 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJBFuzz: Jailbreaking LLMs Efficiently and Effectively Using Fuzzing
Mar 12, 2025



Large language models (LLMs) have shown great promise as language understanding and decision making tools, and they have permeated various aspects of our everyday life. However, their widespread availability also comes with novel risks, such as generating harmful, unethical, or offensive content, via an attack called jailbreaking. Despite extensive efforts from LLM developers to align LLMs using human feedback, they are still susceptible to jailbreak attacks. To tackle this issue, researchers often employ red-teaming to understand and investigate jailbreak prompts. However, existing red-teaming approaches lack effectiveness, scalability, or both. To address these issues, we propose JBFuzz, a novel effective, automated, and scalable red-teaming technique for jailbreaking LLMs. JBFuzz is inspired by the success of fuzzing for detecting bugs/vulnerabilities in software. We overcome three challenges related to effectiveness and scalability by devising novel seed prompts, a lightweight mutation engine, and a lightweight and accurate evaluator for guiding the fuzzer. Assimilating all three solutions results in a potent fuzzer that only requires black-box access to the target LLM. We perform extensive experimental evaluation of JBFuzz using nine popular and widely-used LLMs. We find that JBFuzz successfully jailbreaks all LLMs for various harmful/unethical questions, with an average attack success rate of 99%. We also find that JBFuzz is extremely efficient as it jailbreaks a given LLM for a given question in 60 seconds on average. Our work highlights the susceptibility of the state-of-the-art LLMs to jailbreak attacks even after safety alignment, and serves as a valuable red-teaming tool for LLM developers.
LLMPirate: LLMs for Black-box Hardware IP Piracy
Nov 25, 2024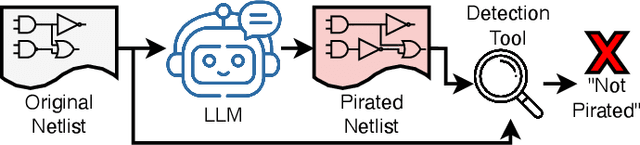



The rapid advancement of large language models (LLMs) has enabled the ability to effectively analyze and generate code nearly instantaneously, resulting in their widespread adoption in software development. Following this advancement, researchers and companies have begun integrating LLMs across the hardware design and verification process. However, these highly potent LLMs can also induce new attack scenarios upon security vulnerabilities across the hardware development process. One such attack vector that has not been explored is intellectual property (IP) piracy. Given that this attack can manifest as rewriting hardware designs to evade piracy detection, it is essential to thoroughly evaluate LLM capabilities in performing this task and assess the mitigation abilities of current IP piracy detection tools. Therefore, in this work, we propose LLMPirate, the first LLM-based technique able to generate pirated variations of circuit designs that successfully evade detection across multiple state-of-the-art piracy detection tools. We devise three solutions to overcome challenges related to integration of LLMs for hardware circuit designs, scalability to large circuits, and effectiveness, resulting in an end-to-end automated, efficient, and practical formulation. We perform an extensive experimental evaluation of LLMPirate using eight LLMs of varying sizes and capabilities and assess their performance in pirating various circuit designs against four state-of-the-art, widely-used piracy detection tools. Our experiments demonstrate that LLMPirate is able to consistently evade detection on 100% of tested circuits across every detection tool. Additionally, we showcase the ramifications of LLMPirate using case studies on IBEX and MOR1KX processors and a GPS module, that we successfully pirate. We envision that our work motivates and fosters the development of better IP piracy detection tools.
CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation
Apr 12, 2024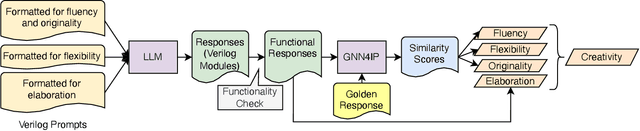
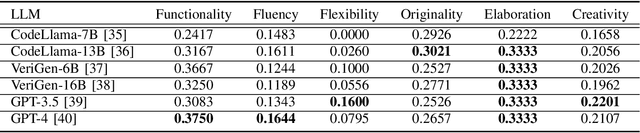
Large Language Models (LLMs) have proved effective and efficient in generating code, leading to their utilization within the hardware design process. Prior works evaluating LLMs' abilities for register transfer level code generation solely focus on functional correctness. However, the creativity associated with these LLMs, or the ability to generate novel and unique solutions, is a metric not as well understood, in part due to the challenge of quantifying this quality. To address this research gap, we present CreativeEval, a framework for evaluating the creativity of LLMs within the context of generating hardware designs. We quantify four creative sub-components, fluency, flexibility, originality, and elaboration, through various prompting and post-processing techniques. We then evaluate multiple popular LLMs (including GPT models, CodeLlama, and VeriGen) upon this creativity metric, with results indicating GPT-3.5 as the most creative model in generating hardware designs.
AttackGNN: Red-Teaming GNNs in Hardware Security Using Reinforcement Learning
Feb 26, 2024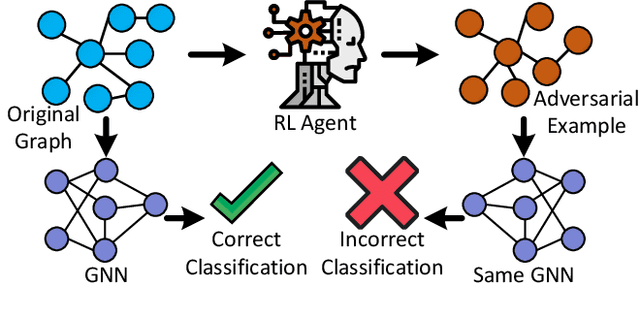

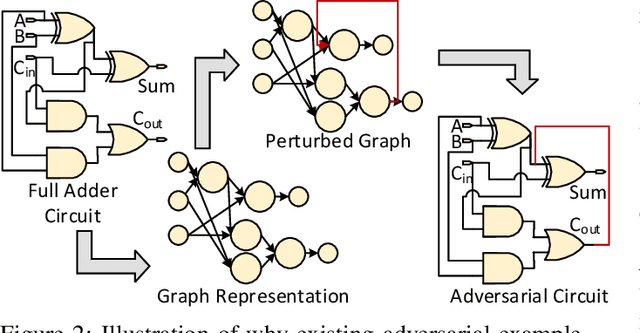
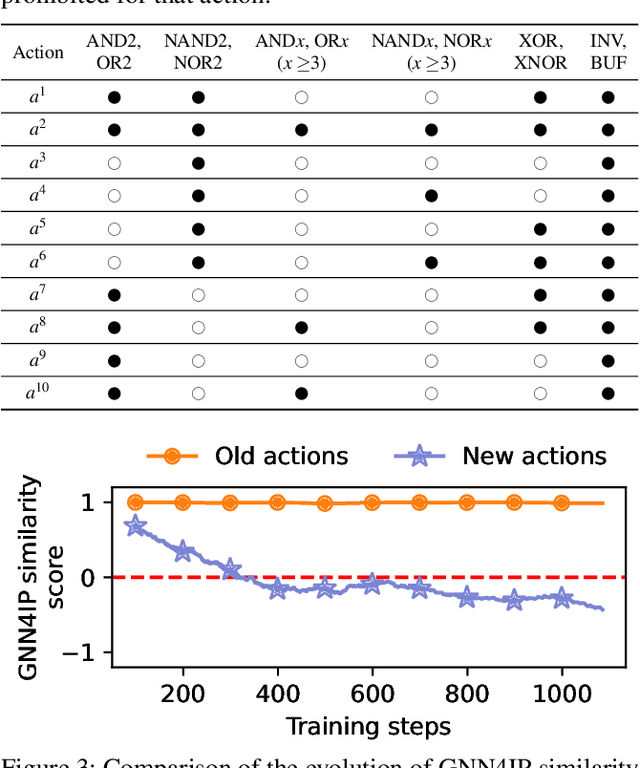
Machine learning has shown great promise in addressing several critical hardware security problems. In particular, researchers have developed novel graph neural network (GNN)-based techniques for detecting intellectual property (IP) piracy, detecting hardware Trojans (HTs), and reverse engineering circuits, to name a few. These techniques have demonstrated outstanding accuracy and have received much attention in the community. However, since these techniques are used for security applications, it is imperative to evaluate them thoroughly and ensure they are robust and do not compromise the security of integrated circuits. In this work, we propose AttackGNN, the first red-team attack on GNN-based techniques in hardware security. To this end, we devise a novel reinforcement learning (RL) agent that generates adversarial examples, i.e., circuits, against the GNN-based techniques. We overcome three challenges related to effectiveness, scalability, and generality to devise a potent RL agent. We target five GNN-based techniques for four crucial classes of problems in hardware security: IP piracy, detecting/localizing HTs, reverse engineering, and hardware obfuscation. Through our approach, we craft circuits that fool all GNNs considered in this work. For instance, to evade IP piracy detection, we generate adversarial pirated circuits that fool the GNN-based defense into classifying our crafted circuits as not pirated. For attacking HT localization GNN, our attack generates HT-infested circuits that fool the defense on all tested circuits. We obtain a similar 100% success rate against GNNs for all classes of problems.
Make Every Move Count: LLM-based High-Quality RTL Code Generation Using MCTS
Feb 05, 2024Existing large language models (LLMs) for register transfer level code generation face challenges like compilation failures and suboptimal power, performance, and area (PPA) efficiency. This is due to the lack of PPA awareness in conventional transformer decoding algorithms. In response, we present an automated transformer decoding algorithm that integrates Monte Carlo tree-search for lookahead, guiding the transformer to produce compilable, functionally correct, and PPA-optimized code. Empirical evaluation with a fine-tuned language model on RTL codesets shows that our proposed technique consistently generates functionally correct code compared to prompting-only methods and effectively addresses the PPA-unawareness drawback of naive large language models. For the largest design generated by the state-of-the-art LLM (16-bit adder), our technique can achieve a 31.8% improvement in the area-delay product.
Reinforcement Learning for Hardware Security: Opportunities, Developments, and Challenges
Aug 29, 2022Reinforcement learning (RL) is a machine learning paradigm where an autonomous agent learns to make an optimal sequence of decisions by interacting with the underlying environment. The promise demonstrated by RL-guided workflows in unraveling electronic design automation problems has encouraged hardware security researchers to utilize autonomous RL agents in solving domain-specific problems. From the perspective of hardware security, such autonomous agents are appealing as they can generate optimal actions in an unknown adversarial environment. On the other hand, the continued globalization of the integrated circuit supply chain has forced chip fabrication to off-shore, untrustworthy entities, leading to increased concerns about the security of the hardware. Furthermore, the unknown adversarial environment and increasing design complexity make it challenging for defenders to detect subtle modifications made by attackers (a.k.a. hardware Trojans). In this brief, we outline the development of RL agents in detecting hardware Trojans, one of the most challenging hardware security problems. Additionally, we outline potential opportunities and enlist the challenges of applying RL to solve hardware security problems.
ATTRITION: Attacking Static Hardware Trojan Detection Techniques Using Reinforcement Learning
Aug 26, 2022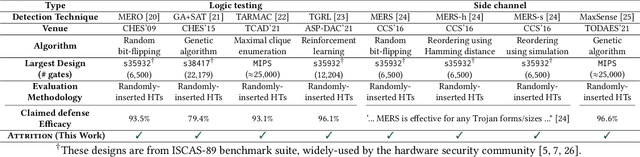
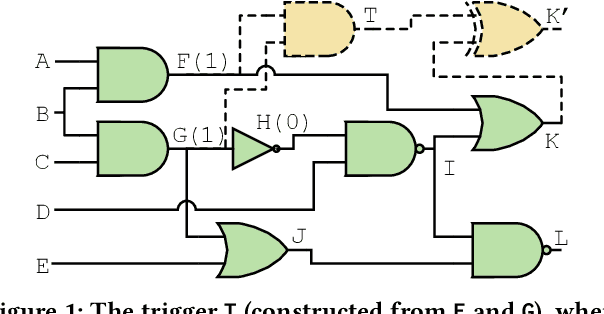
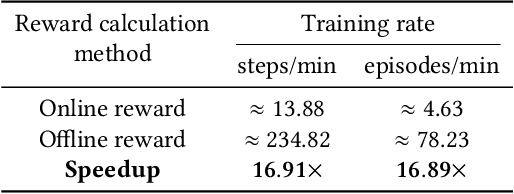
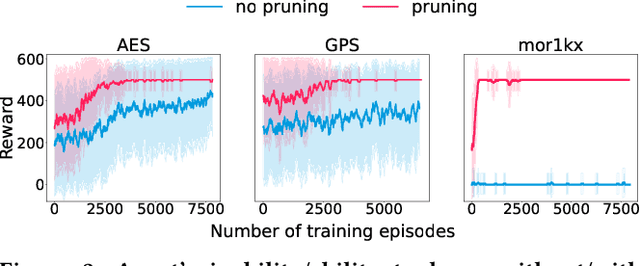
Stealthy hardware Trojans (HTs) inserted during the fabrication of integrated circuits can bypass the security of critical infrastructures. Although researchers have proposed many techniques to detect HTs, several limitations exist, including: (i) a low success rate, (ii) high algorithmic complexity, and (iii) a large number of test patterns. Furthermore, the most pertinent drawback of prior detection techniques stems from an incorrect evaluation methodology, i.e., they assume that an adversary inserts HTs randomly. Such inappropriate adversarial assumptions enable detection techniques to claim high HT detection accuracy, leading to a "false sense of security." Unfortunately, to the best of our knowledge, despite more than a decade of research on detecting HTs inserted during fabrication, there have been no concerted efforts to perform a systematic evaluation of HT detection techniques. In this paper, we play the role of a realistic adversary and question the efficacy of HT detection techniques by developing an automated, scalable, and practical attack framework, ATTRITION, using reinforcement learning (RL). ATTRITION evades eight detection techniques across two HT detection categories, showcasing its agnostic behavior. ATTRITION achieves average attack success rates of $47\times$ and $211\times$ compared to randomly inserted HTs against state-of-the-art HT detection techniques. We demonstrate ATTRITION's ability to evade detection techniques by evaluating designs ranging from the widely-used academic suites to larger designs such as the open-source MIPS and mor1kx processors to AES and a GPS module. Additionally, we showcase the impact of ATTRITION-generated HTs through two case studies (privilege escalation and kill switch) on the mor1kx processor. We envision that our work, along with our released HT benchmarks and models, fosters the development of better HT detection techniques.
DETERRENT: Detecting Trojans using Reinforcement Learning
Aug 26, 2022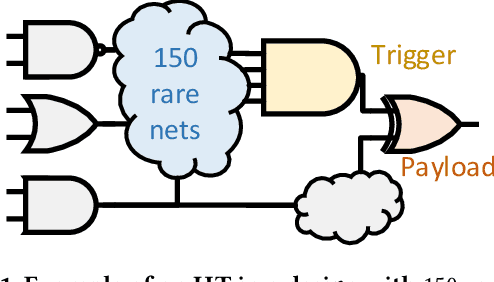
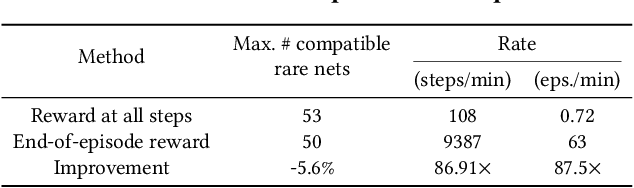
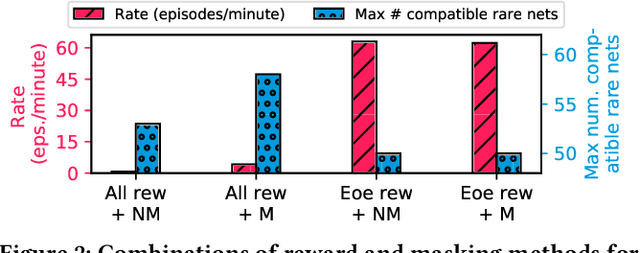
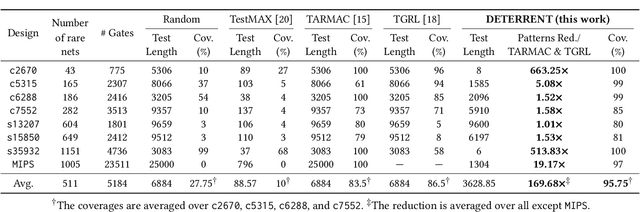
Insertion of hardware Trojans (HTs) in integrated circuits is a pernicious threat. Since HTs are activated under rare trigger conditions, detecting them using random logic simulations is infeasible. In this work, we design a reinforcement learning (RL) agent that circumvents the exponential search space and returns a minimal set of patterns that is most likely to detect HTs. Experimental results on a variety of benchmarks demonstrate the efficacy and scalability of our RL agent, which obtains a significant reduction ($169\times$) in the number of test patterns required while maintaining or improving coverage ($95.75\%$) compared to the state-of-the-art techniques.