 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Guide for Evaluating LLMs and LLM-Reliant Systems
Jun 16, 2025Recent advances in generative AI have led to remarkable interest in using systems that rely on large language models (LLMs) for practical applications. However, meaningful evaluation of these systems in real-world scenarios comes with a distinct set of challenges, which are not well-addressed by synthetic benchmarks and de-facto metrics that are often seen in the literature. We present a practical evaluation framework which outlines how to proactively curate representative datasets, select meaningful evaluation metrics, and employ meaningful evaluation methodologies that integrate well with practical development and deployment of LLM-reliant systems that must adhere to real-world requirements and meet user-facing needs.
Cross-Subject Deep Transfer Models for Evoked Potentials in Brain-Computer Interface
Jan 29, 2023
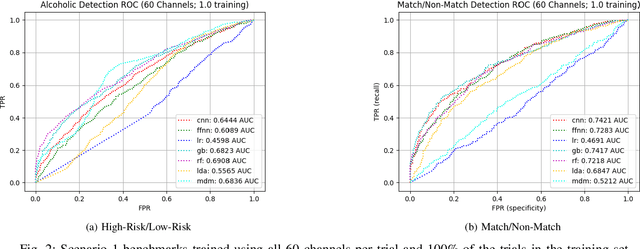
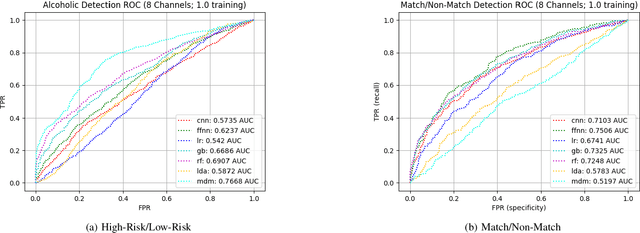
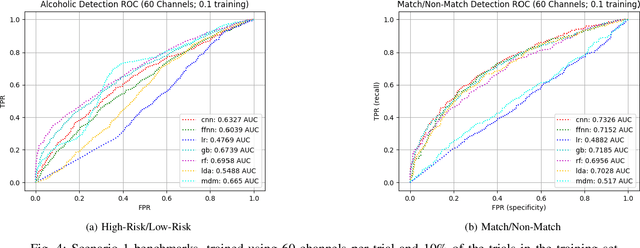
Brain Computer Interface (BCI) technologies have the potential to improve the lives of millions of people around the world, whether through assistive technologies or clinical diagnostic tools. Despite advancements in the field, however, at present consumer and clinical viability remains low. A key reason for this is that many of the existing BCI deployments require substantial data collection per end-user, which can be cumbersome, tedious, and error-prone to collect. We address this challenge via a deep learning model, which, when trained across sufficient data from multiple subjects, offers reasonable performance out-of-the-box, and can be customized to novel subjects via a transfer learning process. We demonstrate the fundamental viability of our approach by repurposing an older but well-curated electroencephalography (EEG) dataset and benchmarking against several common approaches/techniques. We then partition this dataset into a transfer learning benchmark and demonstrate that our approach significantly reduces data collection burden per-subject. This suggests that our model and methodology may yield improvements to BCI technologies and enhance their consumer/clinical viability.
Transformers for End-to-End InfoSec Tasks: A Feasibility Study
Dec 05, 2022In this paper, we assess the viability of transformer models in end-to-end InfoSec settings, in which no intermediate feature representations or processing steps occur outside the model. We implement transformer models for two distinct InfoSec data formats - specifically URLs and PE files - in a novel end-to-end approach, and explore a variety of architectural designs, training regimes, and experimental settings to determine the ingredients necessary for performant detection models. We show that in contrast to conventional transformers trained on more standard NLP-related tasks, our URL transformer model requires a different training approach to reach high performance levels. Specifically, we show that 1) pre-training on a massive corpus of unlabeled URL data for an auto-regressive task does not readily transfer to binary classification of malicious or benign URLs, but 2) that using an auxiliary auto-regressive loss improves performance when training from scratch. We introduce a method for mixed objective optimization, which dynamically balances contributions from both loss terms so that neither one of them dominates. We show that this method yields quantitative evaluation metrics comparable to that of several top-performing benchmark classifiers. Unlike URLs, binary executables contain longer and more distributed sequences of information-rich bytes. To accommodate such lengthy byte sequences, we introduce additional context length into the transformer by providing its self-attention layers with an adaptive span similar to Sukhbaatar et al. We demonstrate that this approach performs comparably to well-established malware detection models on benchmark PE file datasets, but also point out the need for further exploration into model improvements in scalability and compute efficiency.
* Post-print of a manuscript accepted to ACM Asia-CCS Workshop on Robust Malware Analysis (WoRMA) 2022. 11 Pages total. arXiv admin note: substantial text overlap with arXiv:2011.03040
Efficient Malware Analysis Using Metric Embeddings
Dec 05, 2022In this paper, we explore the use of metric learning to embed Windows PE files in a low-dimensional vector space for downstream use in a variety of applications, including malware detection, family classification, and malware attribute tagging. Specifically, we enrich labeling on malicious and benign PE files using computationally expensive, disassembly-based malicious capabilities. Using these capabilities, we derive several different types of metric embeddings utilizing an embedding neural network trained via contrastive loss, Spearman rank correlation, and combinations thereof. We then examine performance on a variety of transfer tasks performed on the EMBER and SOREL datasets, demonstrating that for several tasks, low-dimensional, computationally efficient metric embeddings maintain performance with little decay, which offers the potential to quickly retrain for a variety of transfer tasks at significantly reduced storage overhead. We conclude with an examination of practical considerations for the use of our proposed embedding approach, such as robustness to adversarial evasion and introduction of task-specific auxiliary objectives to improve performance on mission critical tasks.
Training Transformers for Information Security Tasks: A Case Study on Malicious URL Prediction
Nov 05, 2020
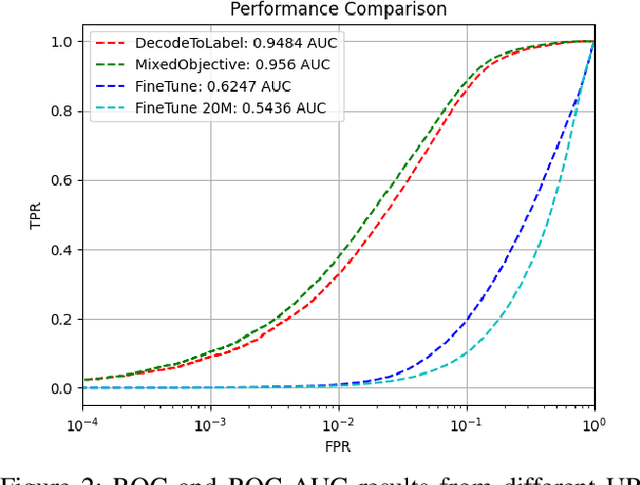
Machine Learning (ML) for information security (InfoSec) utilizes distinct data types and formats which require different treatments during optimization/training on raw data. In this paper, we implement a malicious/benign URL predictor based on a transformer architecture that is trained from scratch. We show that in contrast to conventional natural language processing (NLP) transformers, this model requires a different training approach to work well. Specifically, we show that 1) pre-training on a massive corpus of unlabeled URL data for an auto-regressive task does not readily transfer to malicious/benign prediction but 2) that using an auxiliary auto-regressive loss improves performance when training from scratch. We introduce a method for mixed objective optimization, which dynamically balances contributions from both loss terms so that neither one of them dominates. We show that this method yields performance comparable to that of several top-performing benchmark classifiers.
Learning from Context: Exploiting and Interpreting File Path Information for Better Malware Detection
May 16, 2019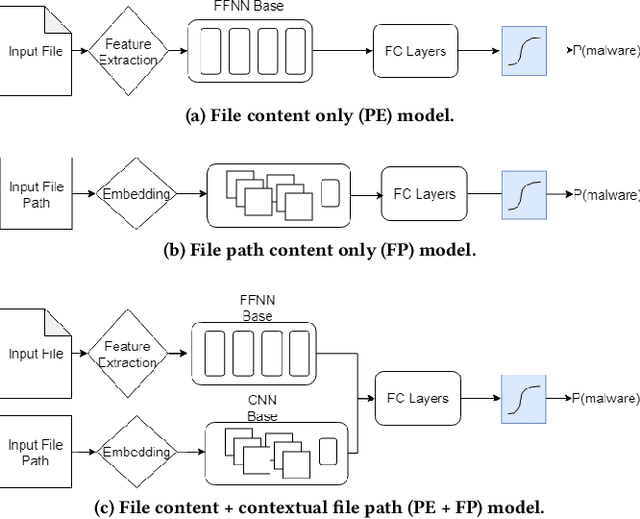

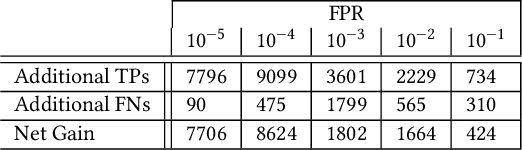
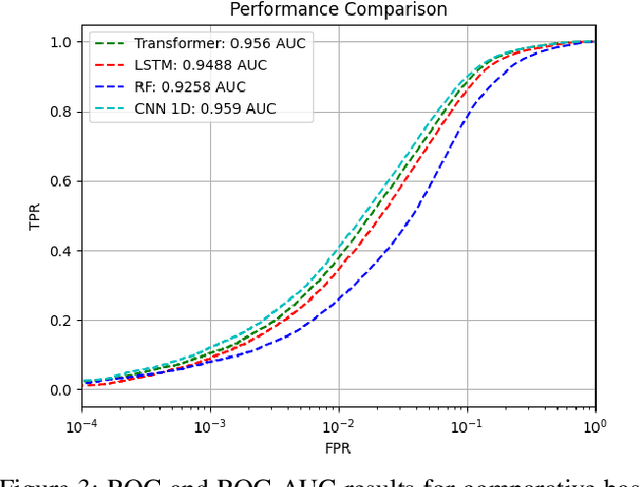
Machine learning (ML) used for static portable executable (PE) malware detection typically employs per-file numerical feature vector representations as input with one or more target labels during training. However, there is much orthogonal information that can be gleaned from the \textit{context} in which the file was seen. In this paper, we propose utilizing a static source of contextual information -- the path of the PE file -- as an auxiliary input to the classifier. While file paths are not malicious or benign in and of themselves, they do provide valuable context for a malicious/benign determination. Unlike dynamic contextual information, file paths are available with little overhead and can seamlessly be integrated into a multi-view static ML detector, yielding higher detection rates at very high throughput with minimal infrastructural changes. Here we propose a multi-view neural network, which takes feature vectors from PE file content as well as corresponding file paths as inputs and outputs a detection score. To ensure realistic evaluation, we use a dataset of approximately 10 million samples -- files and file paths from user endpoints of an actual security vendor network. We then conduct an interpretability analysis via LIME modeling to ensure that our classifier has learned a sensible representation and see which parts of the file path most contributed to change in the classifier's score. We find that our model learns useful aspects of the file path for classification, while also learning artifacts from customers testing the vendor's product, e.g., by downloading a directory of malware samples each named as their hash. We prune these artifacts from our test dataset and demonstrate reductions in false negative rate of 32.3% at a $10^{-3}$ false positive rate (FPR) and 33.1% at $10^{-4}$ FPR, over a similar topology single input PE file content only model.
SMART: Semantic Malware Attribute Relevance Tagging
May 15, 2019
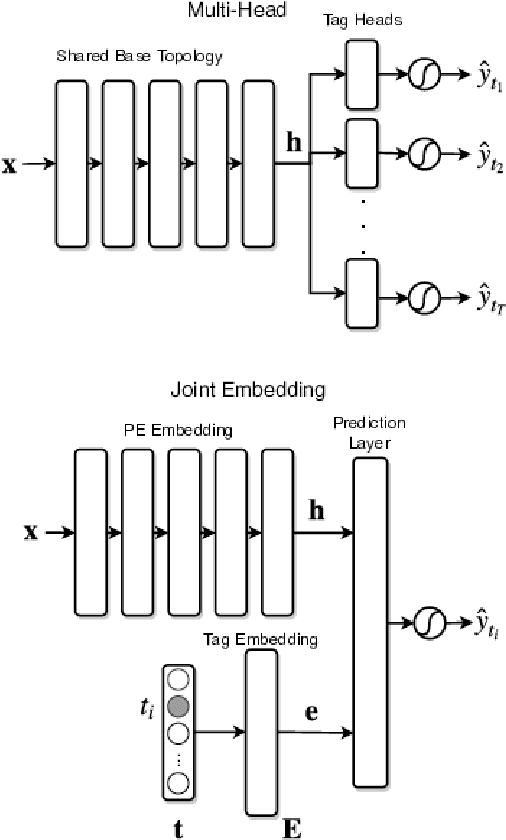

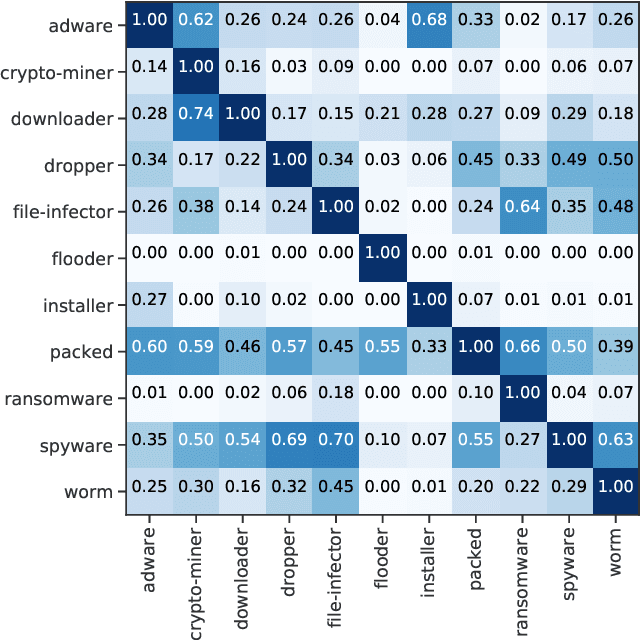
With the rapid proliferation and increased sophistication of malicious software (malware), detection methods no longer rely only on manually generated signatures but have also incorporated more general approaches like Machine Learning (ML) detection. Although powerful for conviction of malicious artifacts, these methods do not produce any further information about the type of malware that has been detected. In this work, we address the information gap between ML and signature-based detection methods by introducing an ML-based tagging model that generates human interpretable semantic descriptions of malicious software (e.g. file-infector, coin-miner), and argue that for less prevalent malware campaigns these provide potentially more useful and flexible information than malware family names. For this, we first introduce a method for deriving high-level descriptions of malware files from an ensemble of vendor family names. Then we formalize the problem of malware description as a tagging problem and propose a joint embedding deep neural network architecture that can learn to characterize portable executable (PE) files based on static analysis, thus not requiring a dynamic trace to identify behaviors at deployment time. We empirically demonstrate that when evaluated against tags extracted from an ensemble of anti-virus detection names, the proposed tagging model correctly identifies more than 93.7% of eleven possible tag descriptions for a given sample, at a deployable false positive rate (FPR) of 1% per tag. Furthermore, we show that when evaluating this model against ground truth tags derived from the results of dynamic analysis, it correctly predicts 93.5% of the labels for a given sample. These results suggest that an ML tagging model can be effectively deployed alongside a detection model for malware description.
ALOHA: Auxiliary Loss Optimization for Hypothesis Augmentation
Mar 13, 2019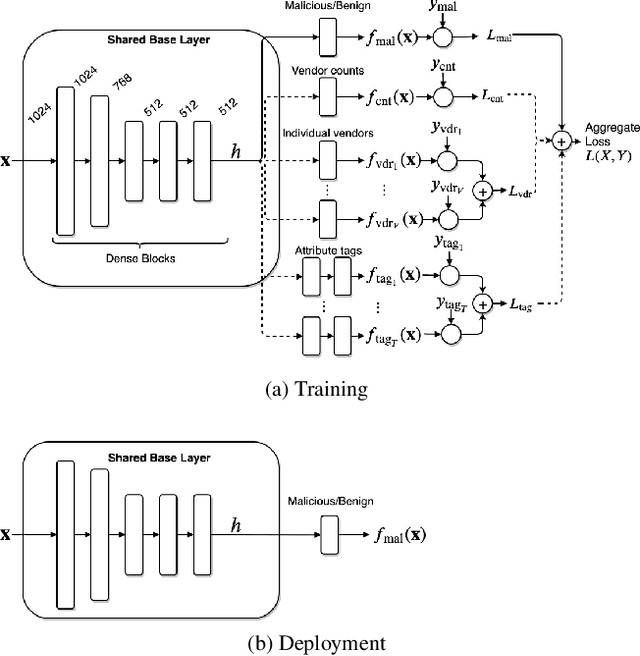
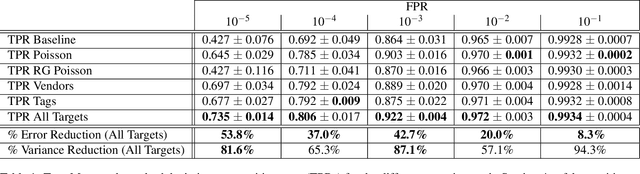
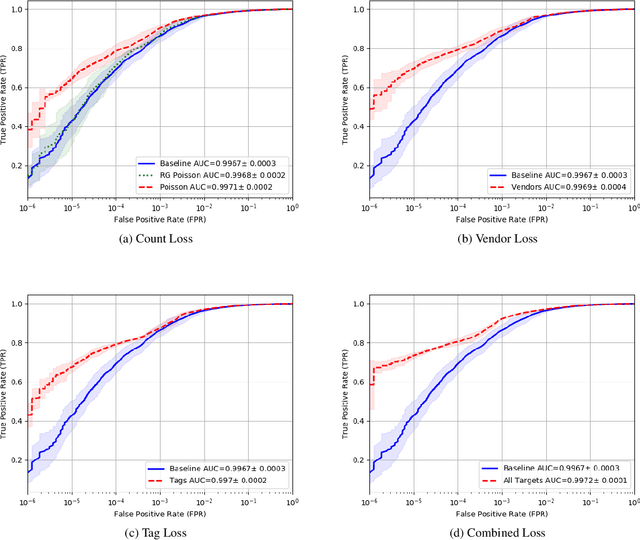
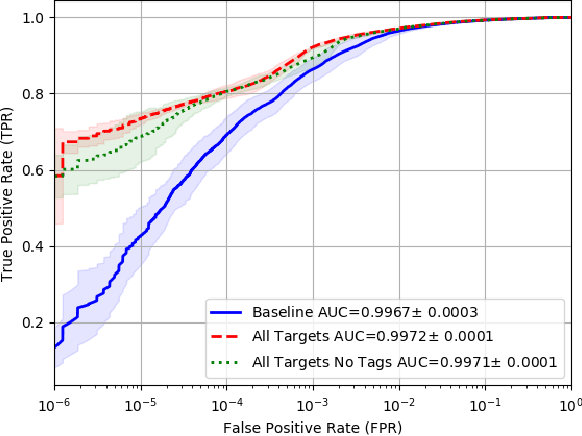
Malware detection is a popular application of Machine Learning for Information Security (ML-Sec), in which an ML classifier is trained to predict whether a given file is malware or benignware. Parameters of this classifier are typically optimized such that outputs from the model over a set of input samples most closely match the samples' true malicious/benign (1/0) target labels. However, there are often a number of other sources of contextual metadata for each malware sample, beyond an aggregate malicious/benign label, including multiple labeling sources and malware type information (e.g., ransomware, trojan, etc.), which we can feed to the classifier as auxiliary prediction targets. In this work, we fit deep neural networks to multiple additional targets derived from metadata in a threat intelligence feed for Portable Executable (PE) malware and benignware, including a multi-source malicious/benign loss, a count loss on multi-source detections, and a semantic malware attribute tag loss. We find that incorporating multiple auxiliary loss terms yields a marked improvement in performance on the main detection task. We also demonstrate that these gains likely stem from a more informed neural network representation and are not due to a regularization artifact of multi-target learning. Our auxiliary loss architecture yields a significant reduction in detection error rate (false negatives) of 42.6% at a false positive rate (FPR) of $10^{-3}$ when compared to a similar model with only one target, and a decrease of 53.8% at $10^{-5}$ FPR.
Principled Uncertainty Estimation for Deep Neural Networks
Oct 29, 2018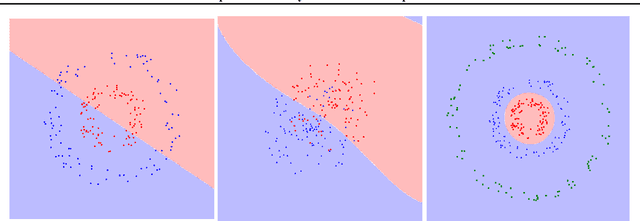
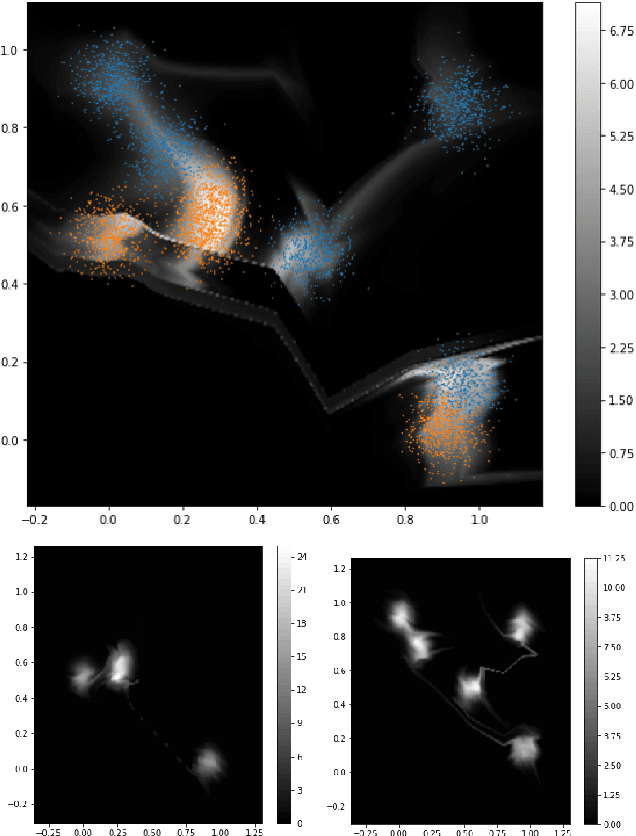
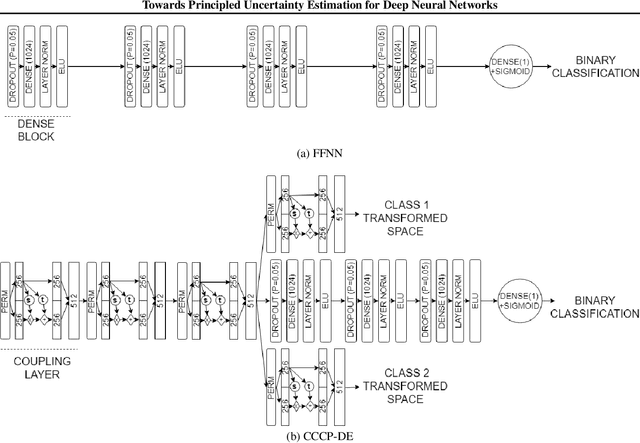

When the cost of misclassifying a sample is high, it is useful to have an accurate estimate of uncertainty in the prediction for that sample. There are also multiple types of uncertainty which are best estimated in different ways, for example, uncertainty that is intrinsic to the training set may be well-handled by a Bayesian approach, while uncertainty introduced by shifts between training and query distributions may be better-addressed by density/support estimation. In this paper, we examine three types of uncertainty: model capacity uncertainty, intrinsic data uncertainty, and open set uncertainty, and review techniques that have been derived to address each one. We then introduce a unified hierarchical model, which combines methods from Bayesian inference, invertible latent density inference, and discriminative classification in a single end-to-end deep neural network topology to yield efficient per-sample uncertainty estimation. Our approach addresses all three uncertainty types and readily accommodates prior/base rates for binary detection.
Facial Attributes: Accuracy and Adversarial Robustness
Apr 20, 2018



Facial attributes, emerging soft biometrics, must be automatically and reliably extracted from images in order to be usable in stand-alone systems. While recent methods extract facial attributes using deep neural networks (DNNs) trained on labeled facial attribute data, the robustness of deep attribute representations has not been evaluated. In this paper, we examine the representational stability of several approaches that recently advanced the state of the art on the CelebA benchmark by generating adversarial examples formed by adding small, non-random perturbations to inputs yielding altered classifications. We show that our fast flipping attribute (FFA) technique generates more adversarial examples than traditional algorithms, and that the adversarial robustness of DNNs varies highly between facial attributes. We also test the correlation of facial attributes and find that only for related attributes do the formed adversarial perturbations change the classification of others. Finally, we introduce the concept of natural adversarial samples, i.e., misclassified images where predictions can be corrected via small perturbations. We demonstrate that natural adversarial samples commonly occur and show that many of these images remain misclassified even with additional training epochs, even though their correct classification may require only a small adjustment to network parameters.
* arXiv admin note: text overlap with arXiv:1605.05411