 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks on Convolutional Neural Networks in Facial Recognition Domain
Jan 30, 2020

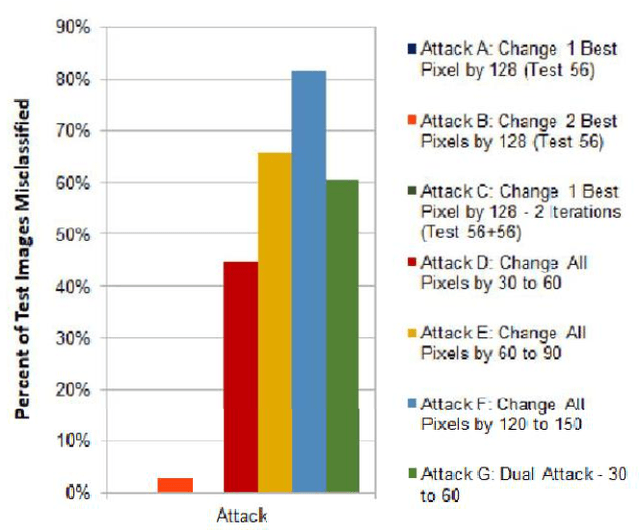
Numerous recent studies have demonstrated how Deep Neural Network (DNN) classifiers can be fooled by adversarial examples, in which an attacker adds perturbations to an original sample, causing the classifier to misclassify the sample. Adversarial attacks that render DNNs vulnerable in real life represent a serious threat, given the consequences of improperly functioning autonomous vehicles, malware filters, or biometric authentication systems. In this paper, we apply Fast Gradient Sign Method to introduce perturbations to a facial image dataset and then test the output on a different classifier that we trained ourselves, to analyze transferability of this method. Next, we craft a variety of different attack algorithms on a facial image dataset, with the intention of developing untargeted black-box approaches assuming minimal adversarial knowledge, to further assess the robustness of DNNs in the facial recognition realm. We explore modifying single optimal pixels by a large amount, or modifying all pixels by a smaller amount, or combining these two attack approaches. While our single-pixel attacks achieved about a 15% average decrease in classifier confidence level for the actual class, the all-pixel attacks were more successful and achieved up to an 84% average decrease in confidence, along with an 81.6% misclassification rate, in the case of the attack that we tested with the highest levels of perturbation. Even with these high levels of perturbation, the face images remained fairly clearly identifiable to a human. We hope our research may help to advance the study of adversarial attacks on DNNs and defensive mechanisms to counteract them, particularly in the facial recognition domain.