 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning ReLU Networks via Alternating Minimization
Paper and Code
Oct 10, 2018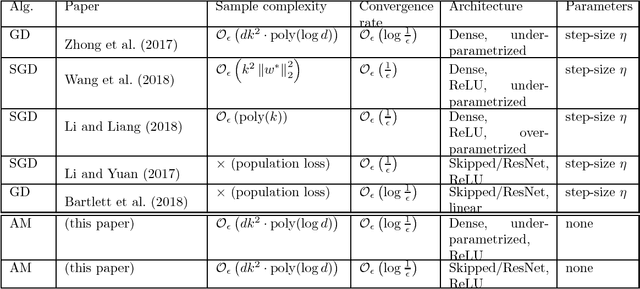
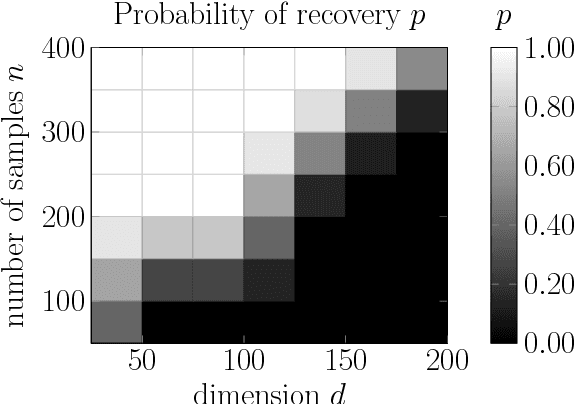
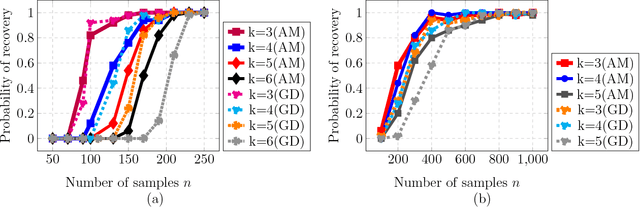
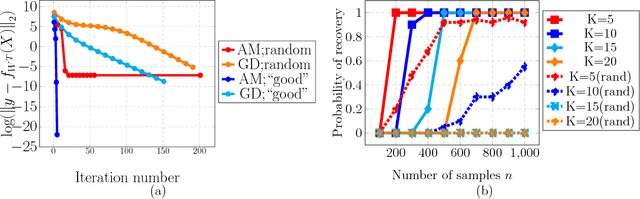
We propose and analyze a new family of algorithms for training neural networks with ReLU activations. Our algorithms are based on the technique of alternating minimization: estimating the activation patterns of each ReLU for all given samples, interleaved with weight updates via a least-squares step. The main focus of our paper are 1-hidden layer networks with $k$ hidden neurons and ReLU activation. We show that under standard distributional assumptions on the $d-$dimensional input data, our algorithm provably recovers the true `ground truth' parameters in a linearly convergent fashion. This holds as long as the weights are sufficiently well initialized; furthermore, our method requires only $n=\widetilde{O}(dk^2)$ samples. We also analyze the special case of 1-hidden layer networks with skipped connections, commonly used in ResNet-type architectures, and propose a novel initialization strategy for the same. For ReLU based ResNet type networks, we provide the first linear convergence guarantee with an end-to-end algorithm. We also extend this framework to deeper networks and empirically demonstrate its convergence to a global minimum.