 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLERA: A Unified Model for Joint Cognitive Load and Eye Region Analysis in the Wild
Jun 26, 2023



Non-intrusive, real-time analysis of the dynamics of the eye region allows us to monitor humans' visual attention allocation and estimate their mental state during the performance of real-world tasks, which can potentially benefit a wide range of human-computer interaction (HCI) applications. While commercial eye-tracking devices have been frequently employed, the difficulty of customizing these devices places unnecessary constraints on the exploration of more efficient, end-to-end models of eye dynamics. In this work, we propose CLERA, a unified model for Cognitive Load and Eye Region Analysis, which achieves precise keypoint detection and spatiotemporal tracking in a joint-learning framework. Our method demonstrates significant efficiency and outperforms prior work on tasks including cognitive load estimation, eye landmark detection, and blink estimation. We also introduce a large-scale dataset of 30k human faces with joint pupil, eye-openness, and landmark annotation, which aims to support future HCI research on human factors and eye-related analysis.
Object as Distribution
Jul 25, 2019
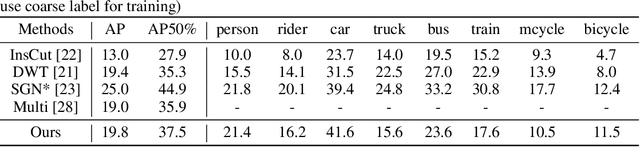
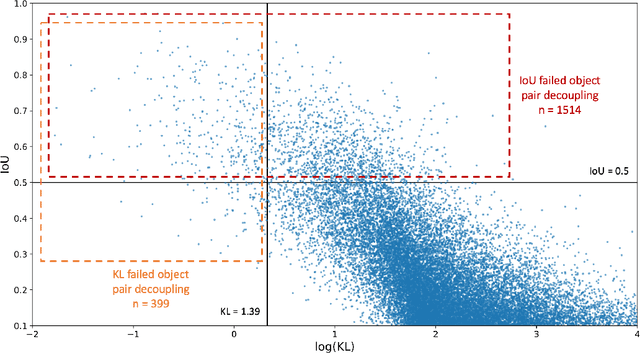

Object detection is a critical part of visual scene understanding. The representation of the object in the detection task has important implications on the efficiency and feasibility of annotation, robustness to occlusion, pose, lighting, and other visual sources of semantic uncertainty, and effectiveness in real-world applications (e.g., autonomous driving). Popular object representations include 2D and 3D bounding boxes, polygons, splines, pixels, and voxels. Each have their strengths and weakness. In this work, we propose a new representation of objects based on the bivariate normal distribution. This distribution-based representation has the benefit of robust detection of highly-overlapping objects and the potential for improved downstream tracking and instance segmentation tasks due to the statistical representation of object edges. We provide qualitative evaluation of this representation for the object detection task and quantitative evaluation of its use in a baseline algorithm for the instance segmentation task.
Dynamics of Pedestrian Crossing Decisions Based on Vehicle Trajectories in Large-Scale Simulated and Real-World Data
Apr 08, 2019

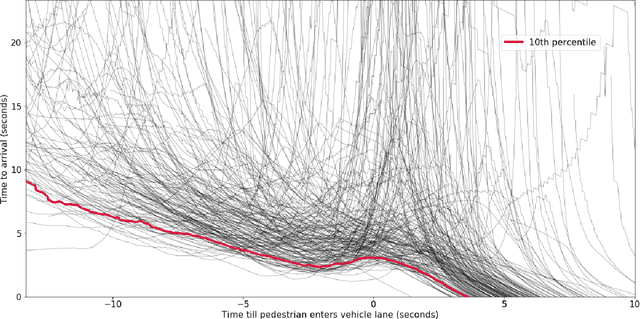
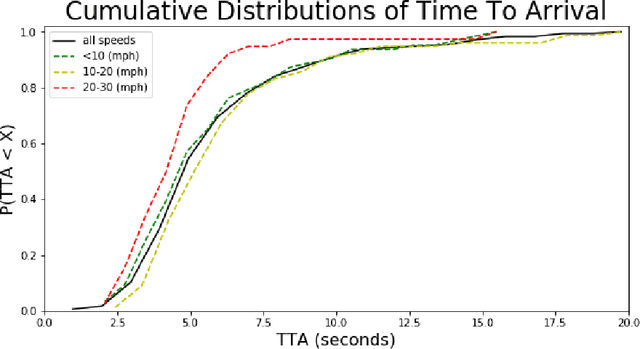
Humans, as both pedestrians and drivers, generally skillfully navigate traffic intersections. Despite the uncertainty, danger, and the non-verbal nature of communication commonly found in these interactions, there are surprisingly few collisions considering the total number of interactions. As the role of automation technology in vehicles grows, it becomes increasingly critical to understand the relationship between pedestrian and driver behavior: how pedestrians perceive the actions of a vehicle/driver and how pedestrians make crossing decisions. The relationship between time-to-arrival (TTA) and pedestrian gap acceptance (i.e., whether a pedestrian chooses to cross under a given window of time to cross) has been extensively investigated. However, the dynamic nature of vehicle trajectories in the context of non-verbal communication has not been systematically explored. Our work provides evidence that trajectory dynamics, such as changes in TTA, can be powerful signals in the non-verbal communication between drivers and pedestrians. Moreover, we investigate these effects in both simulated and real-world datasets, both larger than have previously been considered in literature to the best of our knowledge.
Value of Temporal Dynamics Information in Driving Scene Segmentation
Mar 21, 2019



Semantic scene segmentation has primarily been addressed by forming representations of single images both with supervised and unsupervised methods. The problem of semantic segmentation in dynamic scenes has begun to recently receive attention with video object segmentation approaches. What is not known is how much extra information the temporal dynamics of the visual scene carries that is complimentary to the information available in the individual frames of the video. There is evidence that the human visual system can effectively perceive the scene from temporal dynamics information of the scene's changing visual characteristics without relying on the visual characteristics of individual snapshots themselves. Our work takes steps to explore whether machine perception can exhibit similar properties by combining appearance-based representations and temporal dynamics representations in a joint-learning problem that reveals the contribution of each toward successful dynamic scene segmentation. Additionally, we provide the MIT Driving Scene Segmentation dataset, which is a large-scale full driving scene segmentation dataset, densely annotated for every pixel and every one of 5,000 video frames. This dataset is intended to help further the exploration of the value of temporal dynamics information for semantic segmentation in video.
DeepTraffic: Crowdsourced Hyperparameter Tuning of Deep Reinforcement Learning Systems for Multi-Agent Dense Traffic Navigation
Jan 03, 2019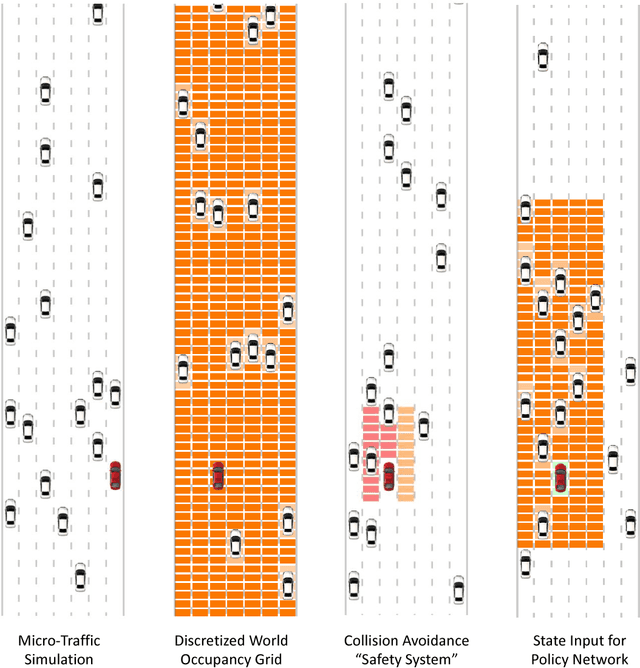
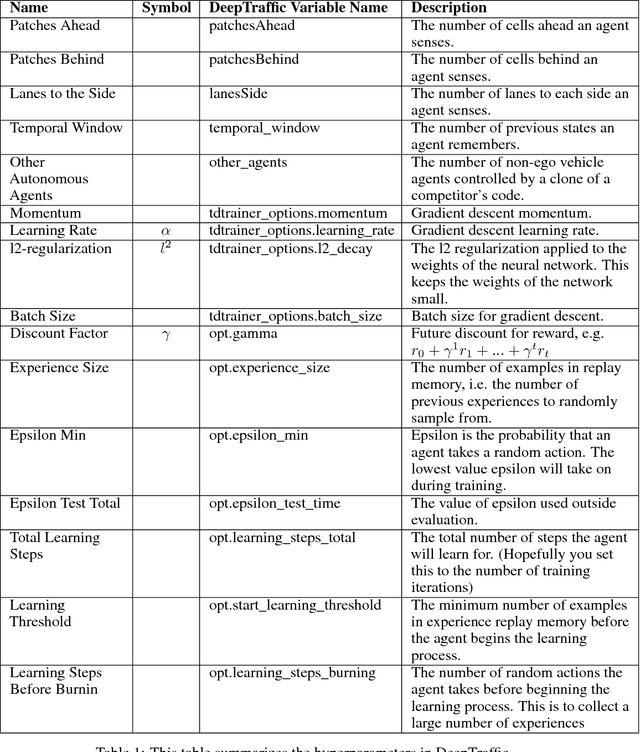
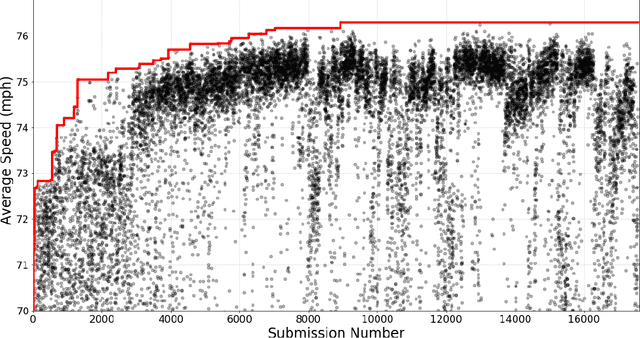
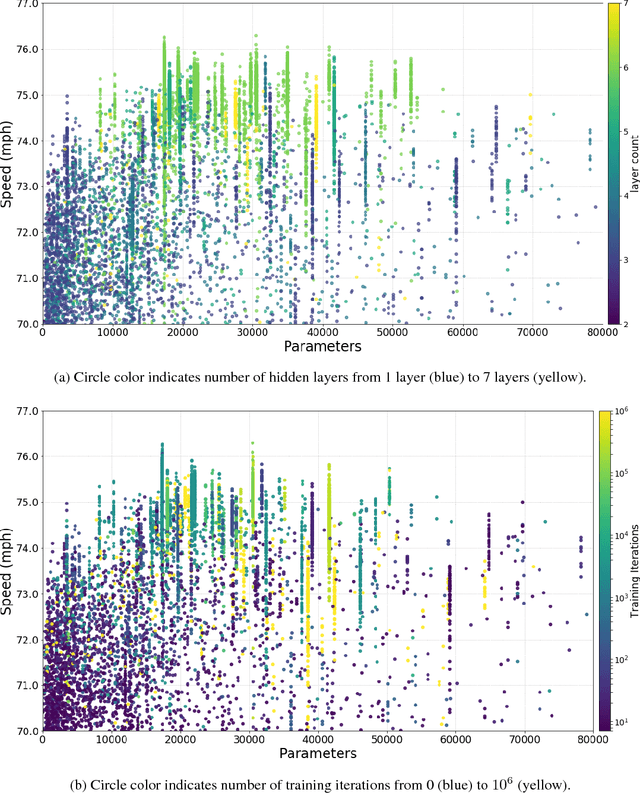
We present a traffic simulation named DeepTraffic where the planning systems for a subset of the vehicles are handled by a neural network as part of a model-free, off-policy reinforcement learning process. The primary goal of DeepTraffic is to make the hands-on study of deep reinforcement learning accessible to thousands of students, educators, and researchers in order to inspire and fuel the exploration and evaluation of deep Q-learning network variants and hyperparameter configurations through large-scale, open competition. This paper investigates the crowd-sourced hyperparameter tuning of the policy network that resulted from the first iteration of the DeepTraffic competition where thousands of participants actively searched through the hyperparameter space.
Human-Centered Autonomous Vehicle Systems: Principles of Effective Shared Autonomy
Oct 03, 2018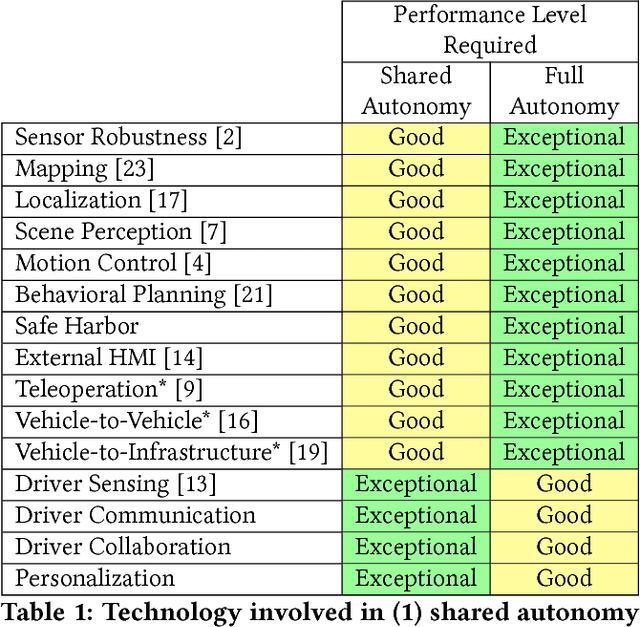



Building effective, enjoyable, and safe autonomous vehicles is a lot harder than has historically been considered. The reason is that, simply put, an autonomous vehicle must interact with human beings. This interaction is not a robotics problem nor a machine learning problem nor a psychology problem nor an economics problem nor a policy problem. It is all of these problems put into one. It challenges our assumptions about the limitations of human beings at their worst and the capabilities of artificial intelligence systems at their best. This work proposes a set of principles for designing and building autonomous vehicles in a human-centered way that does not run away from the complexity of human nature but instead embraces it. We describe our development of the Human-Centered Autonomous Vehicle (HCAV) as an illustrative case study of implementing these principles in practice.
MIT Autonomous Vehicle Technology Study: Large-Scale Deep Learning Based Analysis of Driver Behavior and Interaction with Automation
Sep 30, 2018
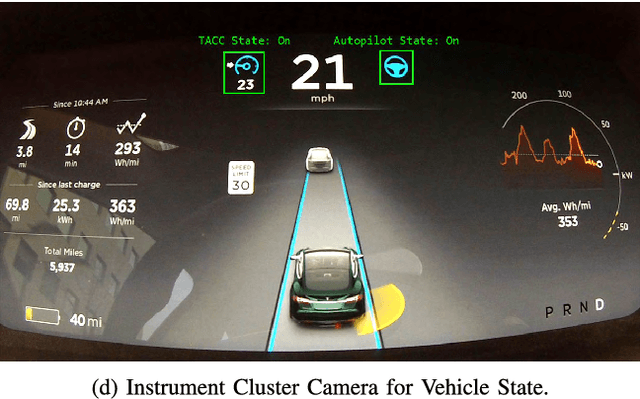
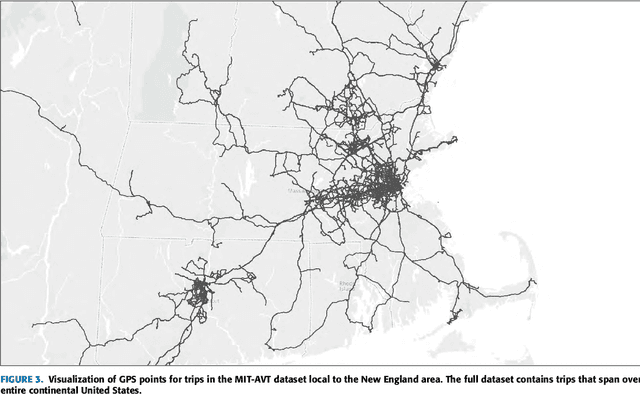
For the foreseeble future, human beings will likely remain an integral part of the driving task, monitoring the AI system as it performs anywhere from just over 0% to just under 100% of the driving. The governing objectives of the MIT Autonomous Vehicle Technology (MIT-AVT) study are to (1) undertake large-scale real-world driving data collection that includes high-definition video to fuel the development of deep learning based internal and external perception systems, (2) gain a holistic understanding of how human beings interact with vehicle automation technology by integrating video data with vehicle state data, driver characteristics, mental models, and self-reported experiences with technology, and (3) identify how technology and other factors related to automation adoption and use can be improved in ways that save lives. In pursuing these objectives, we have instrumented 21 Tesla Model S and Model X vehicles, 2 Volvo S90 vehicles, 2 Range Rover Evoque, and 2 Cadillac CT6 vehicles for both long-term (over a year per driver) and medium term (one month per driver) naturalistic driving data collection. Furthermore, we are continually developing new methods for analysis of the massive-scale dataset collected from the instrumented vehicle fleet. The recorded data streams include IMU, GPS, CAN messages, and high-definition video streams of the driver face, the driver cabin, the forward roadway, and the instrument cluster (on select vehicles). The study is on-going and growing. To date, we have 99 participants, 11,846 days of participation, 405,807 miles, and 5.5 billion video frames. This paper presents the design of the study, the data collection hardware, the processing of the data, and the computer vision algorithms currently being used to extract actionable knowledge from the data.
Arguing Machines: Human Supervision of Black Box AI Systems That Make Life-Critical Decisions
Sep 24, 2018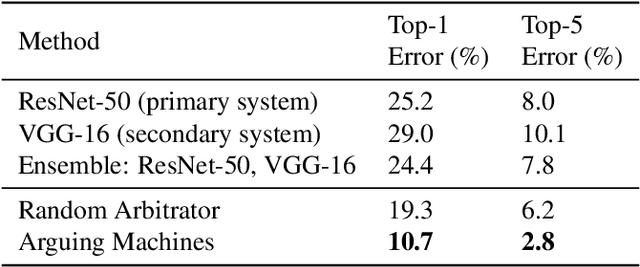

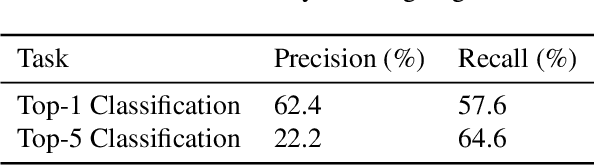
We consider the paradigm of a black box AI system that makes life-critical decisions. We propose an "arguing machines" framework that pairs the primary AI system with a secondary one that is independently trained to perform the same task. We show that disagreement between the two systems, without any knowledge of underlying system design or operation, is sufficient to arbitrarily improve the accuracy of the overall decision pipeline given human supervision over disagreements. We demonstrate this system in two applications: (1) an illustrative example of image classification and (2) on large-scale real-world semi-autonomous driving data. For the first application, we apply this framework to image classification achieving a reduction from 8.0% to 2.8% top-5 error on ImageNet. For the second application, we apply this framework to Tesla Autopilot and demonstrate the ability to predict 90.4% of system disengagements that were labeled by human annotators as challenging and needing human supervision.
SideEye: A Generative Neural Network Based Simulator of Human Peripheral Vision
Oct 23, 2017


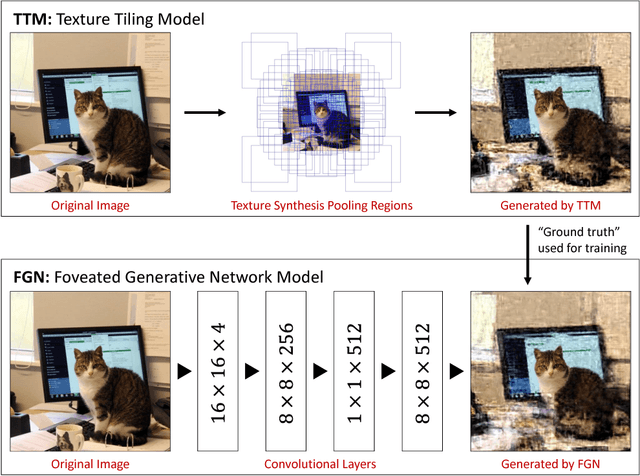
Foveal vision makes up less than 1% of the visual field. The other 99% is peripheral vision. Precisely what human beings see in the periphery is both obvious and mysterious in that we see it with our own eyes but can't visualize what we see, except in controlled lab experiments. Degradation of information in the periphery is far more complex than what might be mimicked with a radial blur. Rather, behaviorally-validated models hypothesize that peripheral vision measures a large number of local texture statistics in pooling regions that overlap and grow with eccentricity. In this work, we develop a new method for peripheral vision simulation by training a generative neural network on a behaviorally-validated full-field synthesis model. By achieving a 21,000 fold reduction in running time, our approach is the first to combine realism and speed of peripheral vision simulation to a degree that provides a whole new way to approach visual design: through peripheral visualization.
Semi-Automated Annotation of Discrete States in Large Video Datasets
Dec 03, 2016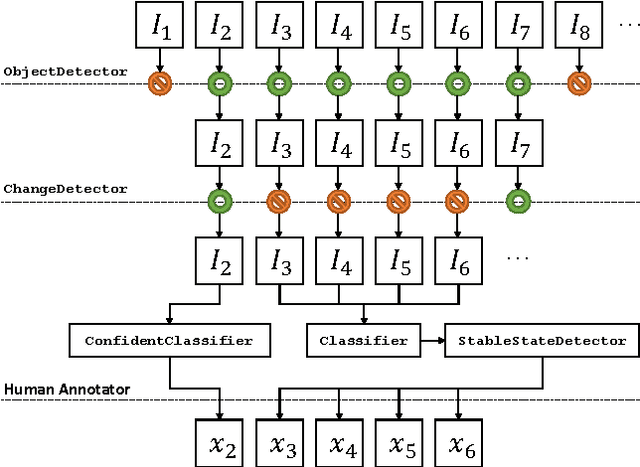

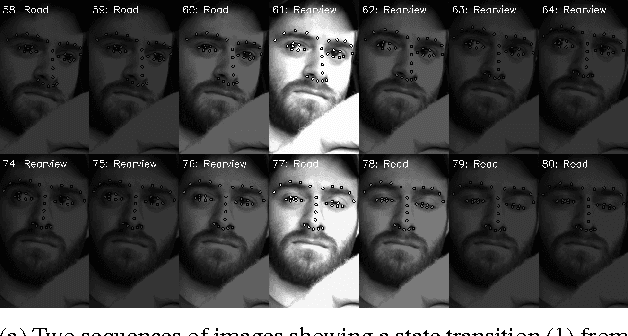
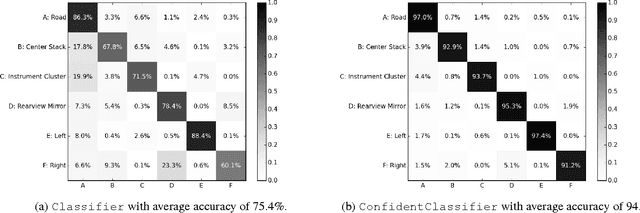
We propose a framework for semi-automated annotation of video frames where the video is of an object that at any point in time can be labeled as being in one of a finite number of discrete states. A Hidden Markov Model (HMM) is used to model (1) the behavior of the underlying object and (2) the noisy observation of its state through an image processing algorithm. The key insight of this approach is that the annotation of frame-by-frame video can be reduced from a problem of labeling every single image to a problem of detecting a transition between states of the underlying objected being recording on video. The performance of the framework is evaluated on a driver gaze classification dataset composed of 16,000,000 images that were fully annotated over 6,000 hours of direct manual annotation labor. On this dataset, we achieve a 13x reduction in manual annotation for an average accuracy of 99.1% and a 84x reduction for an average accuracy of 91.2%.