 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-hop Reading Comprehension via Deep Reinforcement Learning based Document Traversal
May 23, 2019

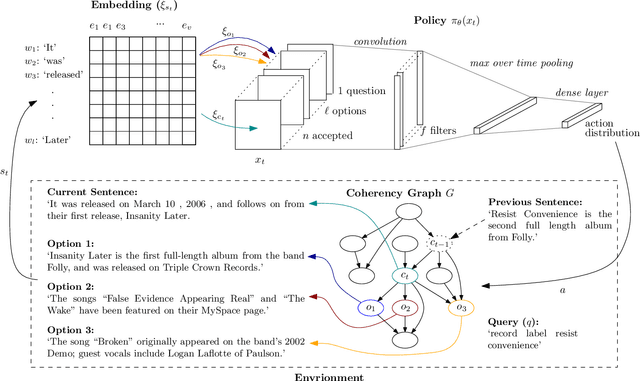

Reading Comprehension has received significant attention in recent years as high quality Question Answering (QA) datasets have become available. Despite state-of-the-art methods achieving strong overall accuracy, Multi-Hop (MH) reasoning remains particularly challenging. To address MH-QA specifically, we propose a Deep Reinforcement Learning based method capable of learning sequential reasoning across large collections of documents so as to pass a query-aware, fixed-size context subset to existing models for answer extraction. Our method is comprised of two stages: a linker, which decomposes the provided support documents into a graph of sentences, and an extractor, which learns where to look based on the current question and already-visited sentences. The result of the linker is a novel graph structure at the sentence level that preserves logical flow while still allowing rapid movement between documents. Importantly, we demonstrate that the sparsity of the resultant graph is invariant to context size. This translates to fewer decisions required from the Deep-RL trained extractor, allowing the system to scale effectively to large collections of documents. The importance of sequential decision making in the document traversal step is demonstrated by comparison to standard IE methods, and we additionally introduce a BM25-based IR baseline that retrieves documents relevant to the query only. We examine the integration of our method with existing models on the recently proposed QAngaroo benchmark and achieve consistent increases in accuracy across the board, as well as a 2-3x reduction in training time.
SMART: Semantic Malware Attribute Relevance Tagging
May 15, 2019
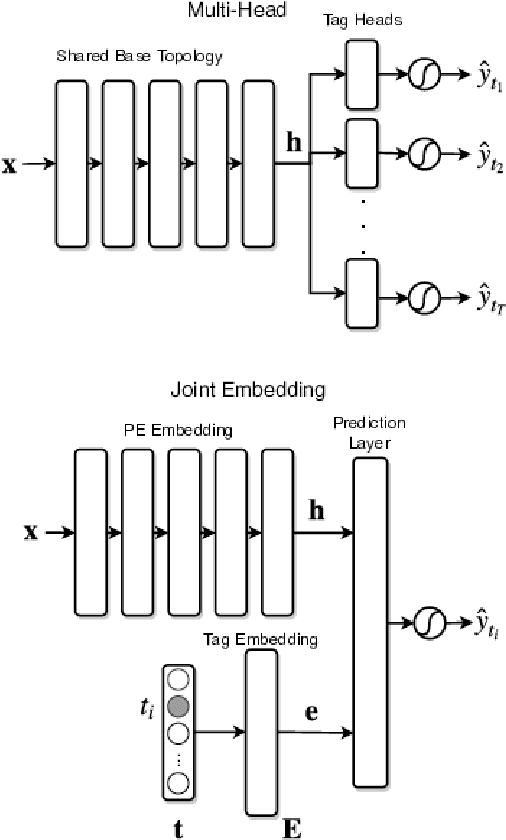

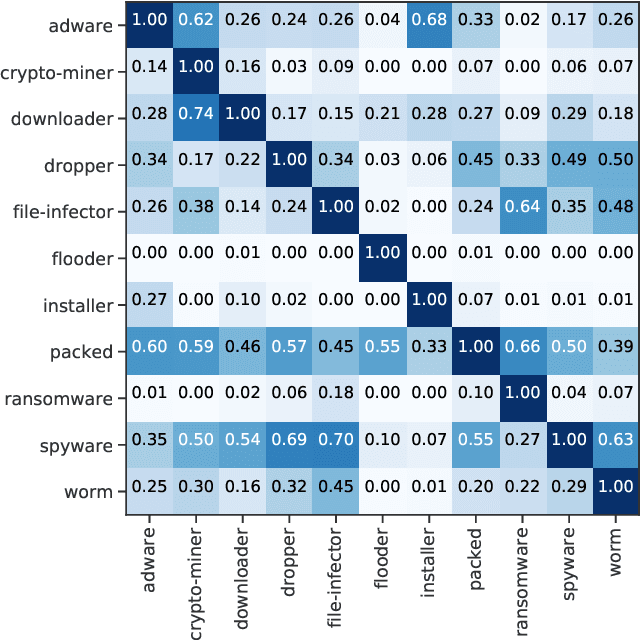
With the rapid proliferation and increased sophistication of malicious software (malware), detection methods no longer rely only on manually generated signatures but have also incorporated more general approaches like Machine Learning (ML) detection. Although powerful for conviction of malicious artifacts, these methods do not produce any further information about the type of malware that has been detected. In this work, we address the information gap between ML and signature-based detection methods by introducing an ML-based tagging model that generates human interpretable semantic descriptions of malicious software (e.g. file-infector, coin-miner), and argue that for less prevalent malware campaigns these provide potentially more useful and flexible information than malware family names. For this, we first introduce a method for deriving high-level descriptions of malware files from an ensemble of vendor family names. Then we formalize the problem of malware description as a tagging problem and propose a joint embedding deep neural network architecture that can learn to characterize portable executable (PE) files based on static analysis, thus not requiring a dynamic trace to identify behaviors at deployment time. We empirically demonstrate that when evaluated against tags extracted from an ensemble of anti-virus detection names, the proposed tagging model correctly identifies more than 93.7% of eleven possible tag descriptions for a given sample, at a deployable false positive rate (FPR) of 1% per tag. Furthermore, we show that when evaluating this model against ground truth tags derived from the results of dynamic analysis, it correctly predicts 93.5% of the labels for a given sample. These results suggest that an ML tagging model can be effectively deployed alongside a detection model for malware description.