 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-hop Reading Comprehension via Deep Reinforcement Learning based Document Traversal
May 23, 2019

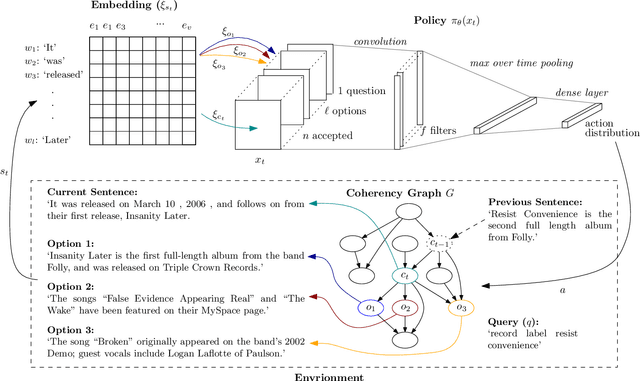

Reading Comprehension has received significant attention in recent years as high quality Question Answering (QA) datasets have become available. Despite state-of-the-art methods achieving strong overall accuracy, Multi-Hop (MH) reasoning remains particularly challenging. To address MH-QA specifically, we propose a Deep Reinforcement Learning based method capable of learning sequential reasoning across large collections of documents so as to pass a query-aware, fixed-size context subset to existing models for answer extraction. Our method is comprised of two stages: a linker, which decomposes the provided support documents into a graph of sentences, and an extractor, which learns where to look based on the current question and already-visited sentences. The result of the linker is a novel graph structure at the sentence level that preserves logical flow while still allowing rapid movement between documents. Importantly, we demonstrate that the sparsity of the resultant graph is invariant to context size. This translates to fewer decisions required from the Deep-RL trained extractor, allowing the system to scale effectively to large collections of documents. The importance of sequential decision making in the document traversal step is demonstrated by comparison to standard IE methods, and we additionally introduce a BM25-based IR baseline that retrieves documents relevant to the query only. We examine the integration of our method with existing models on the recently proposed QAngaroo benchmark and achieve consistent increases in accuracy across the board, as well as a 2-3x reduction in training time.