 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTroLLoc: Logic Locking and Layout Hardening for IC Security Closure against Hardware Trojans
May 09, 2024
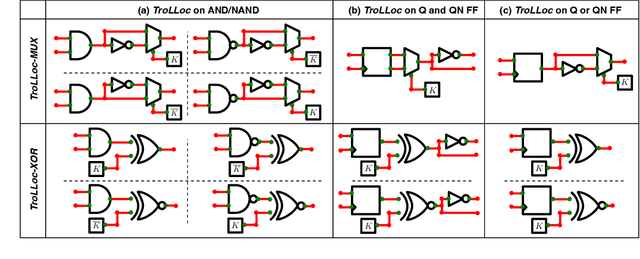


Due to cost benefits, supply chains of integrated circuits (ICs) are largely outsourced nowadays. However, passing ICs through various third-party providers gives rise to many security threats, like piracy of IC intellectual property or insertion of hardware Trojans, i.e., malicious circuit modifications. In this work, we proactively and systematically protect the physical layouts of ICs against post-design insertion of Trojans. Toward that end, we propose TroLLoc, a novel scheme for IC security closure that employs, for the first time, logic locking and layout hardening in unison. TroLLoc is fully integrated into a commercial-grade design flow, and TroLLoc is shown to be effective, efficient, and robust. Our work provides in-depth layout and security analysis considering the challenging benchmarks of the ISPD'22/23 contests for security closure. We show that TroLLoc successfully renders layouts resilient, with reasonable overheads, against (i) general prospects for Trojan insertion as in the ISPD'22 contest, (ii) actual Trojan insertion as in the ISPD'23 contest, and (iii) potential second-order attacks where adversaries would first (i.e., before Trojan insertion) try to bypass the locking defense, e.g., using advanced machine learning attacks. Finally, we release all our artifacts for independent verification [2].
Security Closure of IC Layouts Against Hardware Trojans
Nov 15, 2022Due to cost benefits, supply chains of integrated circuits (ICs) are largely outsourced nowadays. However, passing ICs through various third-party providers gives rise to many threats, like piracy of IC intellectual property or insertion of hardware Trojans, i.e., malicious circuit modifications. In this work, we proactively and systematically harden the physical layouts of ICs against post-design insertion of Trojans. Toward that end, we propose a multiplexer-based logic-locking scheme that is (i) devised for layout-level Trojan prevention, (ii) resilient against state-of-the-art, oracle-less machine learning attacks, and (iii) fully integrated into a tailored, yet generic, commercial-grade design flow. Our work provides in-depth security and layout analysis on a challenging benchmark suite. We show that ours can render layouts resilient, with reasonable overheads, against Trojan insertion in general and also against second-order attacks (i.e., adversaries seeking to bypass the locking defense in an oracle-less setting). We release our layout artifacts for independent verification [29] and we will release our methodology's source code.
Attacking Split Manufacturing from a Deep Learning Perspective
Jul 08, 2020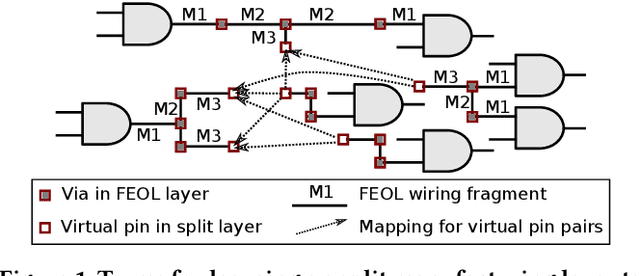

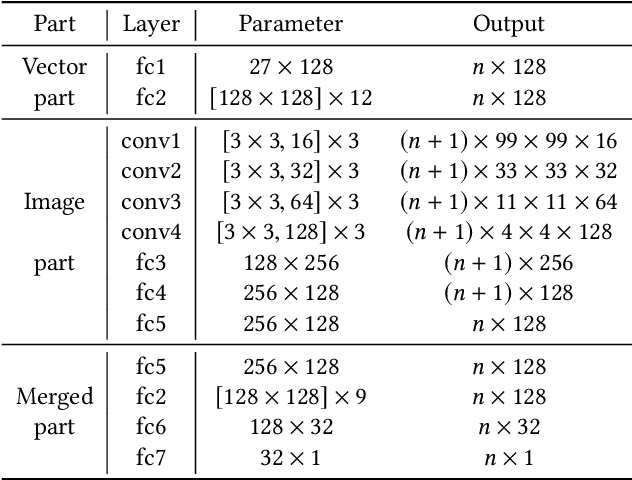
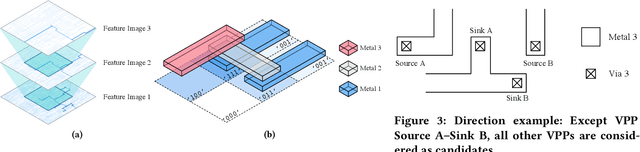
The notion of integrated circuit split manufacturing which delegates the front-end-of-line (FEOL) and back-end-of-line (BEOL) parts to different foundries, is to prevent overproduction, piracy of the intellectual property (IP), or targeted insertion of hardware Trojans by adversaries in the FEOL facility. In this work, we challenge the security promise of split manufacturing by formulating various layout-level placement and routing hints as vector- and image-based features. We construct a sophisticated deep neural network which can infer the missing BEOL connections with high accuracy. Compared with the publicly available network-flow attack [1], for the same set of ISCAS-85 benchmarks, we achieve 1.21X accuracy when splitting on M1 and 1.12X accuracy when splitting on M3 with less than 1% running time.
Are Adversarial Perturbations a Showstopper for ML-Based CAD? A Case Study on CNN-Based Lithographic Hotspot Detection
Jun 25, 2019


There is substantial interest in the use of machine learning (ML) based techniques throughout the electronic computer-aided design (CAD) flow, particularly those based on deep learning. However, while deep learning methods have surpassed state-of-the-art performance in several applications, they have exhibited intrinsic susceptibility to adversarial perturbations --- small but deliberate alterations to the input of a neural network, precipitating incorrect predictions. In this paper, we seek to investigate whether adversarial perturbations pose risks to ML-based CAD tools, and if so, how these risks can be mitigated. To this end, we use a motivating case study of lithographic hotspot detection, for which convolutional neural networks (CNN) have shown great promise. In this context, we show the first adversarial perturbation attacks on state-of-the-art CNN-based hotspot detectors; specifically, we show that small (on average 0.5% modified area), functionality preserving and design-constraint satisfying changes to a layout can nonetheless trick a CNN-based hotspot detector into predicting the modified layout as hotspot free (with up to 99.7% success). We propose an adversarial retraining strategy to improve the robustness of CNN-based hotspot detection and show that this strategy significantly improves robustness (by a factor of ~3) against adversarial attacks without compromising classification accuracy.