards Evaluating Gaussian Blurring in Perceptual Hashing as a Facial Image Filter
Feb 01, 2020
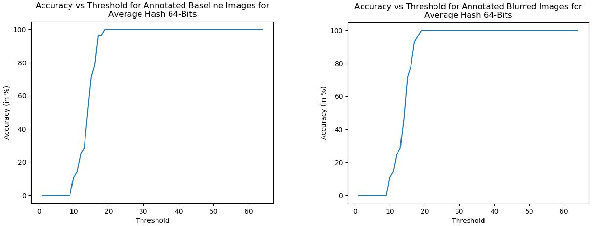
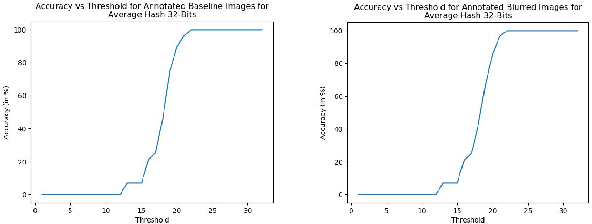
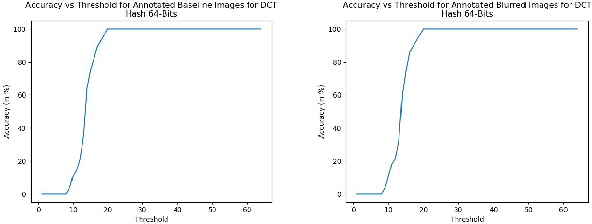
With the growth in social media, there is a huge amount of images of faces available on the internet. Often, people use other people's pictures on their own profile. Perceptual hashing is often used to detect whether two images are identical. Therefore, it can be used to detect whether people are misusing others' pictures. In perceptual hashing, a hash is calculated for a given image, and a new test image is mapped to one of the existing hashes if duplicate features are present. Therefore, it can be used as an image filter to flag banned image content or adversarial attacks --which are modifications that are made on purpose to deceive the filter-- even though the content might be changed to deceive the filters. For this reason, it is critical for perceptual hashing to be robust enough to take transformations such as resizing, cropping, and slight pixel modifications into account. In this paper, we would like to propose to experiment with effect of gaussian blurring in perceptual hashing for detecting misuse of personal images specifically for face images. We hypothesize that use of gaussian blurring on the image before calculating its hash will increase the accuracy of our filter that detects adversarial attacks which consist of image cropping, adding text annotation, and image rotation.
Adversarial Attacks on Convolutional Neural Networks in Facial Recognition Domain
Jan 30, 2020

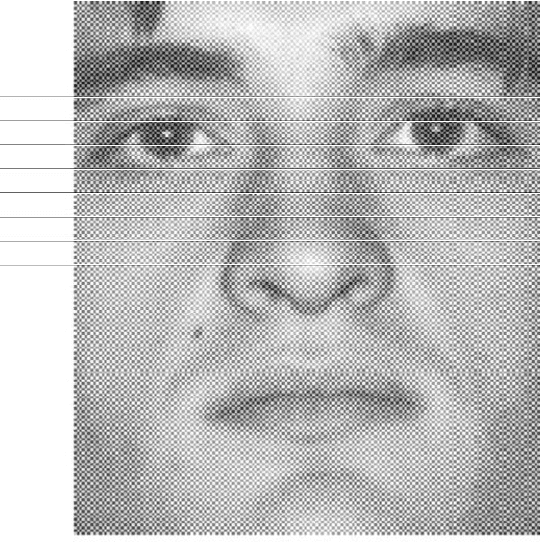
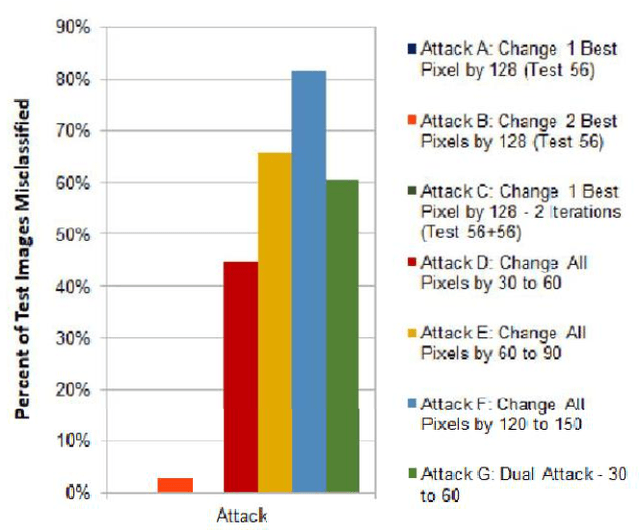
Numerous recent studies have demonstrated how Deep Neural Network (DNN) classifiers can be fooled by adversarial examples, in which an attacker adds perturbations to an original sample, causing the classifier to misclassify the sample. Adversarial attacks that render DNNs vulnerable in real life represent a serious threat, given the consequences of improperly functioning autonomous vehicles, malware filters, or biometric authentication systems. In this paper, we apply Fast Gradient Sign Method to introduce perturbations to a facial image dataset and then test the output on a different classifier that we trained ourselves, to analyze transferability of this method. Next, we craft a variety of different attack algorithms on a facial image dataset, with the intention of developing untargeted black-box approaches assuming minimal adversarial knowledge, to further assess the robustness of DNNs in the facial recognition realm. We explore modifying single optimal pixels by a large amount, or modifying all pixels by a smaller amount, or combining these two attack approaches. While our single-pixel attacks achieved about a 15% average decrease in classifier confidence level for the actual class, the all-pixel attacks were more successful and achieved up to an 84% average decrease in confidence, along with an 81.6% misclassification rate, in the case of the attack that we tested with the highest levels of perturbation. Even with these high levels of perturbation, the face images remained fairly clearly identifiable to a human. We hope our research may help to advance the study of adversarial attacks on DNNs and defensive mechanisms to counteract them, particularly in the facial recognition domain.