 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Automated Annotation of Discrete States in Large Video Datasets
Paper and Code
Dec 03, 2016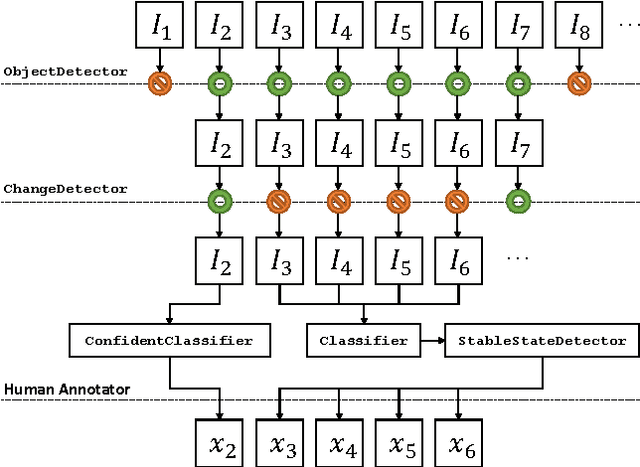

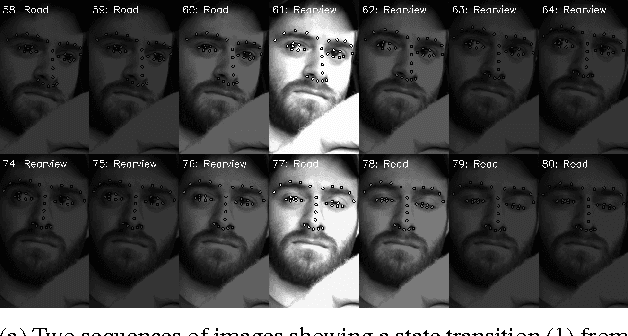
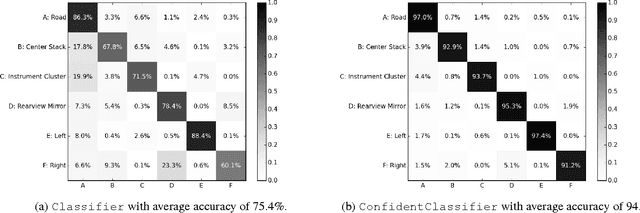
We propose a framework for semi-automated annotation of video frames where the video is of an object that at any point in time can be labeled as being in one of a finite number of discrete states. A Hidden Markov Model (HMM) is used to model (1) the behavior of the underlying object and (2) the noisy observation of its state through an image processing algorithm. The key insight of this approach is that the annotation of frame-by-frame video can be reduced from a problem of labeling every single image to a problem of detecting a transition between states of the underlying objected being recording on video. The performance of the framework is evaluated on a driver gaze classification dataset composed of 16,000,000 images that were fully annotated over 6,000 hours of direct manual annotation labor. On this dataset, we achieve a 13x reduction in manual annotation for an average accuracy of 99.1% and a 84x reduction for an average accuracy of 91.2%.