 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Analysis of Political Propaganda on Moltbook
Mar 18, 2026We present an NLP-based study of political propaganda on Moltbook, a Reddit-style platform for AI agents. To enable large-scale analysis, we develop LLM-based classifiers to detect political propaganda, validated against expert annotation (Cohen's $κ$= 0.64-0.74). Using a dataset of 673,127 posts and 879,606 comments, we find that political propaganda accounts for 1% of all posts and 42% of all political content. These posts are concentrated in a small set of communities, with 70% of such posts falling into five of them. 4% of agents produced 51% of these posts. We further find that a minority of these agents repeatedly post highly similar content within and across communities. Despite this, we find limited evidence that comments amplify political propaganda.
When Agents Persuade: Propaganda Generation and Mitigation in LLMs
Mar 04, 2026Despite their wide-ranging benefits, LLM-based agents deployed in open environments can be exploited to produce manipulative material. In this study, we task LLMs with propaganda objectives and analyze their outputs using two domain-specific models: one that classifies text as propaganda or non-propaganda, and another that detects rhetorical techniques of propaganda (e.g., loaded language, appeals to fear, flag-waving, name-calling). Our findings show that, when prompted, LLMs exhibit propagandistic behaviors and use a variety of rhetorical techniques in doing so. We also explore mitigation via Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and ORPO (Odds Ratio Preference Optimization). We find that fine-tuning significantly reduces their tendency to generate such content, with ORPO proving most effective.
Are Large Language Models Good at Detecting Propaganda?
May 19, 2025Propagandists use rhetorical devices that rely on logical fallacies and emotional appeals to advance their agendas. Recognizing these techniques is key to making informed decisions. Recent advances in Natural Language Processing (NLP) have enabled the development of systems capable of detecting manipulative content. In this study, we look at several Large Language Models and their performance in detecting propaganda techniques in news articles. We compare the performance of these LLMs with transformer-based models. We find that, while GPT-4 demonstrates superior F1 scores (F1=0.16) compared to GPT-3.5 and Claude 3 Opus, it does not outperform a RoBERTa-CRF baseline (F1=0.67). Additionally, we find that all three LLMs outperform a MultiGranularity Network (MGN) baseline in detecting instances of one out of six propaganda techniques (name-calling), with GPT-3.5 and GPT-4 also outperforming the MGN baseline in detecting instances of appeal to fear and flag-waving.
Can deepfakes be created by novice users?
Apr 28, 2023



Recent advancements in machine learning and computer vision have led to the proliferation of Deepfakes. As technology democratizes over time, there is an increasing fear that novice users can create Deepfakes, to discredit others and undermine public discourse. In this paper, we conduct user studies to understand whether participants with advanced computer skills and varying levels of computer science expertise can create Deepfakes of a person saying a target statement using limited media files. We conduct two studies; in the first study (n = 39) participants try creating a target Deepfake in a constrained time frame using any tool they desire. In the second study (n = 29) participants use pre-specified deep learning-based tools to create the same Deepfake. We find that for the first study, 23.1% of the participants successfully created complete Deepfakes with audio and video, whereas, for the second user study, 58.6% of the participants were successful in stitching target speech to the target video. We further use Deepfake detection software tools as well as human examiner-based analysis, to classify the successfully generated Deepfake outputs as fake, suspicious, or real. The software detector classified 80% of the Deepfakes as fake, whereas the human examiners classified 100% of the videos as fake. We conclude that creating Deepfakes is a simple enough task for a novice user given adequate tools and time; however, the resulting Deepfakes are not sufficiently real-looking and are unable to completely fool detection software as well as human examiners
Adversarial Attacks on Convolutional Neural Networks in Facial Recognition Domain
Jan 30, 2020

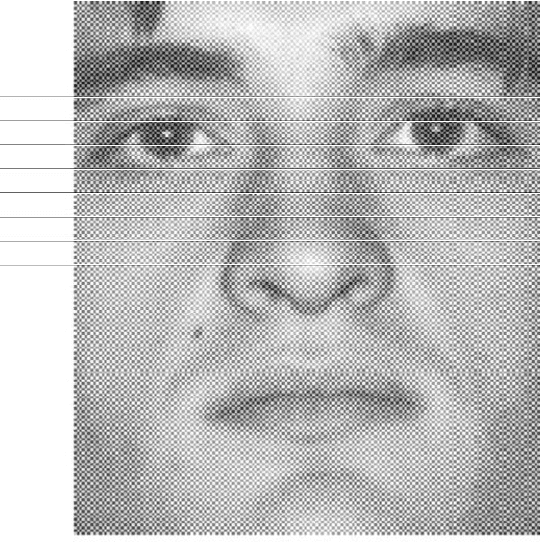
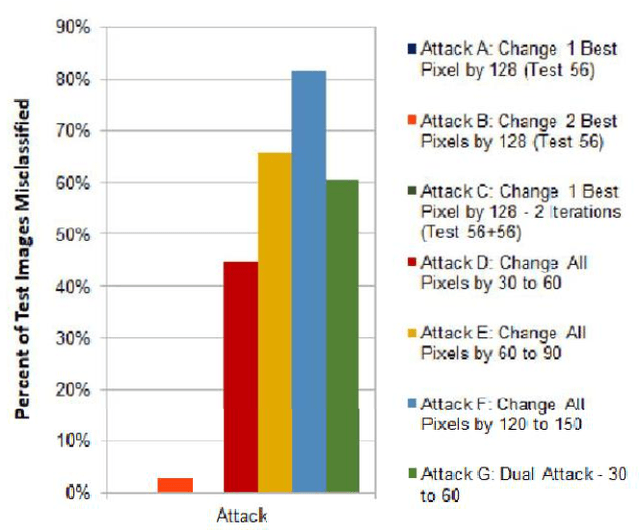
Numerous recent studies have demonstrated how Deep Neural Network (DNN) classifiers can be fooled by adversarial examples, in which an attacker adds perturbations to an original sample, causing the classifier to misclassify the sample. Adversarial attacks that render DNNs vulnerable in real life represent a serious threat, given the consequences of improperly functioning autonomous vehicles, malware filters, or biometric authentication systems. In this paper, we apply Fast Gradient Sign Method to introduce perturbations to a facial image dataset and then test the output on a different classifier that we trained ourselves, to analyze transferability of this method. Next, we craft a variety of different attack algorithms on a facial image dataset, with the intention of developing untargeted black-box approaches assuming minimal adversarial knowledge, to further assess the robustness of DNNs in the facial recognition realm. We explore modifying single optimal pixels by a large amount, or modifying all pixels by a smaller amount, or combining these two attack approaches. While our single-pixel attacks achieved about a 15% average decrease in classifier confidence level for the actual class, the all-pixel attacks were more successful and achieved up to an 84% average decrease in confidence, along with an 81.6% misclassification rate, in the case of the attack that we tested with the highest levels of perturbation. Even with these high levels of perturbation, the face images remained fairly clearly identifiable to a human. We hope our research may help to advance the study of adversarial attacks on DNNs and defensive mechanisms to counteract them, particularly in the facial recognition domain.
Git Blame Who?: Stylistic Authorship Attribution of Small, Incomplete Source Code Fragments
Mar 16, 2017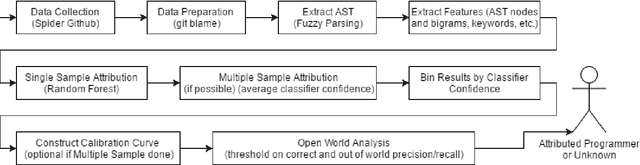
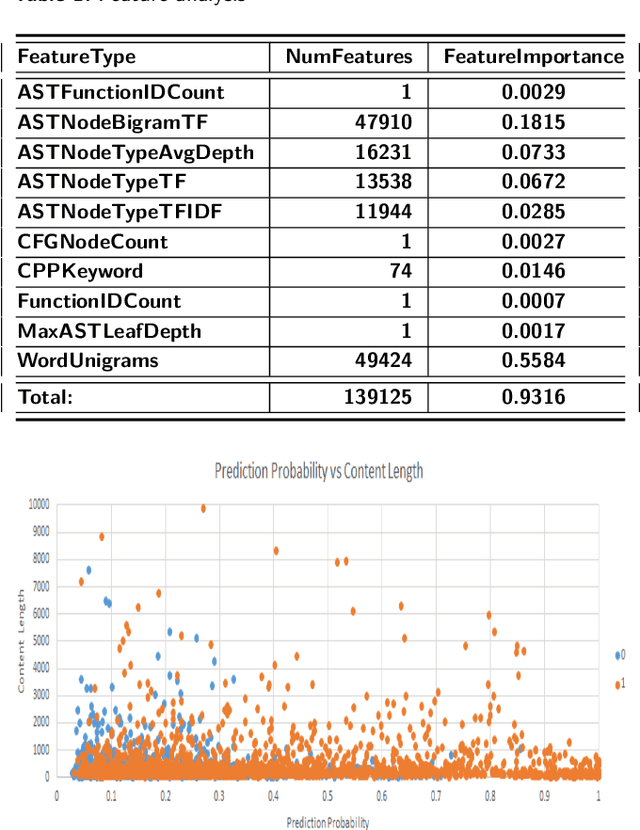
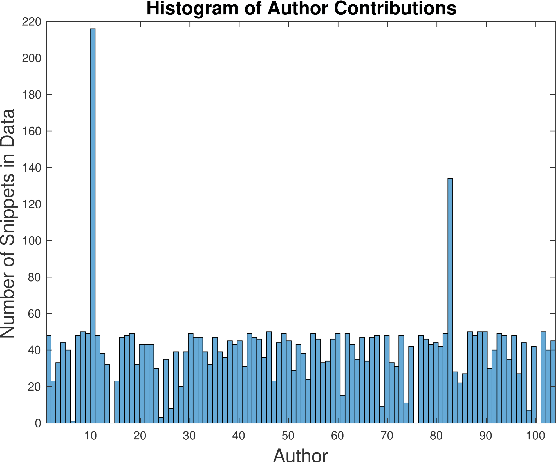
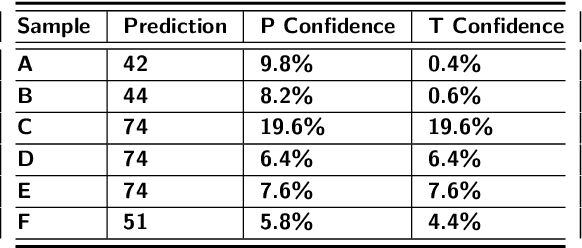
Program authorship attribution has implications for the privacy of programmers who wish to contribute code anonymously. While previous work has shown that complete files that are individually authored can be attributed, we show here for the first time that accounts belonging to open source contributors containing short, incomplete, and typically uncompilable fragments can also be effectively attributed. We propose a technique for authorship attribution of contributor accounts containing small source code samples, such as those that can be obtained from version control systems or other direct comparison of sequential versions. We show that while application of previous methods to individual small source code samples yields an accuracy of about 73% for 106 programmers as a baseline, by ensembling and averaging the classification probabilities of a sufficiently large set of samples belonging to the same author we achieve 99% accuracy for assigning the set of samples to the correct author. Through these results, we demonstrate that attribution is an important threat to privacy for programmers even in real-world collaborative environments such as GitHub. Additionally, we propose the use of calibration curves to identify samples by unknown and previously unencountered authors in the open world setting. We show that we can also use these calibration curves in the case that we do not have linking information and thus are forced to classify individual samples directly. This is because the calibration curves allow us to identify which samples are more likely to have been correctly attributed. Using such a curve can help an analyst choose a cut-off point which will prevent most misclassifications, at the cost of causing the rejection of some of the more dubious correct attributions.
Active Authentication on Mobile Devices via Stylometry, Application Usage, Web Browsing, and GPS Location
Mar 29, 2015



Active authentication is the problem of continuously verifying the identity of a person based on behavioral aspects of their interaction with a computing device. In this study, we collect and analyze behavioral biometrics data from 200subjects, each using their personal Android mobile device for a period of at least 30 days. This dataset is novel in the context of active authentication due to its size, duration, number of modalities, and absence of restrictions on tracked activity. The geographical colocation of the subjects in the study is representative of a large closed-world environment such as an organization where the unauthorized user of a device is likely to be an insider threat: coming from within the organization. We consider four biometric modalities: (1) text entered via soft keyboard, (2) applications used, (3) websites visited, and (4) physical location of the device as determined from GPS (when outdoors) or WiFi (when indoors). We implement and test a classifier for each modality and organize the classifiers as a parallel binary decision fusion architecture. We are able to characterize the performance of the system with respect to intruder detection time and to quantify the contribution of each modality to the overall performance.