 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOHA: Auxiliary Loss Optimization for Hypothesis Augmentation
Mar 13, 2019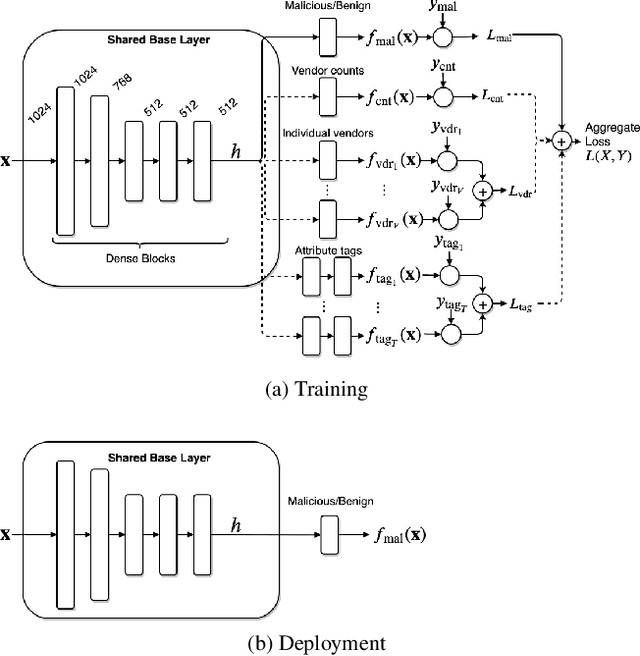
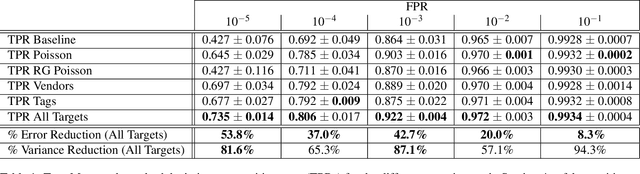
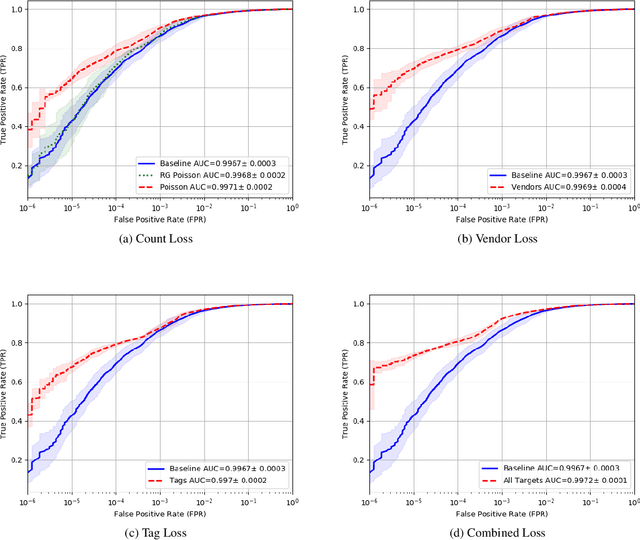
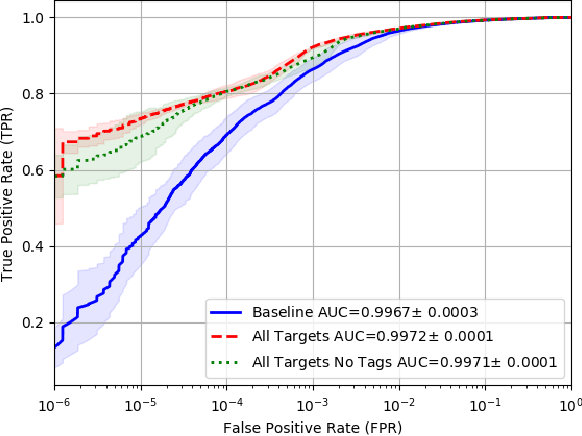
Malware detection is a popular application of Machine Learning for Information Security (ML-Sec), in which an ML classifier is trained to predict whether a given file is malware or benignware. Parameters of this classifier are typically optimized such that outputs from the model over a set of input samples most closely match the samples' true malicious/benign (1/0) target labels. However, there are often a number of other sources of contextual metadata for each malware sample, beyond an aggregate malicious/benign label, including multiple labeling sources and malware type information (e.g., ransomware, trojan, etc.), which we can feed to the classifier as auxiliary prediction targets. In this work, we fit deep neural networks to multiple additional targets derived from metadata in a threat intelligence feed for Portable Executable (PE) malware and benignware, including a multi-source malicious/benign loss, a count loss on multi-source detections, and a semantic malware attribute tag loss. We find that incorporating multiple auxiliary loss terms yields a marked improvement in performance on the main detection task. We also demonstrate that these gains likely stem from a more informed neural network representation and are not due to a regularization artifact of multi-target learning. Our auxiliary loss architecture yields a significant reduction in detection error rate (false negatives) of 42.6% at a false positive rate (FPR) of $10^{-3}$ when compared to a similar model with only one target, and a decrease of 53.8% at $10^{-5}$ FPR.
Principled Uncertainty Estimation for Deep Neural Networks
Oct 29, 2018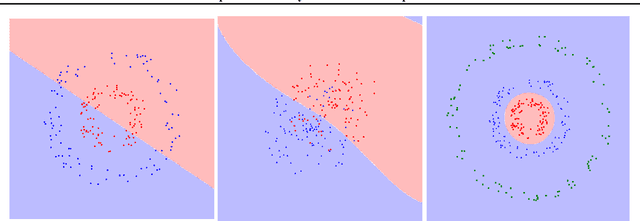
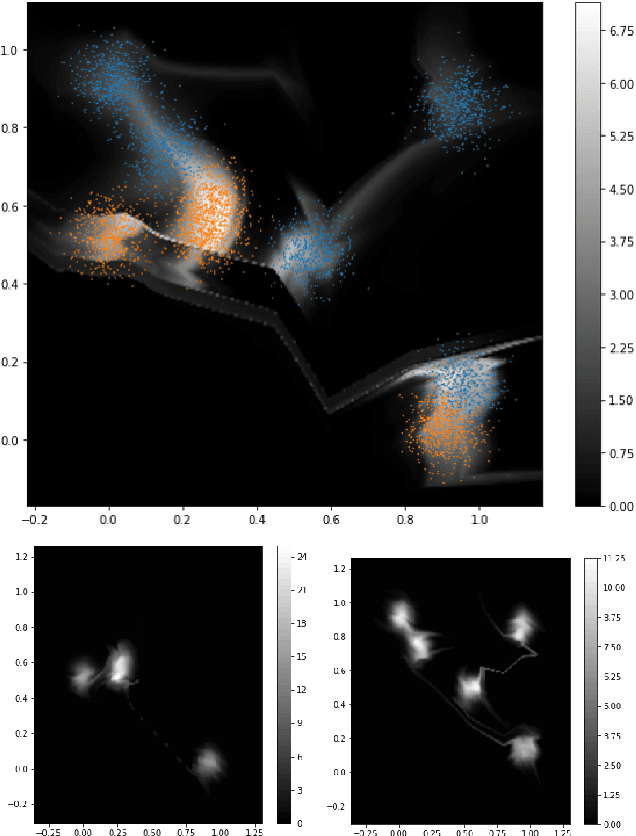
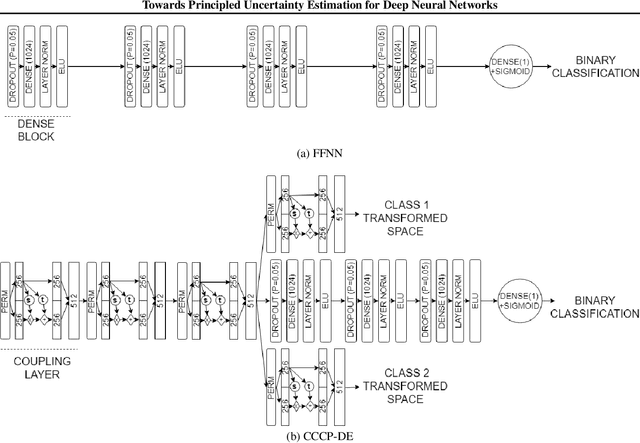

When the cost of misclassifying a sample is high, it is useful to have an accurate estimate of uncertainty in the prediction for that sample. There are also multiple types of uncertainty which are best estimated in different ways, for example, uncertainty that is intrinsic to the training set may be well-handled by a Bayesian approach, while uncertainty introduced by shifts between training and query distributions may be better-addressed by density/support estimation. In this paper, we examine three types of uncertainty: model capacity uncertainty, intrinsic data uncertainty, and open set uncertainty, and review techniques that have been derived to address each one. We then introduce a unified hierarchical model, which combines methods from Bayesian inference, invertible latent density inference, and discriminative classification in a single end-to-end deep neural network topology to yield efficient per-sample uncertainty estimation. Our approach addresses all three uncertainty types and readily accommodates prior/base rates for binary detection.
A Deep Learning Approach to Fast, Format-Agnostic Detection of Malicious Web Content
Apr 13, 2018
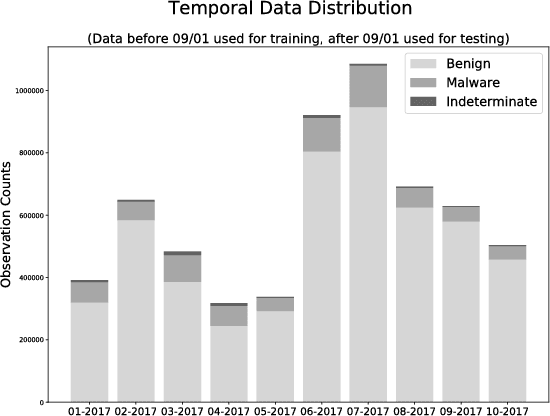
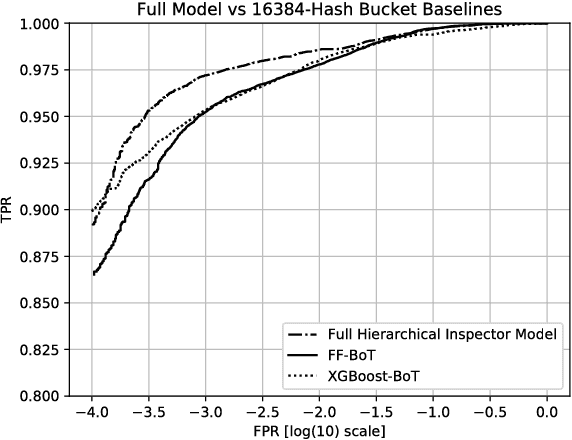
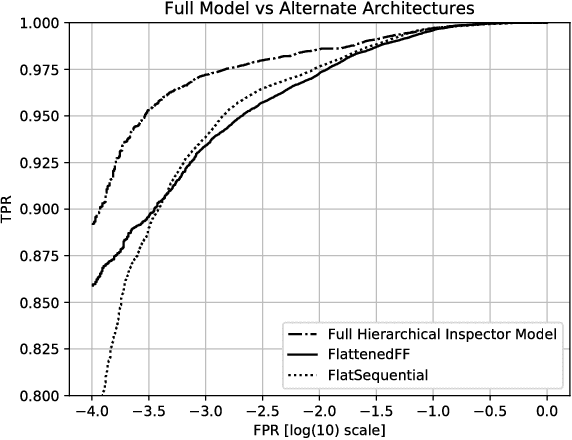
Malicious web content is a serious problem on the Internet today. In this paper we propose a deep learning approach to detecting malevolent web pages. While past work on web content detection has relied on syntactic parsing or on emulation of HTML and Javascript to extract features, our approach operates directly on a language-agnostic stream of tokens extracted directly from static HTML files with a simple regular expression. This makes it fast enough to operate in high-frequency data contexts like firewalls and web proxies, and allows it to avoid the attack surface exposure of complex parsing and emulation code. Unlike well-known approaches such as bag-of-words models, which ignore spatial information, our neural network examines content at hierarchical spatial scales, allowing our model to capture locality and yielding superior accuracy compared to bag-of-words baselines. Our proposed architecture achieves a 97.5% detection rate at a 0.1% false positive rate, and classifies small-batched web pages at a rate of over 100 per second on commodity hardware. The speed and accuracy of our approach makes it appropriate for deployment to endpoints, firewalls, and web proxies.
Git Blame Who?: Stylistic Authorship Attribution of Small, Incomplete Source Code Fragments
Mar 16, 2017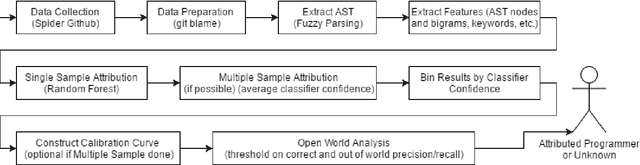
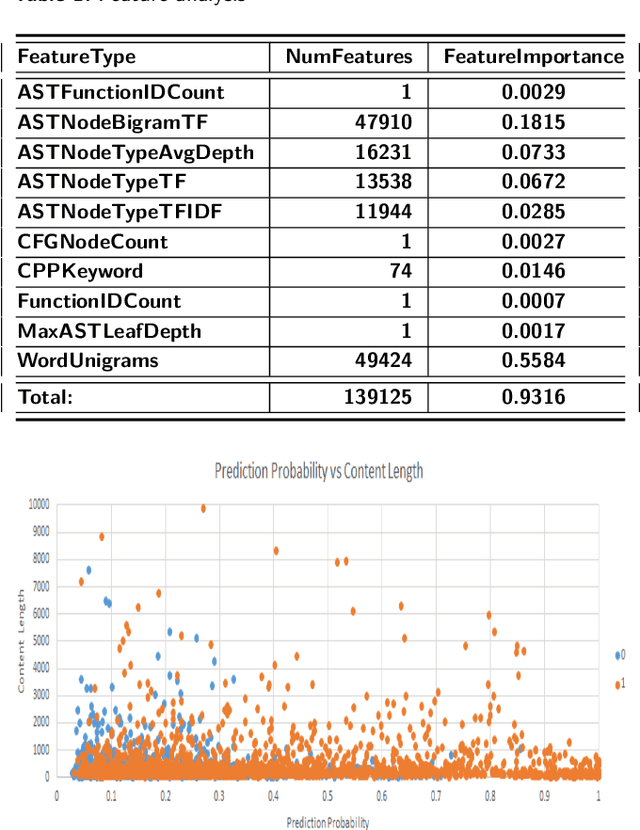
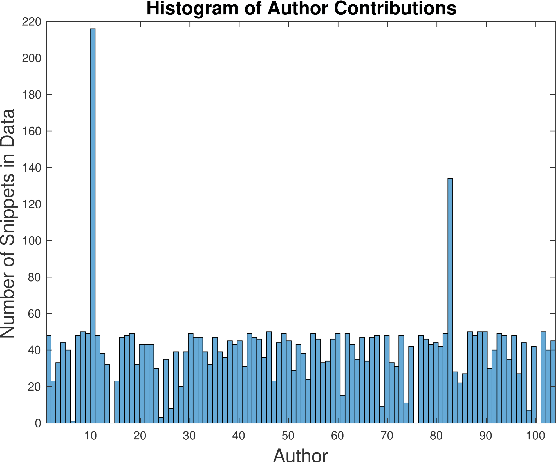
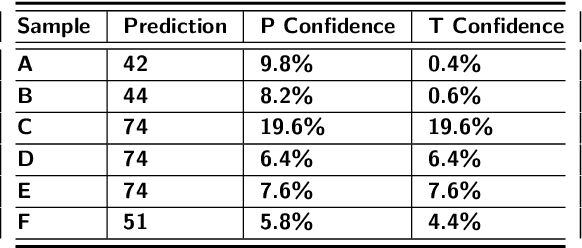
Program authorship attribution has implications for the privacy of programmers who wish to contribute code anonymously. While previous work has shown that complete files that are individually authored can be attributed, we show here for the first time that accounts belonging to open source contributors containing short, incomplete, and typically uncompilable fragments can also be effectively attributed. We propose a technique for authorship attribution of contributor accounts containing small source code samples, such as those that can be obtained from version control systems or other direct comparison of sequential versions. We show that while application of previous methods to individual small source code samples yields an accuracy of about 73% for 106 programmers as a baseline, by ensembling and averaging the classification probabilities of a sufficiently large set of samples belonging to the same author we achieve 99% accuracy for assigning the set of samples to the correct author. Through these results, we demonstrate that attribution is an important threat to privacy for programmers even in real-world collaborative environments such as GitHub. Additionally, we propose the use of calibration curves to identify samples by unknown and previously unencountered authors in the open world setting. We show that we can also use these calibration curves in the case that we do not have linking information and thus are forced to classify individual samples directly. This is because the calibration curves allow us to identify which samples are more likely to have been correctly attributed. Using such a curve can help an analyst choose a cut-off point which will prevent most misclassifications, at the cost of causing the rejection of some of the more dubious correct attributions.
Crafting Adversarial Input Sequences for Recurrent Neural Networks
Apr 28, 2016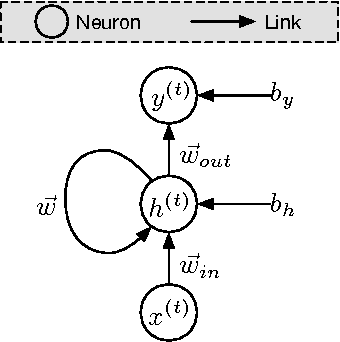
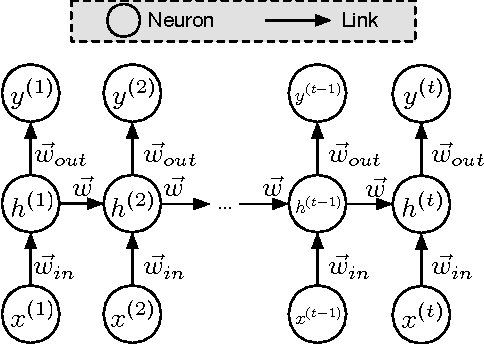
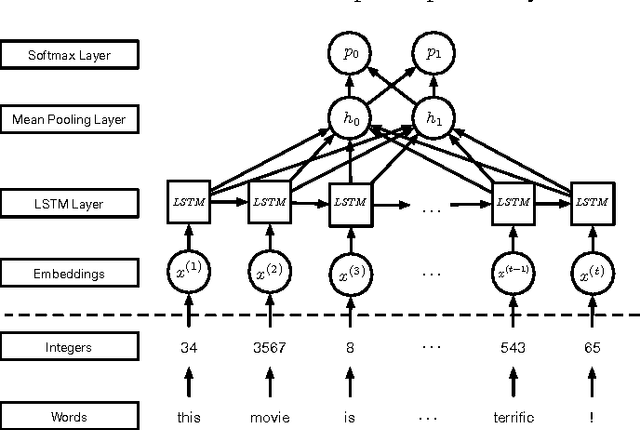
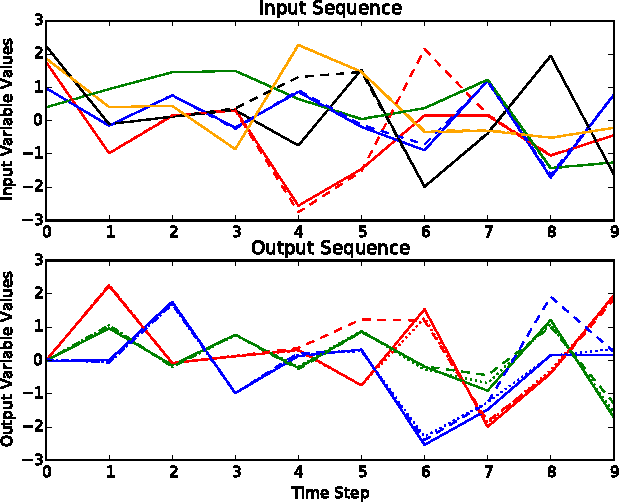
Machine learning models are frequently used to solve complex security problems, as well as to make decisions in sensitive situations like guiding autonomous vehicles or predicting financial market behaviors. Previous efforts have shown that numerous machine learning models were vulnerable to adversarial manipulations of their inputs taking the form of adversarial samples. Such inputs are crafted by adding carefully selected perturbations to legitimate inputs so as to force the machine learning model to misbehave, for instance by outputting a wrong class if the machine learning task of interest is classification. In fact, to the best of our knowledge, all previous work on adversarial samples crafting for neural network considered models used to solve classification tasks, most frequently in computer vision applications. In this paper, we contribute to the field of adversarial machine learning by investigating adversarial input sequences for recurrent neural networks processing sequential data. We show that the classes of algorithms introduced previously to craft adversarial samples misclassified by feed-forward neural networks can be adapted to recurrent neural networks. In a experiment, we show that adversaries can craft adversarial sequences misleading both categorical and sequential recurrent neural networks.