Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Token Attacks on Vision Transformers
Paper and Code

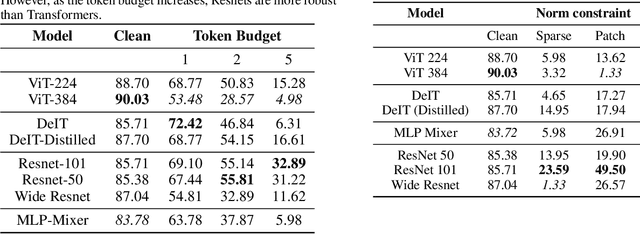
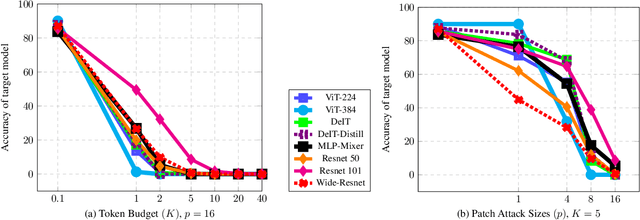

Vision transformers rely on a patch token based self attention mechanism, in contrast to convolutional networks. We investigate fundamental differences between these two families of models, by designing a block sparsity based adversarial token attack. We probe and analyze transformer as well as convolutional models with token attacks of varying patch sizes. We infer that transformer models are more sensitive to token attacks than convolutional models, with ResNets outperforming Transformer models by up to $\sim30\%$ in robust accuracy for single token attacks.
View paper on