 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASCENT: Amplifying Power Side-Channel Resilience via Learning & Monte-Carlo Tree Search
Jun 27, 2024



Power side-channel (PSC) analysis is pivotal for securing cryptographic hardware. Prior art focused on securing gate-level netlists obtained as-is from chip design automation, neglecting all the complexities and potential side-effects for security arising from the design automation process. That is, automation traditionally prioritizes power, performance, and area (PPA), sidelining security. We propose a "security-first" approach, refining the logic synthesis stage to enhance the overall resilience of PSC countermeasures. We introduce ASCENT, a learning-and-search-based framework that (i) drastically reduces the time for post-design PSC evaluation and (ii) explores the security-vs-PPA design space. Thus, ASCENT enables an efficient exploration of a large number of candidate netlists, leading to an improvement in PSC resilience compared to regular PPA-optimized netlists. ASCENT is up to 120x faster than traditional PSC analysis and yields a 3.11x improvement for PSC resilience of state-of-the-art PSC countermeasures
Make Every Move Count: LLM-based High-Quality RTL Code Generation Using MCTS
Feb 05, 2024Existing large language models (LLMs) for register transfer level code generation face challenges like compilation failures and suboptimal power, performance, and area (PPA) efficiency. This is due to the lack of PPA awareness in conventional transformer decoding algorithms. In response, we present an automated transformer decoding algorithm that integrates Monte Carlo tree-search for lookahead, guiding the transformer to produce compilable, functionally correct, and PPA-optimized code. Empirical evaluation with a fine-tuned language model on RTL codesets shows that our proposed technique consistently generates functionally correct code compared to prompting-only methods and effectively addresses the PPA-unawareness drawback of naive large language models. For the largest design generated by the state-of-the-art LLM (16-bit adder), our technique can achieve a 31.8% improvement in the area-delay product.
Retrieval-Guided Reinforcement Learning for Boolean Circuit Minimization
Jan 22, 2024Logic synthesis, a pivotal stage in chip design, entails optimizing chip specifications encoded in hardware description languages like Verilog into highly efficient implementations using Boolean logic gates. The process involves a sequential application of logic minimization heuristics (``synthesis recipe"), with their arrangement significantly impacting crucial metrics such as area and delay. Addressing the challenge posed by the broad spectrum of design complexities - from variations of past designs (e.g., adders and multipliers) to entirely novel configurations (e.g., innovative processor instructions) - requires a nuanced `synthesis recipe` guided by human expertise and intuition. This study conducts a thorough examination of learning and search techniques for logic synthesis, unearthing a surprising revelation: pre-trained agents, when confronted with entirely novel designs, may veer off course, detrimentally affecting the search trajectory. We present ABC-RL, a meticulously tuned $\alpha$ parameter that adeptly adjusts recommendations from pre-trained agents during the search process. Computed based on similarity scores through nearest neighbor retrieval from the training dataset, ABC-RL yields superior synthesis recipes tailored for a wide array of hardware designs. Our findings showcase substantial enhancements in the Quality-of-result (QoR) of synthesized circuits, boasting improvements of up to 24.8% compared to state-of-the-art techniques. Furthermore, ABC-RL achieves an impressive up to 9x reduction in runtime (iso-QoR) when compared to current state-of-the-art methodologies.
Towards the Imagenets of ML4EDA
Oct 16, 2023Despite the growing interest in ML-guided EDA tools from RTL to GDSII, there are no standard datasets or prototypical learning tasks defined for the EDA problem domain. Experience from the computer vision community suggests that such datasets are crucial to spur further progress in ML for EDA. Here we describe our experience curating two large-scale, high-quality datasets for Verilog code generation and logic synthesis. The first, VeriGen, is a dataset of Verilog code collected from GitHub and Verilog textbooks. The second, OpenABC-D, is a large-scale, labeled dataset designed to aid ML for logic synthesis tasks. The dataset consists of 870,000 And-Inverter-Graphs (AIGs) produced from 1500 synthesis runs on a large number of open-source hardware projects. In this paper we will discuss challenges in curating, maintaining and growing the size and scale of these datasets. We will also touch upon questions of dataset quality and security, and the use of novel data augmentation tools that are tailored for the hardware domain.
* Invited paper, ICCAD 2023
INVICTUS: Optimizing Boolean Logic Circuit Synthesis via Synergistic Learning and Search
May 25, 2023


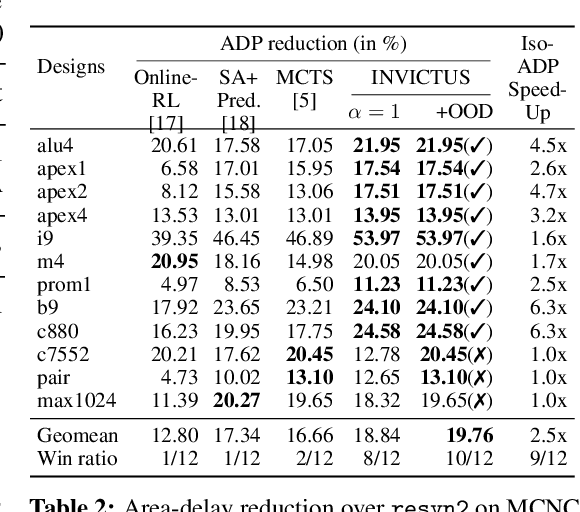
Logic synthesis is the first and most vital step in chip design. This steps converts a chip specification written in a hardware description language (such as Verilog) into an optimized implementation using Boolean logic gates. State-of-the-art logic synthesis algorithms have a large number of logic minimization heuristics, typically applied sequentially based on human experience and intuition. The choice of the order greatly impacts the quality (e.g., area and delay) of the synthesized circuit. In this paper, we propose INVICTUS, a model-based offline reinforcement learning (RL) solution that automatically generates a sequence of logic minimization heuristics ("synthesis recipe") based on a training dataset of previously seen designs. A key challenge is that new designs can range from being very similar to past designs (e.g., adders and multipliers) to being completely novel (e.g., new processor instructions). %Compared to prior work, INVICTUS is the first solution that uses a mix of RL and search methods joint with an online out-of-distribution detector to generate synthesis recipes over a wide range of benchmarks. Our results demonstrate significant improvement in area-delay product (ADP) of synthesized circuits with up to 30\% improvement over state-of-the-art techniques. Moreover, INVICTUS achieves up to $6.3\times$ runtime reduction (iso-ADP) compared to the state-of-the-art.
ALMOST: Adversarial Learning to Mitigate Oracle-less ML Attacks via Synthesis Tuning
Mar 06, 2023



Oracle-less machine learning (ML) attacks have broken various logic locking schemes. Regular synthesis, which is tailored for area-power-delay optimization, yields netlists where key-gate localities are vulnerable to learning. Thus, we call for security-aware logic synthesis. We propose ALMOST, a framework for adversarial learning to mitigate oracle-less ML attacks via synthesis tuning. ALMOST uses a simulated-annealing-based synthesis recipe generator, employing adversarially trained models that can predict state-of-the-art attacks' accuracies over wide ranges of recipes and key-gate localities. Experiments on ISCAS benchmarks confirm the attacks' accuracies drops to around 50\% for ALMOST-synthesized circuits, all while not undermining design optimization.
Too Big to Fail? Active Few-Shot Learning Guided Logic Synthesis
Apr 05, 2022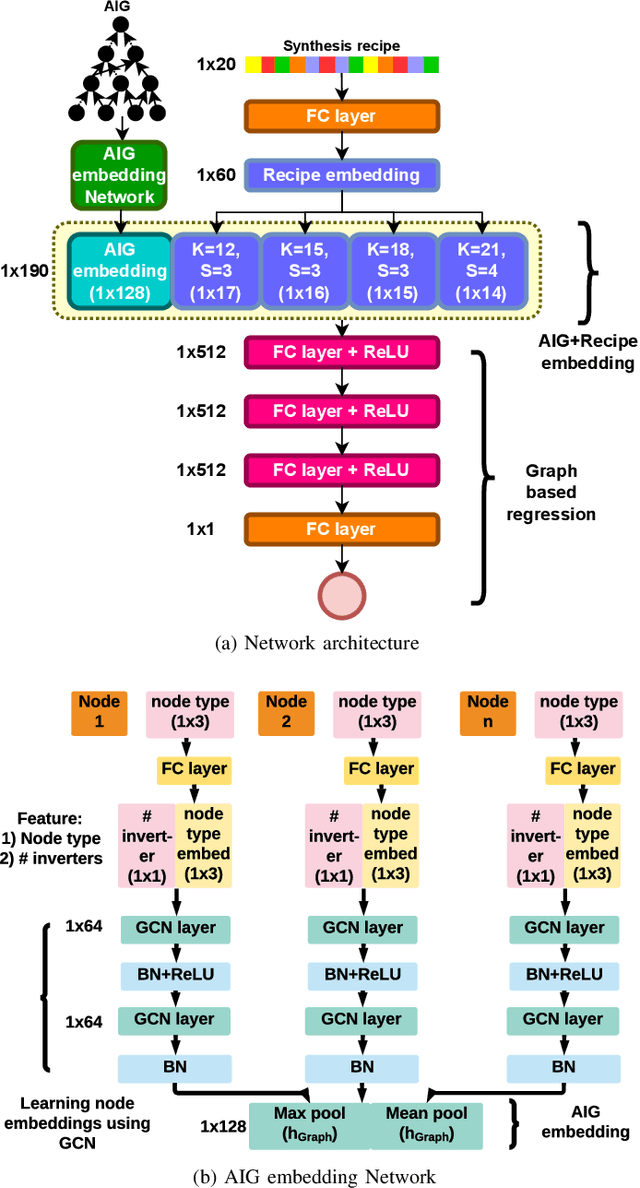
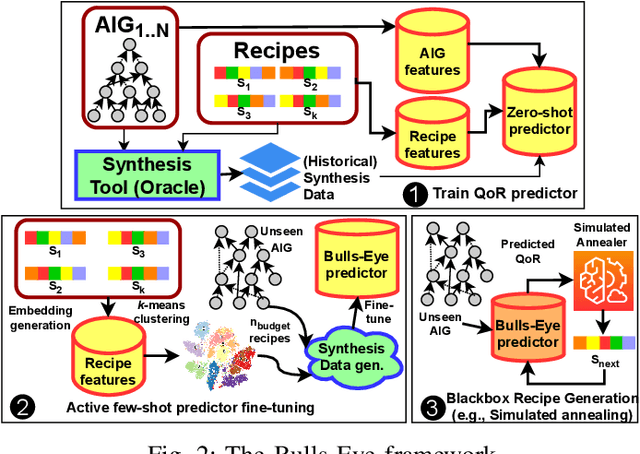
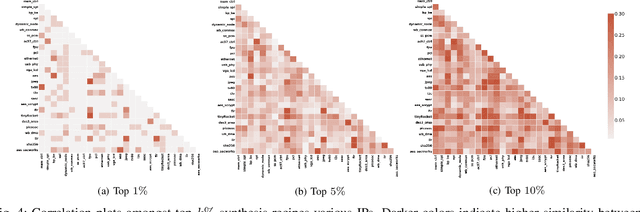
Generating sub-optimal synthesis transformation sequences ("synthesis recipe") is an important problem in logic synthesis. Manually crafted synthesis recipes have poor quality. State-of-the art machine learning (ML) works to generate synthesis recipes do not scale to large netlists as the models need to be trained from scratch, for which training data is collected using time consuming synthesis runs. We propose a new approach, Bulls-Eye, that fine-tunes a pre-trained model on past synthesis data to accurately predict the quality of a synthesis recipe for an unseen netlist. This approach on achieves 2x-10x run-time improvement and better quality-of-result (QoR) than state-of-the-art machine learning approaches.
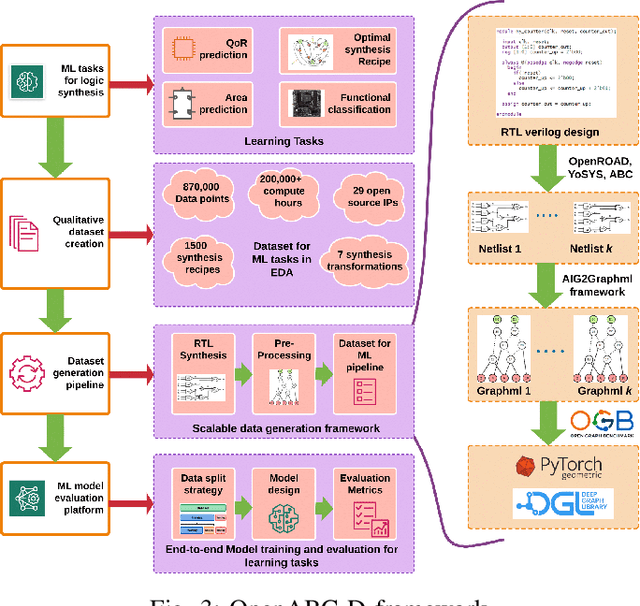
OpenABC-D: A Large-Scale Dataset For Machine Learning Guided Integrated Circuit Synthesis
Oct 21, 2021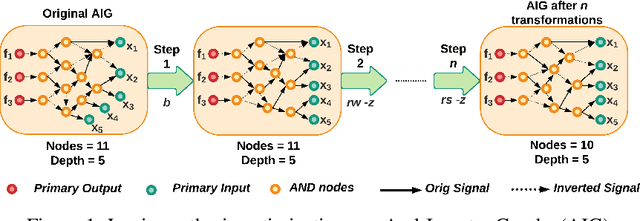
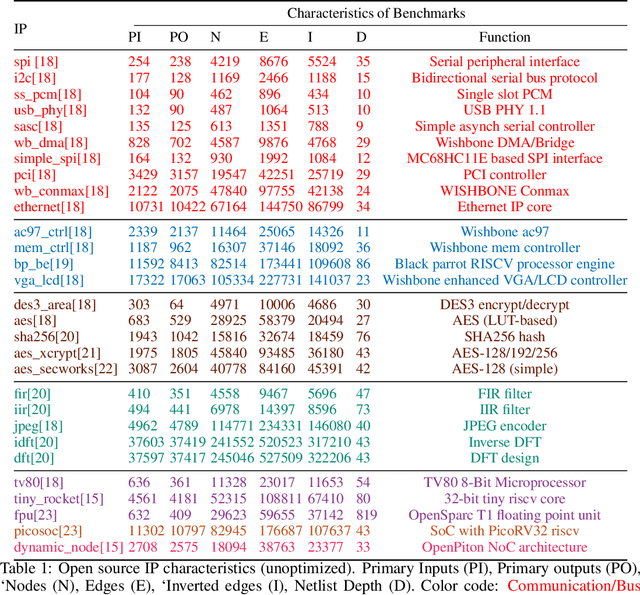
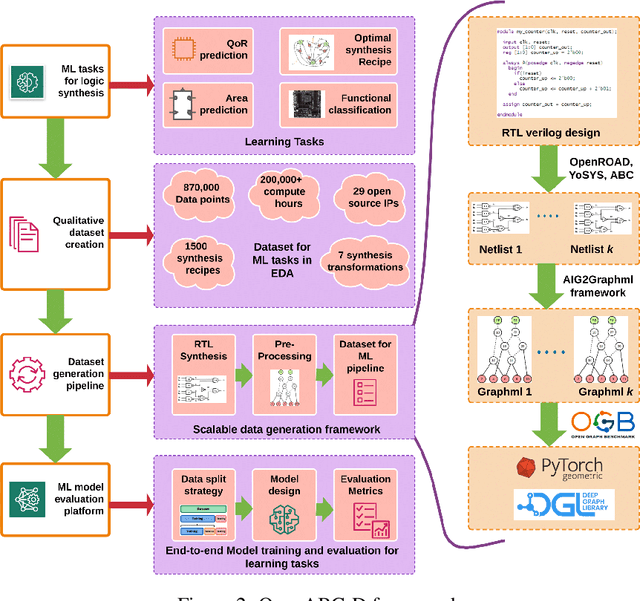

Logic synthesis is a challenging and widely-researched combinatorial optimization problem during integrated circuit (IC) design. It transforms a high-level description of hardware in a programming language like Verilog into an optimized digital circuit netlist, a network of interconnected Boolean logic gates, that implements the function. Spurred by the success of ML in solving combinatorial and graph problems in other domains, there is growing interest in the design of ML-guided logic synthesis tools. Yet, there are no standard datasets or prototypical learning tasks defined for this problem domain. Here, we describe OpenABC-D,a large-scale, labeled dataset produced by synthesizing open source designs with a leading open-source logic synthesis tool and illustrate its use in developing, evaluating and benchmarking ML-guided logic synthesis. OpenABC-D has intermediate and final outputs in the form of 870,000 And-Inverter-Graphs (AIGs) produced from 1500 synthesis runs plus labels such as the optimized node counts, and de-lay. We define a generic learning problem on this dataset and benchmark existing solutions for it. The codes related to dataset creation and benchmark models are available athttps://github.com/NYU-MLDA/OpenABC.git. The dataset generated is available athttps://archive.nyu.edu/handle/2451/63311
Adversarially Robust Learning via Entropic Regularization
Aug 27, 2020

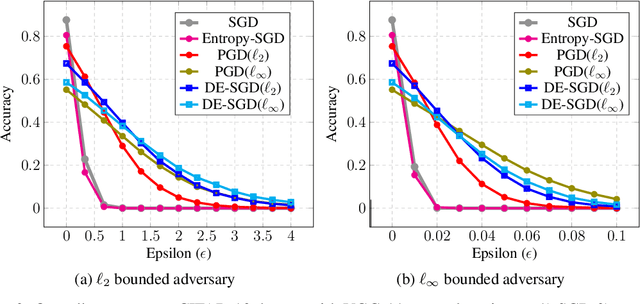
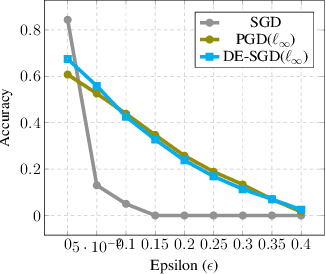
In this paper we propose a new family of algorithms for training adversarially robust deep neural networks. We formulate a new loss function that uses an entropic regularization. Our loss function considers the contribution of adversarial samples which are drawn from a specially designed distribution that assigns high probability to points with high loss from the immediate neighborhood of training samples. Our data entropy guided SGD approach is designed to search for adversarially robust valleys of the loss landscape. We observe that our approach generalizes better in terms of classification accuracy robustness as compared to state of art approaches based on projected gradient descent.