 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings
Nov 07, 2025In this work, we identify an inherent bias in prevailing LVLM architectures toward the language modality, largely resulting from the common practice of simply appending visual embeddings to the input text sequence. To address this, we propose a simple yet effective method that refines textual embeddings by integrating average-pooled visual features. Our approach demonstrably improves visual grounding and significantly reduces hallucinations on established benchmarks. While average pooling offers a straightforward, robust, and efficient means of incorporating visual information, we believe that more sophisticated fusion methods could further enhance visual grounding and cross-modal alignment. Given that the primary focus of this work is to highlight the modality imbalance and its impact on hallucinations -- and to show that refining textual embeddings with visual information mitigates this issue -- we leave exploration of advanced fusion strategies for future work.
Can deepfakes be created by novice users?
Apr 28, 2023



Recent advancements in machine learning and computer vision have led to the proliferation of Deepfakes. As technology democratizes over time, there is an increasing fear that novice users can create Deepfakes, to discredit others and undermine public discourse. In this paper, we conduct user studies to understand whether participants with advanced computer skills and varying levels of computer science expertise can create Deepfakes of a person saying a target statement using limited media files. We conduct two studies; in the first study (n = 39) participants try creating a target Deepfake in a constrained time frame using any tool they desire. In the second study (n = 29) participants use pre-specified deep learning-based tools to create the same Deepfake. We find that for the first study, 23.1% of the participants successfully created complete Deepfakes with audio and video, whereas, for the second user study, 58.6% of the participants were successful in stitching target speech to the target video. We further use Deepfake detection software tools as well as human examiner-based analysis, to classify the successfully generated Deepfake outputs as fake, suspicious, or real. The software detector classified 80% of the Deepfakes as fake, whereas the human examiners classified 100% of the videos as fake. We conclude that creating Deepfakes is a simple enough task for a novice user given adequate tools and time; however, the resulting Deepfakes are not sufficiently real-looking and are unable to completely fool detection software as well as human examiners
Adversarial Token Attacks on Vision Transformers
Oct 08, 2021
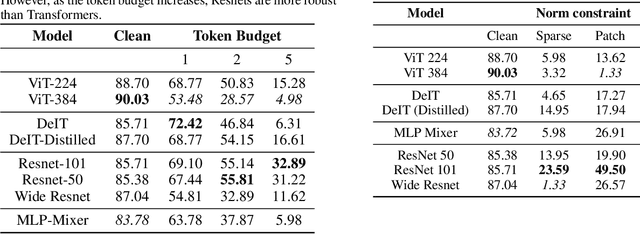
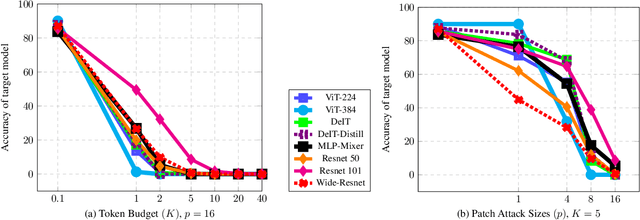

Vision transformers rely on a patch token based self attention mechanism, in contrast to convolutional networks. We investigate fundamental differences between these two families of models, by designing a block sparsity based adversarial token attack. We probe and analyze transformer as well as convolutional models with token attacks of varying patch sizes. We infer that transformer models are more sensitive to token attacks than convolutional models, with ResNets outperforming Transformer models by up to $\sim30\%$ in robust accuracy for single token attacks.
Provable Compressed Sensing with Generative Priors via Langevin Dynamics
Feb 25, 2021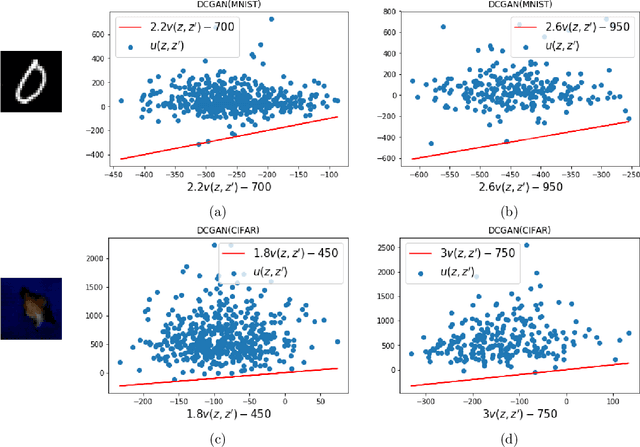


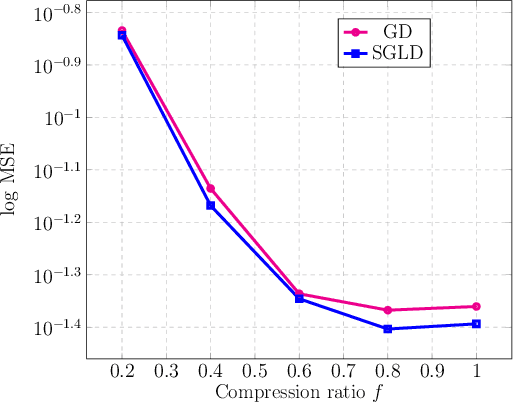
Deep generative models have emerged as a powerful class of priors for signals in various inverse problems such as compressed sensing, phase retrieval and super-resolution. Here, we assume an unknown signal to lie in the range of some pre-trained generative model. A popular approach for signal recovery is via gradient descent in the low-dimensional latent space. While gradient descent has achieved good empirical performance, its theoretical behavior is not well understood. In this paper, we introduce the use of stochastic gradient Langevin dynamics (SGLD) for compressed sensing with a generative prior. Under mild assumptions on the generative model, we prove the convergence of SGLD to the true signal. We also demonstrate competitive empirical performance to standard gradient descent.
Adversarially Robust Learning via Entropic Regularization
Aug 27, 2020

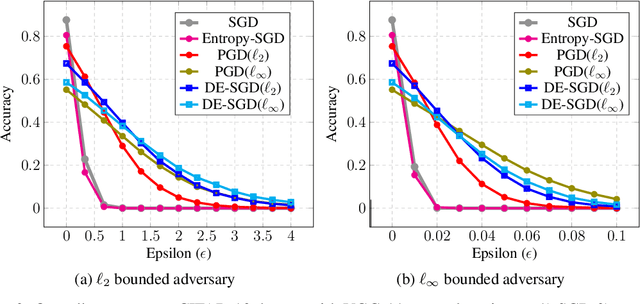
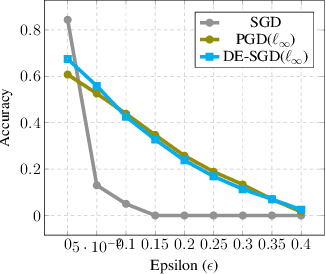
In this paper we propose a new family of algorithms for training adversarially robust deep neural networks. We formulate a new loss function that uses an entropic regularization. Our loss function considers the contribution of adversarial samples which are drawn from a specially designed distribution that assigns high probability to points with high loss from the immediate neighborhood of training samples. Our data entropy guided SGD approach is designed to search for adversarially robust valleys of the loss landscape. We observe that our approach generalizes better in terms of classification accuracy robustness as compared to state of art approaches based on projected gradient descent.
Algorithmic Guarantees for Inverse Imaging with Untrained Network Priors
Jun 20, 2019
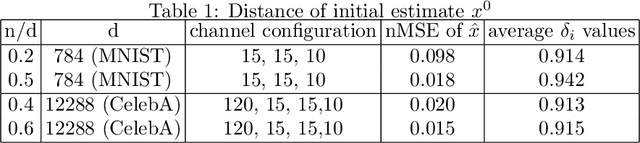

Deep neural networks as image priors have been recently introduced for problems such as denoising, super-resolution and inpainting with promising performance gains over hand-crafted image priors such as sparsity and low-rank. Unlike learned generative priors they do not require any training over large datasets. However, few theoretical guarantees exist in the scope of using untrained network priors for inverse imaging problems. We explore new applications and theory for untrained network priors. Specifically, we consider the problem of solving linear inverse problems, such as compressive sensing, as well as non-linear problems, such as compressive phase retrieval. We model images to lie in the range of an untrained deep generative network with a fixed seed. We further present a projected gradient descent scheme that can be used for both compressive sensing and phase retrieval and provide rigorous theoretical guarantees for its convergence. We also show both theoretically as well as empirically that with deep network priors, one can achieve better compression rates for the same image quality compared to hand crafted priors.
Learning ReLU Networks via Alternating Minimization
Oct 10, 2018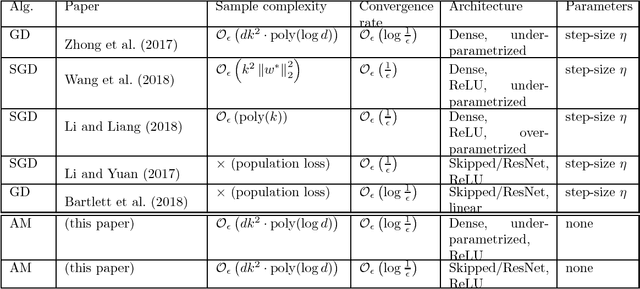
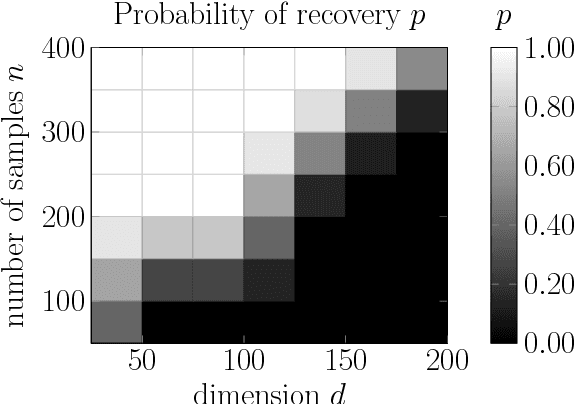
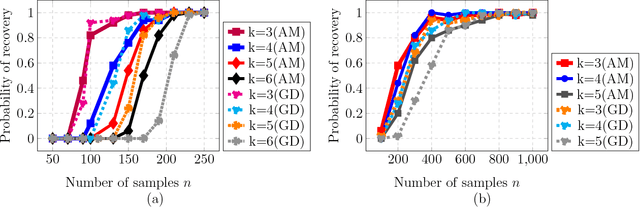
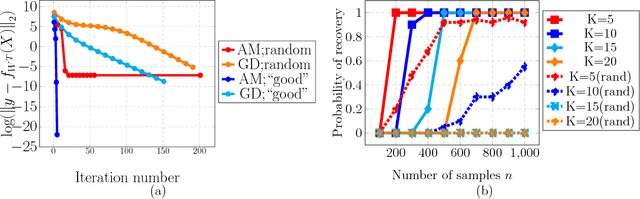
We propose and analyze a new family of algorithms for training neural networks with ReLU activations. Our algorithms are based on the technique of alternating minimization: estimating the activation patterns of each ReLU for all given samples, interleaved with weight updates via a least-squares step. The main focus of our paper are 1-hidden layer networks with $k$ hidden neurons and ReLU activation. We show that under standard distributional assumptions on the $d-$dimensional input data, our algorithm provably recovers the true `ground truth' parameters in a linearly convergent fashion. This holds as long as the weights are sufficiently well initialized; furthermore, our method requires only $n=\widetilde{O}(dk^2)$ samples. We also analyze the special case of 1-hidden layer networks with skipped connections, commonly used in ResNet-type architectures, and propose a novel initialization strategy for the same. For ReLU based ResNet type networks, we provide the first linear convergence guarantee with an end-to-end algorithm. We also extend this framework to deeper networks and empirically demonstrate its convergence to a global minimum.
Sample-Efficient Algorithms for Recovering Structured Signals from Magnitude-Only Measurements
Nov 26, 2017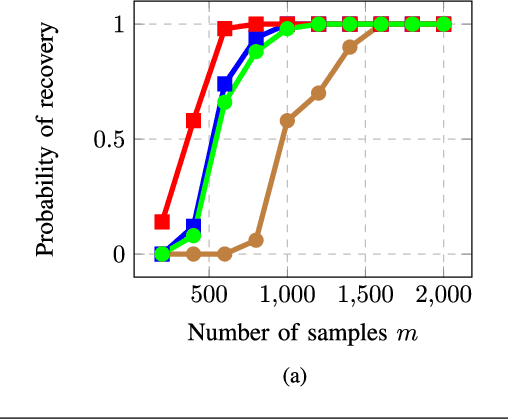
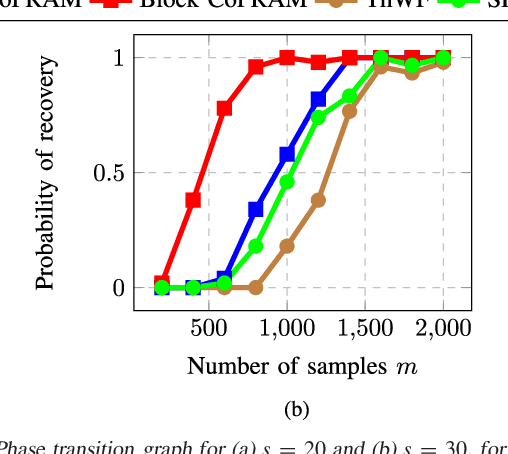
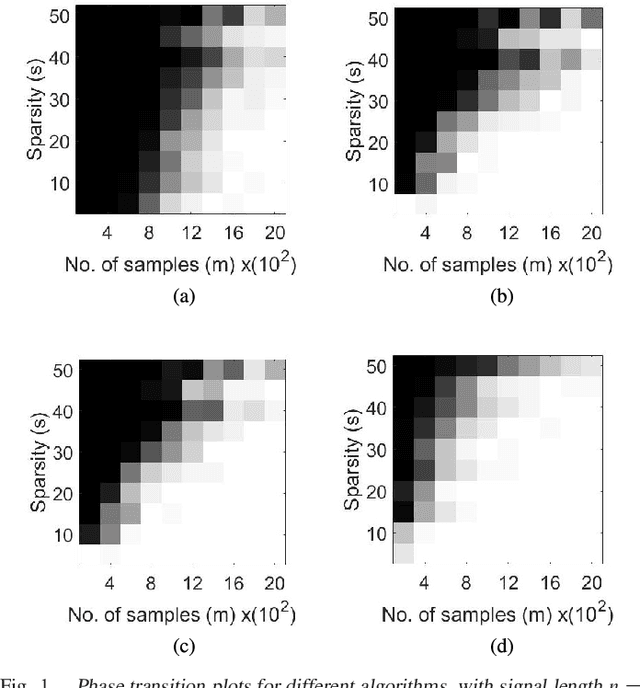
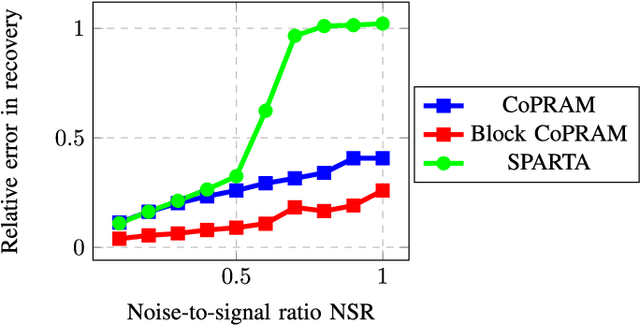
We consider the problem of recovering a signal $\mathbf{x}^* \in \mathbf{R}^n$, from magnitude-only measurements $y_i = |\left\langle\mathbf{a}_i,\mathbf{x}^*\right\rangle|$ for $i=[m]$. Also called the phase retrieval, this is a fundamental challenge in bio-,astronomical imaging and speech processing. The problem above is ill-posed; additional assumptions on the signal and/or the measurements are necessary. In this paper we first study the case where the signal $\mathbf{x}^*$ is $s$-sparse. We develop a novel algorithm that we call Compressive Phase Retrieval with Alternating Minimization, or CoPRAM. Our algorithm is simple; it combines the classical alternating minimization approach for phase retrieval with the CoSaMP algorithm for sparse recovery. Despite its simplicity, we prove that CoPRAM achieves a sample complexity of $O(s^2\log n)$ with Gaussian measurements $\mathbf{a}_i$, matching the best known existing results; moreover, it demonstrates linear convergence in theory and practice. Additionally, it requires no extra tuning parameters other than signal sparsity $s$ and is robust to noise. When the sorted coefficients of the sparse signal exhibit a power law decay, we show that CoPRAM achieves a sample complexity of $O(s\log n)$, which is close to the information-theoretic limit. We also consider the case where the signal $\mathbf{x}^*$ arises from structured sparsity models. We specifically examine the case of block-sparse signals with uniform block size of $b$ and block sparsity $k=s/b$. For this problem, we design a recovery algorithm Block CoPRAM that further reduces the sample complexity to $O(ks\log n)$. For sufficiently large block lengths of $b=\Theta(s)$, this bound equates to $O(s\log n)$. To our knowledge, this constitutes the first end-to-end algorithm for phase retrieval where the Gaussian sample complexity has a sub-quadratic dependence on the signal sparsity level.