 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttackGNN: Red-Teaming GNNs in Hardware Security Using Reinforcement Learning
Feb 26, 2024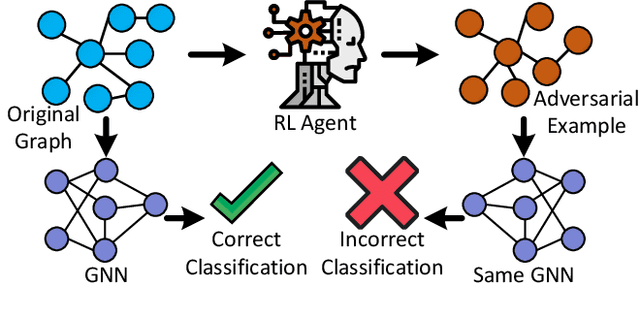

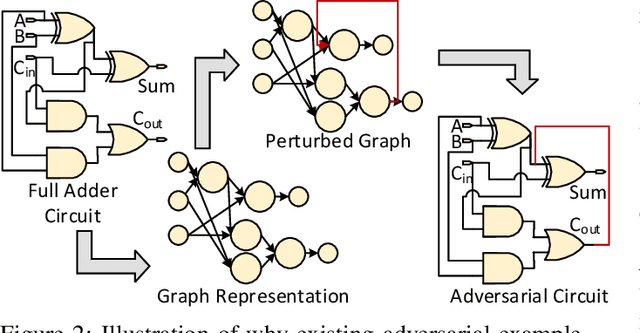
Machine learning has shown great promise in addressing several critical hardware security problems. In particular, researchers have developed novel graph neural network (GNN)-based techniques for detecting intellectual property (IP) piracy, detecting hardware Trojans (HTs), and reverse engineering circuits, to name a few. These techniques have demonstrated outstanding accuracy and have received much attention in the community. However, since these techniques are used for security applications, it is imperative to evaluate them thoroughly and ensure they are robust and do not compromise the security of integrated circuits. In this work, we propose AttackGNN, the first red-team attack on GNN-based techniques in hardware security. To this end, we devise a novel reinforcement learning (RL) agent that generates adversarial examples, i.e., circuits, against the GNN-based techniques. We overcome three challenges related to effectiveness, scalability, and generality to devise a potent RL agent. We target five GNN-based techniques for four crucial classes of problems in hardware security: IP piracy, detecting/localizing HTs, reverse engineering, and hardware obfuscation. Through our approach, we craft circuits that fool all GNNs considered in this work. For instance, to evade IP piracy detection, we generate adversarial pirated circuits that fool the GNN-based defense into classifying our crafted circuits as not pirated. For attacking HT localization GNN, our attack generates HT-infested circuits that fool the defense on all tested circuits. We obtain a similar 100% success rate against GNNs for all classes of problems.
Reinforcement Learning for Hardware Security: Opportunities, Developments, and Challenges
Aug 29, 2022Reinforcement learning (RL) is a machine learning paradigm where an autonomous agent learns to make an optimal sequence of decisions by interacting with the underlying environment. The promise demonstrated by RL-guided workflows in unraveling electronic design automation problems has encouraged hardware security researchers to utilize autonomous RL agents in solving domain-specific problems. From the perspective of hardware security, such autonomous agents are appealing as they can generate optimal actions in an unknown adversarial environment. On the other hand, the continued globalization of the integrated circuit supply chain has forced chip fabrication to off-shore, untrustworthy entities, leading to increased concerns about the security of the hardware. Furthermore, the unknown adversarial environment and increasing design complexity make it challenging for defenders to detect subtle modifications made by attackers (a.k.a. hardware Trojans). In this brief, we outline the development of RL agents in detecting hardware Trojans, one of the most challenging hardware security problems. Additionally, we outline potential opportunities and enlist the challenges of applying RL to solve hardware security problems.
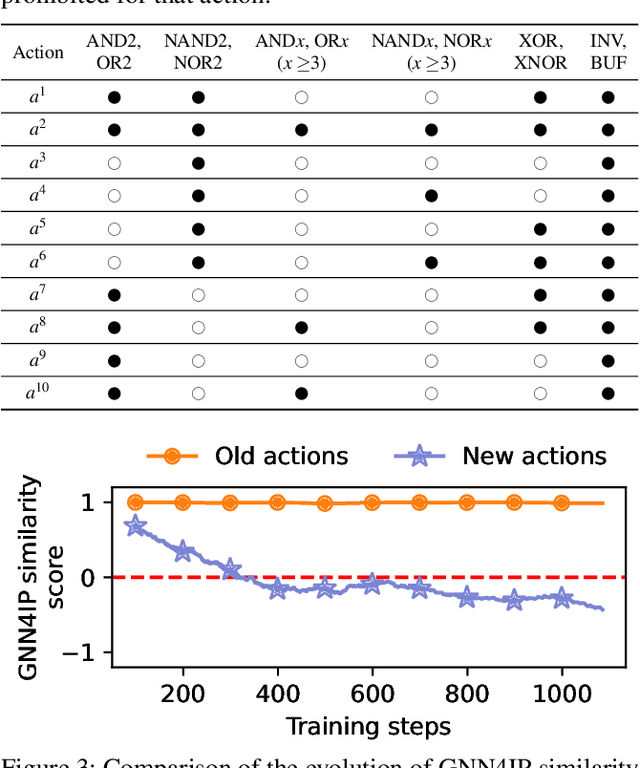
ATTRITION: Attacking Static Hardware Trojan Detection Techniques Using Reinforcement Learning
Aug 26, 2022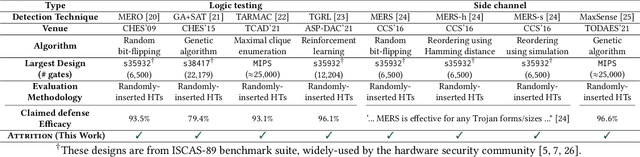
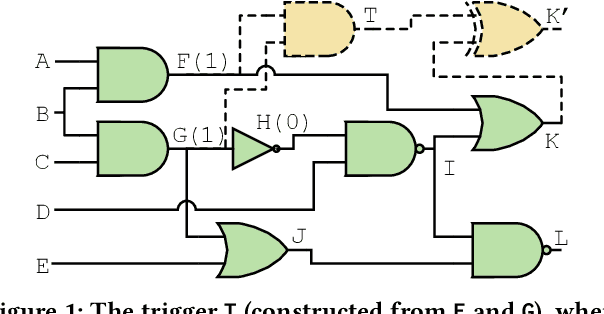
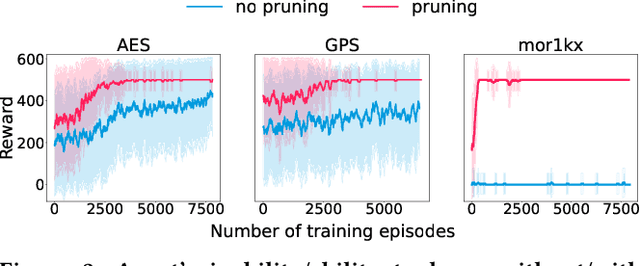
Stealthy hardware Trojans (HTs) inserted during the fabrication of integrated circuits can bypass the security of critical infrastructures. Although researchers have proposed many techniques to detect HTs, several limitations exist, including: (i) a low success rate, (ii) high algorithmic complexity, and (iii) a large number of test patterns. Furthermore, the most pertinent drawback of prior detection techniques stems from an incorrect evaluation methodology, i.e., they assume that an adversary inserts HTs randomly. Such inappropriate adversarial assumptions enable detection techniques to claim high HT detection accuracy, leading to a "false sense of security." Unfortunately, to the best of our knowledge, despite more than a decade of research on detecting HTs inserted during fabrication, there have been no concerted efforts to perform a systematic evaluation of HT detection techniques. In this paper, we play the role of a realistic adversary and question the efficacy of HT detection techniques by developing an automated, scalable, and practical attack framework, ATTRITION, using reinforcement learning (RL). ATTRITION evades eight detection techniques across two HT detection categories, showcasing its agnostic behavior. ATTRITION achieves average attack success rates of $47\times$ and $211\times$ compared to randomly inserted HTs against state-of-the-art HT detection techniques. We demonstrate ATTRITION's ability to evade detection techniques by evaluating designs ranging from the widely-used academic suites to larger designs such as the open-source MIPS and mor1kx processors to AES and a GPS module. Additionally, we showcase the impact of ATTRITION-generated HTs through two case studies (privilege escalation and kill switch) on the mor1kx processor. We envision that our work, along with our released HT benchmarks and models, fosters the development of better HT detection techniques.
DETERRENT: Detecting Trojans using Reinforcement Learning
Aug 26, 2022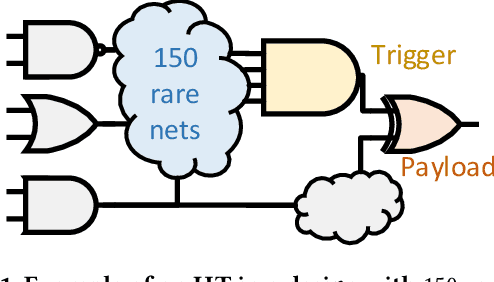
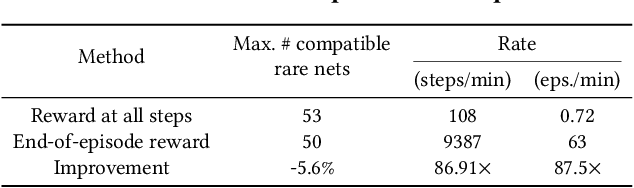
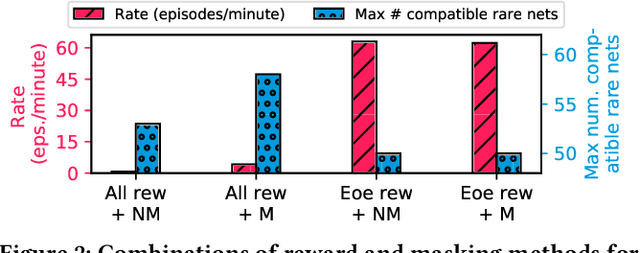
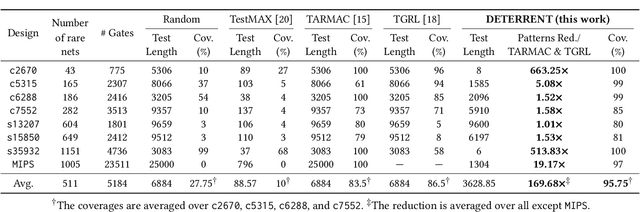
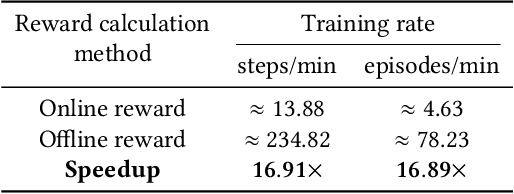
Insertion of hardware Trojans (HTs) in integrated circuits is a pernicious threat. Since HTs are activated under rare trigger conditions, detecting them using random logic simulations is infeasible. In this work, we design a reinforcement learning (RL) agent that circumvents the exponential search space and returns a minimal set of patterns that is most likely to detect HTs. Experimental results on a variety of benchmarks demonstrate the efficacy and scalability of our RL agent, which obtains a significant reduction ($169\times$) in the number of test patterns required while maintaining or improving coverage ($95.75\%$) compared to the state-of-the-art techniques.
Attacking Split Manufacturing from a Deep Learning Perspective
Jul 08, 2020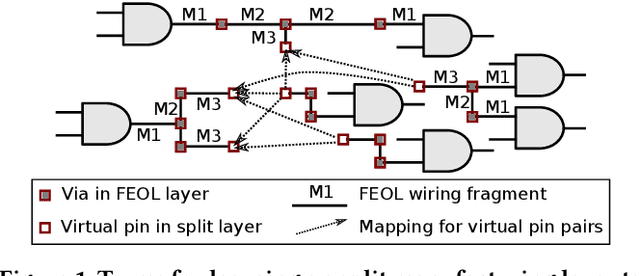

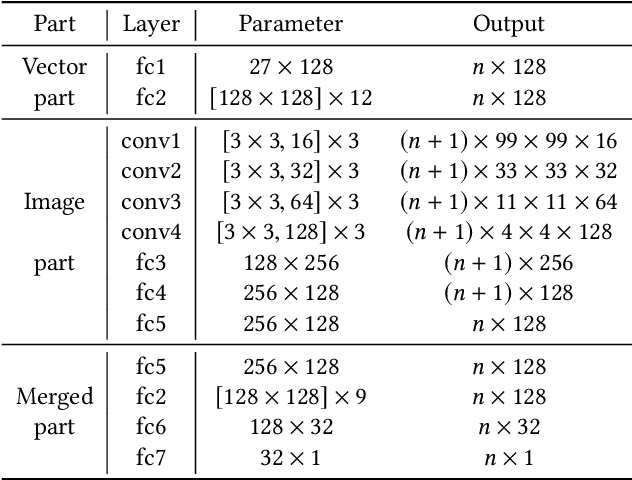
The notion of integrated circuit split manufacturing which delegates the front-end-of-line (FEOL) and back-end-of-line (BEOL) parts to different foundries, is to prevent overproduction, piracy of the intellectual property (IP), or targeted insertion of hardware Trojans by adversaries in the FEOL facility. In this work, we challenge the security promise of split manufacturing by formulating various layout-level placement and routing hints as vector- and image-based features. We construct a sophisticated deep neural network which can infer the missing BEOL connections with high accuracy. Compared with the publicly available network-flow attack [1], for the same set of ISCAS-85 benchmarks, we achieve 1.21X accuracy when splitting on M1 and 1.12X accuracy when splitting on M3 with less than 1% running time.