 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Content Filtering through knowledge distillation of Large Language Models
May 10, 2023We introduce a state-of-the-art approach for URL categorization that leverages the power of Large Language Models (LLMs) to address the primary objectives of web content filtering: safeguarding organizations from legal and ethical risks, limiting access to high-risk or suspicious websites, and fostering a secure and professional work environment. Our method utilizes LLMs to generate accurate classifications and then employs established knowledge distillation techniques to create smaller, more specialized student models tailored for web content filtering. Distillation results in a student model with a 9% accuracy rate improvement in classifying websites, sourced from customer telemetry data collected by a large security vendor, into 30 distinct content categories based on their URLs, surpassing the current state-of-the-art approach. Our student model matches the performance of the teacher LLM with 175 times less parameters, allowing the model to be used for in-line scanning of large volumes of URLs, and requires 3 orders of magnitude less manually labeled training data than the current state-of-the-art approach. Depending on the specific use case, the output generated by our approach can either be directly returned or employed as a pre-filter for more resource-intensive operations involving website images or HTML.
That Escalated Quickly: An ML Framework for Alert Prioritization
Feb 15, 2023



In place of in-house solutions, organizations are increasingly moving towards managed services for cyber defense. Security Operations Centers are specialized cybersecurity units responsible for the defense of an organization, but the large-scale centralization of threat detection is causing SOCs to endure an overwhelming amount of false positive alerts -- a phenomenon known as alert fatigue. Large collections of imprecise sensors, an inability to adapt to known false positives, evolution of the threat landscape, and inefficient use of analyst time all contribute to the alert fatigue problem. To combat these issues, we present That Escalated Quickly (TEQ), a machine learning framework that reduces alert fatigue with minimal changes to SOC workflows by predicting alert-level and incident-level actionability. On real-world data, the system is able to reduce the time it takes to respond to actionable incidents by $22.9\%$, suppress $54\%$ of false positives with a $95.1\%$ detection rate, and reduce the number of alerts an analyst needs to investigate within singular incidents by $14\%$.
AI Total: Analyzing Security ML Models with Imperfect Data in Production
Oct 13, 2021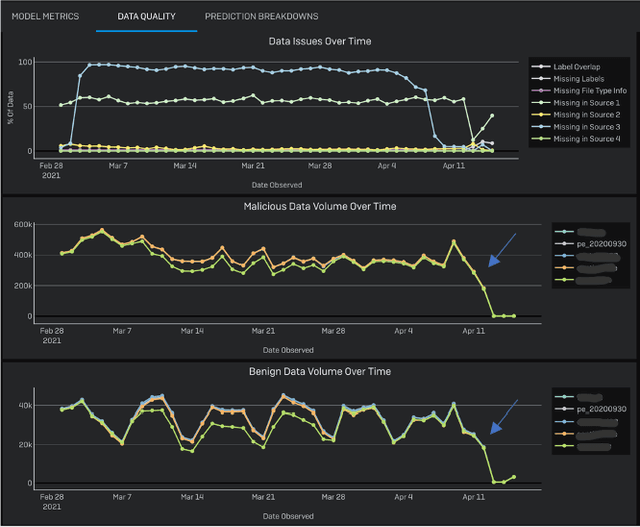
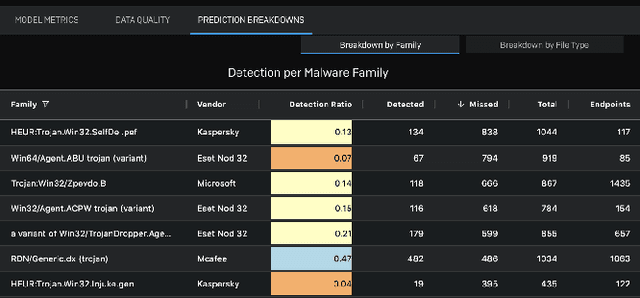
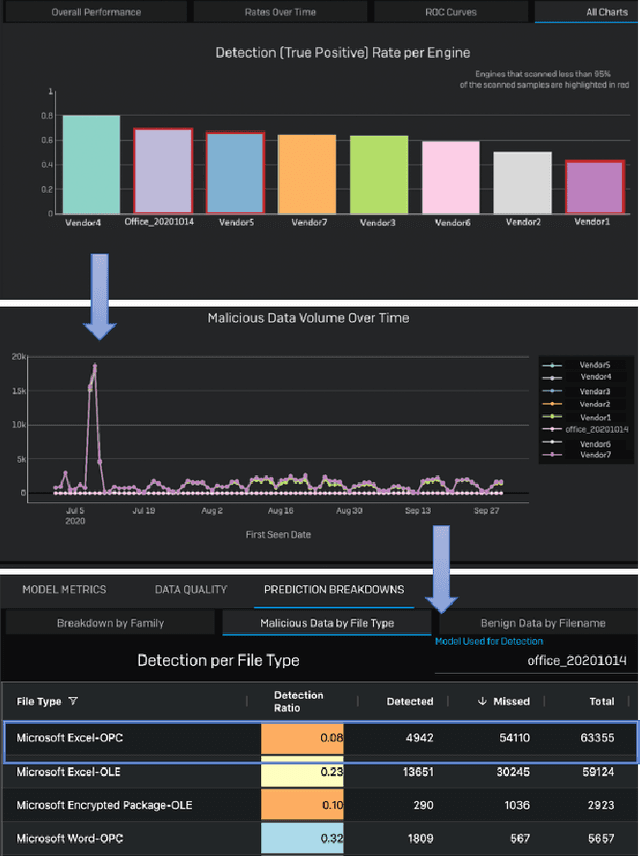
Development of new machine learning models is typically done on manually curated data sets, making them unsuitable for evaluating the models' performance during operations, where the evaluation needs to be performed automatically on incoming streams of new data. Unfortunately, pure reliance on a fully automatic pipeline for monitoring model performance makes it difficult to understand if any observed performance issues are due to model performance, pipeline issues, emerging data distribution biases, or some combination of the above. With this in mind, we developed a web-based visualization system that allows the users to quickly gather headline performance numbers while maintaining confidence that the underlying data pipeline is functioning properly. It also enables the users to immediately observe the root cause of an issue when something goes wrong. We introduce a novel way to analyze performance under data issues using a data coverage equalizer. We describe the various modifications and additional plots, filters, and drill-downs that we added on top of the standard evaluation metrics typically tracked in machine learning (ML) applications, and walk through some real world examples that proved valuable for introspecting our models.
A Simple and Agile Cloud Infrastructure to Support Cybersecurity Oriented Machine Learning Workflows
Feb 26, 2020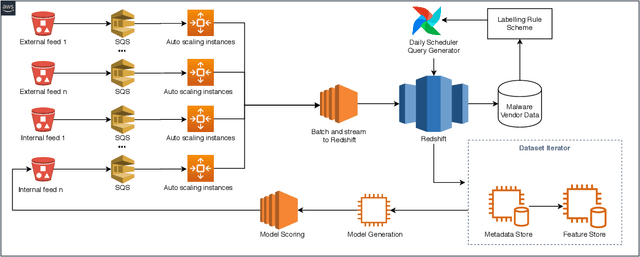
Generating up to date, well labeled datasets for machine learning (ML) security models is a unique engineering challenge, as large data volumes, complexity of labeling, and constant concept drift makes it difficult to generate effective training datasets. Here we describe a simple, resilient cloud infrastructure for generating ML training and testing datasets, that has enhanced the speed at which our team is able to research and keep in production a multitude of security ML models.
Learning from Context: Exploiting and Interpreting File Path Information for Better Malware Detection
May 16, 2019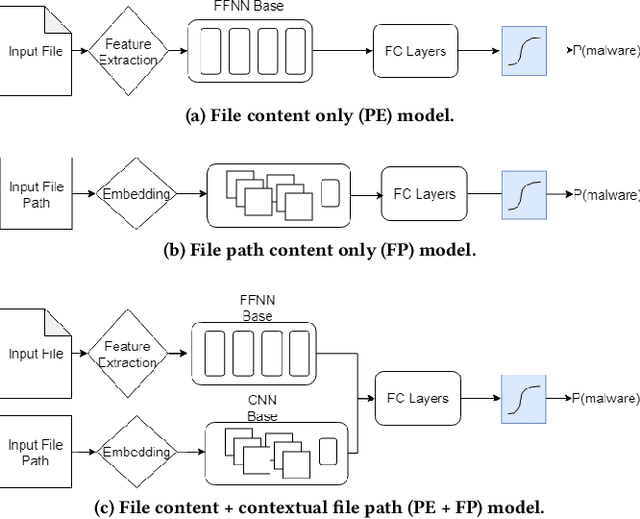

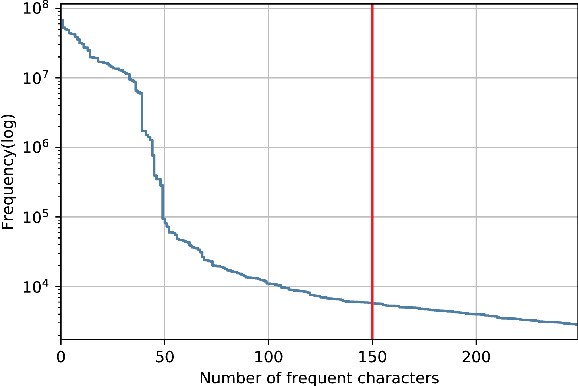
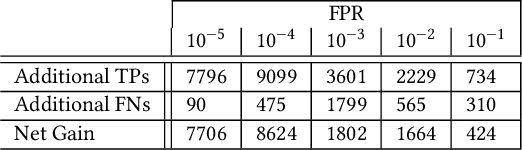
Machine learning (ML) used for static portable executable (PE) malware detection typically employs per-file numerical feature vector representations as input with one or more target labels during training. However, there is much orthogonal information that can be gleaned from the \textit{context} in which the file was seen. In this paper, we propose utilizing a static source of contextual information -- the path of the PE file -- as an auxiliary input to the classifier. While file paths are not malicious or benign in and of themselves, they do provide valuable context for a malicious/benign determination. Unlike dynamic contextual information, file paths are available with little overhead and can seamlessly be integrated into a multi-view static ML detector, yielding higher detection rates at very high throughput with minimal infrastructural changes. Here we propose a multi-view neural network, which takes feature vectors from PE file content as well as corresponding file paths as inputs and outputs a detection score. To ensure realistic evaluation, we use a dataset of approximately 10 million samples -- files and file paths from user endpoints of an actual security vendor network. We then conduct an interpretability analysis via LIME modeling to ensure that our classifier has learned a sensible representation and see which parts of the file path most contributed to change in the classifier's score. We find that our model learns useful aspects of the file path for classification, while also learning artifacts from customers testing the vendor's product, e.g., by downloading a directory of malware samples each named as their hash. We prune these artifacts from our test dataset and demonstrate reductions in false negative rate of 32.3% at a $10^{-3}$ false positive rate (FPR) and 33.1% at $10^{-4}$ FPR, over a similar topology single input PE file content only model.
SMART: Semantic Malware Attribute Relevance Tagging
May 15, 2019
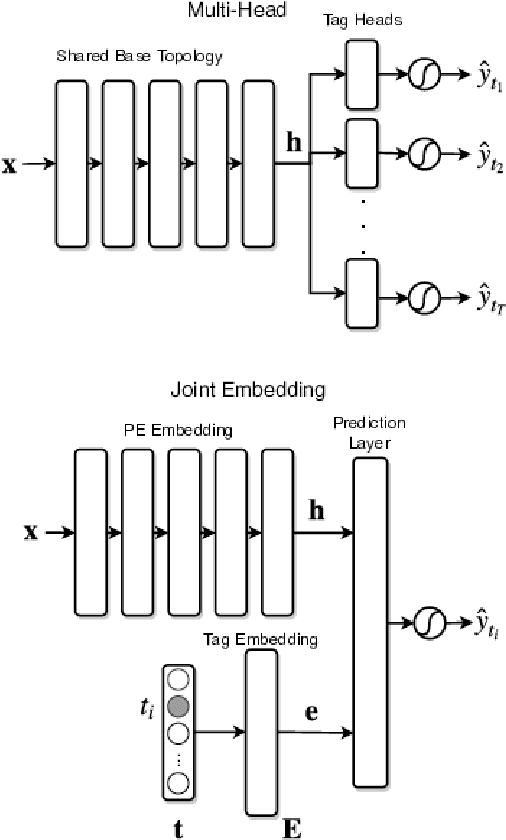

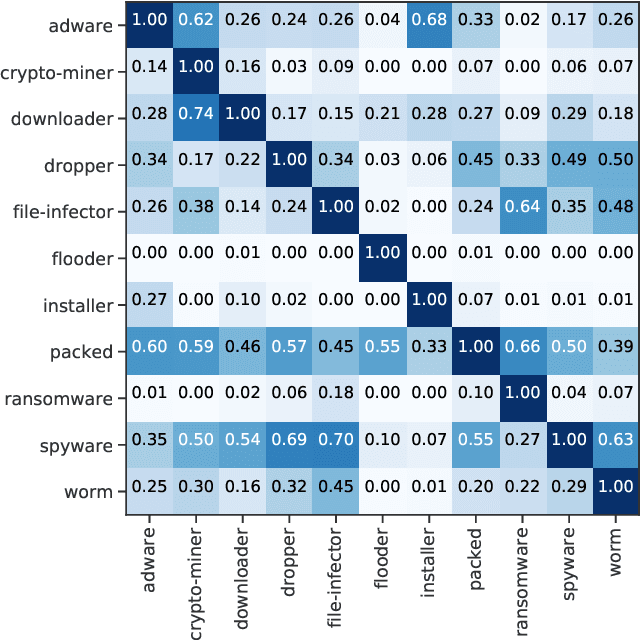
With the rapid proliferation and increased sophistication of malicious software (malware), detection methods no longer rely only on manually generated signatures but have also incorporated more general approaches like Machine Learning (ML) detection. Although powerful for conviction of malicious artifacts, these methods do not produce any further information about the type of malware that has been detected. In this work, we address the information gap between ML and signature-based detection methods by introducing an ML-based tagging model that generates human interpretable semantic descriptions of malicious software (e.g. file-infector, coin-miner), and argue that for less prevalent malware campaigns these provide potentially more useful and flexible information than malware family names. For this, we first introduce a method for deriving high-level descriptions of malware files from an ensemble of vendor family names. Then we formalize the problem of malware description as a tagging problem and propose a joint embedding deep neural network architecture that can learn to characterize portable executable (PE) files based on static analysis, thus not requiring a dynamic trace to identify behaviors at deployment time. We empirically demonstrate that when evaluated against tags extracted from an ensemble of anti-virus detection names, the proposed tagging model correctly identifies more than 93.7% of eleven possible tag descriptions for a given sample, at a deployable false positive rate (FPR) of 1% per tag. Furthermore, we show that when evaluating this model against ground truth tags derived from the results of dynamic analysis, it correctly predicts 93.5% of the labels for a given sample. These results suggest that an ML tagging model can be effectively deployed alongside a detection model for malware description.
ALOHA: Auxiliary Loss Optimization for Hypothesis Augmentation
Mar 13, 2019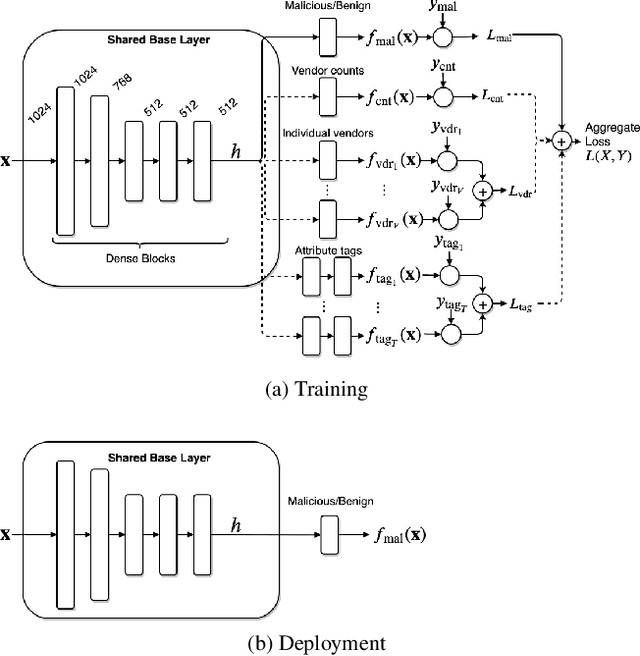
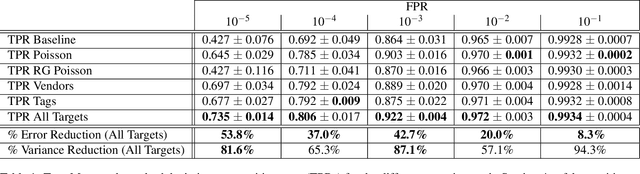
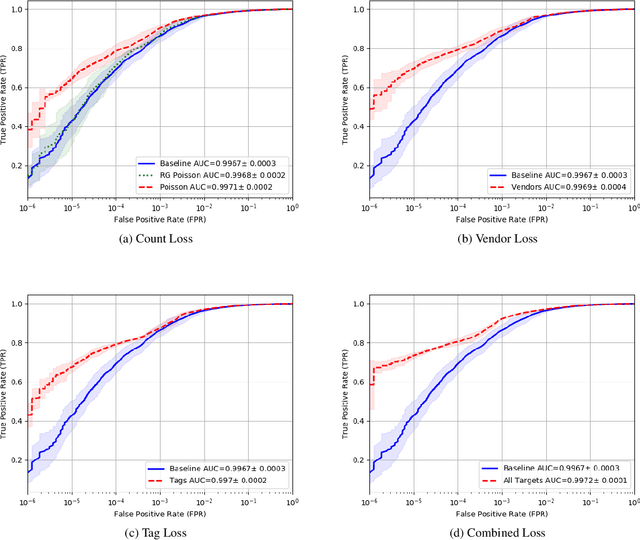
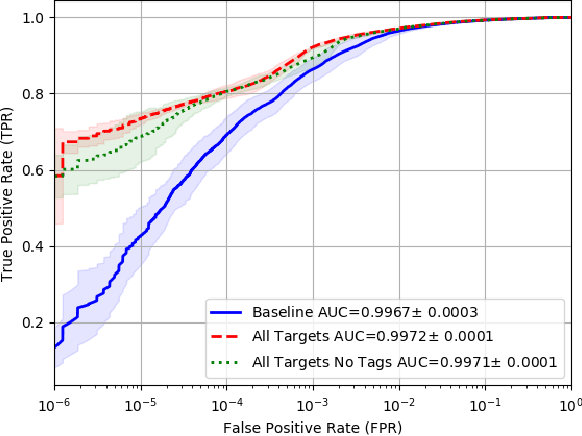
Malware detection is a popular application of Machine Learning for Information Security (ML-Sec), in which an ML classifier is trained to predict whether a given file is malware or benignware. Parameters of this classifier are typically optimized such that outputs from the model over a set of input samples most closely match the samples' true malicious/benign (1/0) target labels. However, there are often a number of other sources of contextual metadata for each malware sample, beyond an aggregate malicious/benign label, including multiple labeling sources and malware type information (e.g., ransomware, trojan, etc.), which we can feed to the classifier as auxiliary prediction targets. In this work, we fit deep neural networks to multiple additional targets derived from metadata in a threat intelligence feed for Portable Executable (PE) malware and benignware, including a multi-source malicious/benign loss, a count loss on multi-source detections, and a semantic malware attribute tag loss. We find that incorporating multiple auxiliary loss terms yields a marked improvement in performance on the main detection task. We also demonstrate that these gains likely stem from a more informed neural network representation and are not due to a regularization artifact of multi-target learning. Our auxiliary loss architecture yields a significant reduction in detection error rate (false negatives) of 42.6% at a false positive rate (FPR) of $10^{-3}$ when compared to a similar model with only one target, and a decrease of 53.8% at $10^{-5}$ FPR.
eXpose: A Character-Level Convolutional Neural Network with Embeddings For Detecting Malicious URLs, File Paths and Registry Keys
Feb 27, 2017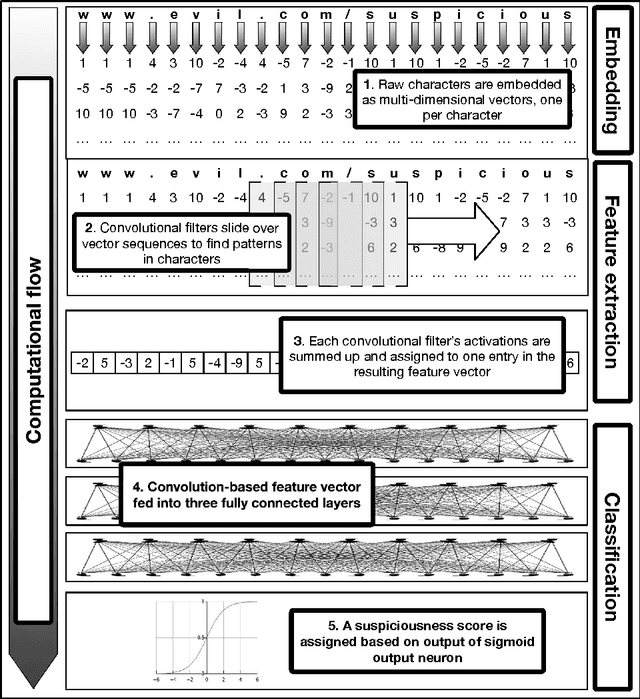

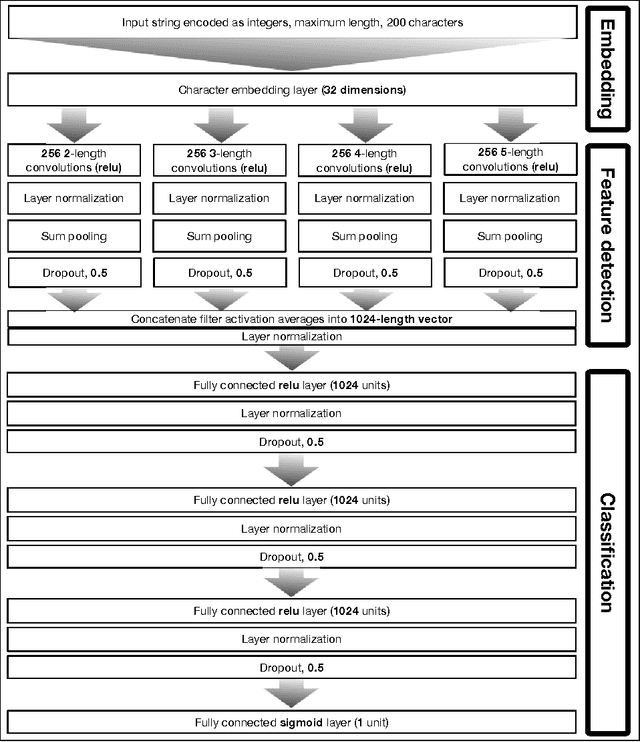

For years security machine learning research has promised to obviate the need for signature based detection by automatically learning to detect indicators of attack. Unfortunately, this vision hasn't come to fruition: in fact, developing and maintaining today's security machine learning systems can require engineering resources that are comparable to that of signature-based detection systems, due in part to the need to develop and continuously tune the "features" these machine learning systems look at as attacks evolve. Deep learning, a subfield of machine learning, promises to change this by operating on raw input signals and automating the process of feature design and extraction. In this paper we propose the eXpose neural network, which uses a deep learning approach we have developed to take generic, raw short character strings as input (a common case for security inputs, which include artifacts like potentially malicious URLs, file paths, named pipes, named mutexes, and registry keys), and learns to simultaneously extract features and classify using character-level embeddings and convolutional neural network. In addition to completely automating the feature design and extraction process, eXpose outperforms manual feature extraction based baselines on all of the intrusion detection problems we tested it on, yielding a 5%-10% detection rate gain at 0.1% false positive rate compared to these baselines.